Apache Spark je nástroj pro analýzu dat, který lze použít ke zpracování dat z HDFS, S3 nebo jiných zdrojů dat v paměti. V tomto příspěvku nainstalujeme Apache Spark na počítač Ubuntu 17.10.
Ubuntu verze
pro tuto příručku použijeme Ubuntu verze 17.10 (GNU / Linux 4.13.0-38-generic x86_64).
Apache Spark je součástí ekosystému Hadoop pro velká Data. Zkuste nainstalovat Apache Hadoop a vytvořte s ním ukázkovou aplikaci.
aktualizace stávajících balíčků
Chcete-li spustit instalaci pro Spark, je nutné aktualizovat náš stroj nejnovějšími dostupnými softwarovými balíčky. Můžeme to udělat s:
protože Spark je založen na Javě, musíme jej nainstalovat na náš počítač. Můžeme použít libovolnou verzi Java nad Java 6. Zde budeme používat Javu 8:
stahování souborů Spark
všechny potřebné balíčky nyní existují na našem počítači. Jsme připraveni stáhnout požadované soubory Spark TAR, abychom je mohli začít nastavovat a spustit ukázkový program také se Spark.
v této příručce Budeme instalovat Spark v2. 3. 0 k dispozici zde:

Stránka ke stažení Spark
stáhněte odpovídající soubory tímto příkazem:
v závislosti na rychlosti sítě To může trvat až několik minut, protože soubor je velký:
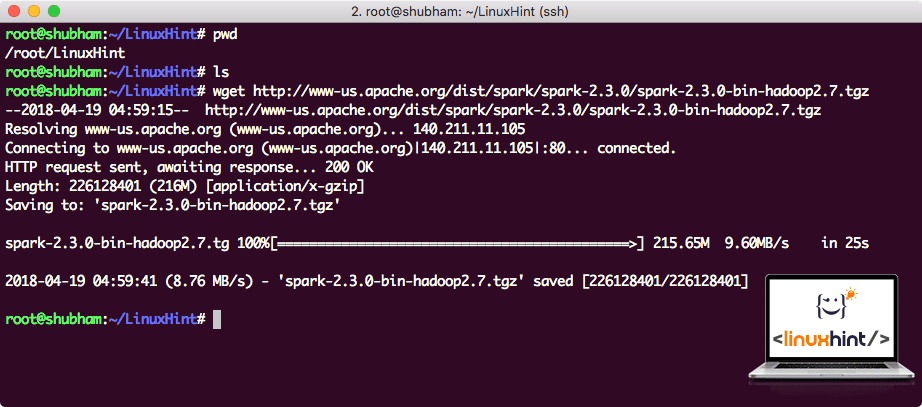
stahování Apache Spark
Nyní, když máme stažený soubor TAR, můžeme extrahovat v aktuálním adresáři:
dokončení bude trvat několik sekund kvůli velké velikosti souboru archivu:

Unarchived files in Spark
pokud jde o upgrade Apache Spark v budoucnu, může to způsobit problémy kvůli aktualizacím cesty. Tyto problémy lze vyhnout vytvořením softlink Spark. Spusťte tento příkaz a vytvořte softlink:
přidání Spark na cestu
Chcete-li spustit Spark skripty, přidáme ji do cesty nyní. Chcete-li to provést, otevřete soubor bashrc:
přidejte tyto řádky na konec .bashrc soubor tak, aby cesta může obsahovat Spark spustitelný soubor cestu:
export PATH=$SPARK_HOME / bin:$PATH
nyní soubor vypadá:

přidání jiskry do cesty
Chcete-li tyto změny aktivovat, spusťte následující příkaz pro soubor bashrc:
spuštění Spark Shell
Nyní, když jsme přímo mimo adresář spark, spusťte následující příkaz k otevření apark shell:
uvidíme, že Spark shell je nyní openend:

spuštění Spark shell
v konzole vidíme, že Spark také otevřel webovou konzoli na portu 404. Pojďme to navštívit:

Apache Spark Web Console
ačkoli budeme pracovat na samotné konzoli, webové prostředí je důležitým místem, na které se můžete podívat, když provádíte těžké úlohy Spark, abyste věděli, co se děje v každé vykonávané úloze Spark.
Zkontrolujte verzi Spark shell jednoduchým příkazem:
dostaneme zpět něco jako:
vytvoření ukázkové aplikace Spark s Scala
nyní vytvoříme ukázkovou aplikaci Word Counter s Apache Spark. Chcete-li to provést, nejprve načtěte textový soubor do kontextu Spark na Spark shell:
Data: org.Apač.jiskra.rdd.RDD = / root/LinuxHint/spark / README.md MapPartitionsRDD at textový soubor at :24
scala>
nyní musí být text přítomný v souboru rozdělen na žetony, které Spark dokáže spravovat:
tokeny: org.Apač.jiskra.rdd.RDD = MapPartitionsRDD at flatMap at: 25
scala>
nyní inicializujte Počet pro každé slovo 1:
tokens_1: org.Apač.jiskra.rdd.RDD = MapPartitionsRDD at mapa at: 25
scala>
nakonec Vypočítejte frekvenci každého slova souboru:
je čas podívat se na výstup programu. Sbírejte žetony a jejich příslušné počty:
res1: Array = Array((balíček,1), (Pro,3), (Programy,1), (zpracování.,1), (protože, 1), (den, 1), (strana](http://spark.apache.org/documentation.html).,1), (cluster.,1), (its,1), ([běh,1), (než,1), (API,1), (mít,1), (Try,1), (výpočet,1), (přes,1), (Několik,1), (Toto,2), (graf,1), (úl,2), (skladování,1), ([„upřesnění,1), (na,2), („příze“,1), (jednou,1), ([„Užitečné,1), (přednost,1), (sparkpi,2), (motor,1), (Verze,1), (soubor,1), (dokumentace,,1), (zpracování,,1), (os,24), (jsou,1), (systémy.,1), (params, 1), (ne, 1), (odlišný, 1), (viz, 2), (Interaktivní, 2), (R,, 1), (daný.,1), (Pokud, 4), (stavět, 4), (Když, 1), (Být, 2), (testy,1), (Apache,1), (vlákno,1), (programy,,1), (počítaje v to,4), (./ bin / run-příklad, 2), (Spark.,1), (balíček.,1), (1000).počet (), 1), (Verze, 1), (HDFS, 1), (D…
scala>
výborně! Podařilo se nám spustit jednoduchý příklad čítače slov pomocí programovacího jazyka Scala s textovým souborem, který je již v systému přítomen.
závěr
v této lekci jsme se podívali na to, jak můžeme nainstalovat a začít používat Apache Spark na počítači Ubuntu 17.10 a spustit na něm také ukázkovou aplikaci.
Přečtěte si více příspěvků založených na Ubuntu zde.