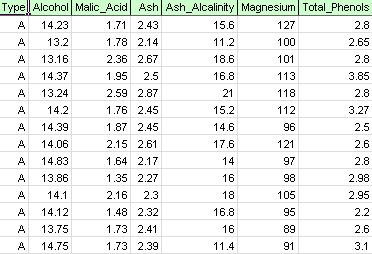
na pásu karet XLMiner na kartě použití modelu vyberte Help – Examples, poté Forecasting / Data Mining Examples a otevřete ukázkový soubor Wine.xlsx. Jak je znázorněno na obrázku níže, každý řádek v tomto příkladném souboru dat představuje vzorek vína odebraný z jednoho ze tří vinařství (A, B nebo C). V tomto příkladu je proměnná typu reprezentující vinařství ignorována a shlukování se provádí jednoduše na základě vlastností vzorků vína (zbývající proměnné).
vyberte buňku v datové sadě a poté na pásu karet XLMiner na kartě Analýza dat vyberte XLMiner-Cluster-K-Means Clustering a otevřete dialog K-Means Clustering Step 1 of 3.
ze seznamu proměnných vyberte všechny proměnné kromě typu a kliknutím na tlačítko > přesuňte vybrané proměnné do seznamu vybraných proměnných.
klepněte na tlačítko Další pro přechod na Krok 2 of 3 dialog.
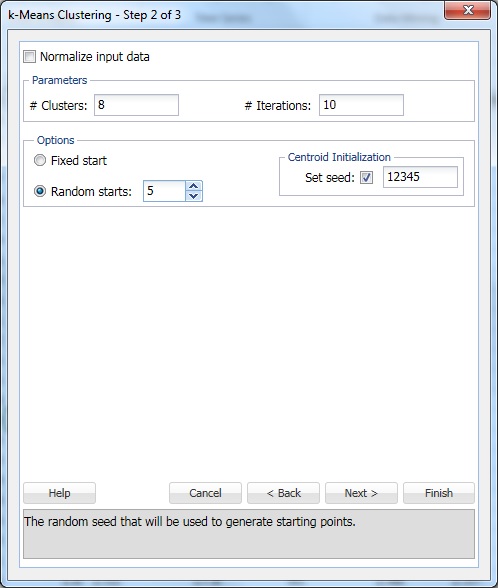
v # Clusters zadejte 8. Toto je parametr k v algoritmu shlukování K-znamená. Počet shluků by měl být alespoň 1 a maximálně počet pozorování -1 v datovém rozsahu. Nastavte k na několik různých hodnot a vyhodnoťte výstup z každé.
ponechte # iterace ve výchozím nastavení 10. Hodnota této možnosti určuje, kolikrát se program spustí s počátečním oddílem a dokončí algoritmus shlukování. Konfigurace klastrů (a oddělení dat) se může lišit od jednoho počátečního oddílu k druhému. Program projde zadaným počtem iterací a vybere konfiguraci clusteru, která minimalizuje míru vzdálenosti.
nastavit náhodné začíná na 5. Když je tato volba vybrána, algoritmus začne vytvářet model z libovolného náhodného bodu. XLMiner generuje pět clusterových sad a generuje výstup na základě nejlepšího clusteru.
Set seed je ve výchozím nastavení vybrán. Tato volba inicializuje generátor náhodných čísel, který se používá k výpočtu počátečních centroidů clusteru. Nastavení semene náhodných čísel na nenulovou hodnotu (Výchozí 12345) zajišťuje, že při každém výpočtu počátečních centroidů clusteru se použije stejná posloupnost náhodných čísel. Když je semeno nulové, generátor náhodných čísel je inicializován ze systémových hodin, takže sekvence náhodných čísel se liší pokaždé, když jsou centroidy inicializovány. Nastavte semeno tak, aby zobrazovalo postupné běhy metody shlukování jako srovnatelné.
pro normalizaci dat vyberte možnost normalizovat vstupní data. V tomto příkladu nebudou data normalizována. Výběrem možnosti další otevřete dialog Krok 3 z 3.
vyberte Zobrazit souhrn dat (výchozí) a zobrazit vzdálenosti od každého centra clusteru (výchozí) a potom klepněte na tlačítko Dokončit.
metoda shlukování K-Means začíná počátečními klastry k, jak je uvedeno. Při každé iteraci jsou záznamy přiřazeny clusteru s nejbližším těžištěm nebo středem. Po každé iteraci se vypočítá vzdálenost od každého záznamu ke středu clusteru. Tyto dva kroky se opakují (přiřazení záznamu a výpočet vzdálenosti), dokud přerozdělení záznamu nevede ke zvýšené hodnotě vzdálenosti.
když je zadán náhodný start, algoritmus generuje náhodně centra klastru k a odpovídá datovým bodům v těchto klastrech. Tento proces se opakuje pro všechny zadané náhodné starty. Výstup je založen na shlucích, které se nejlépe hodí.
pracovní list KM_Output1 je vložen okamžitě napravo od datového listu. V horní části výstupního listu jsou uvedeny vybrané možnosti.
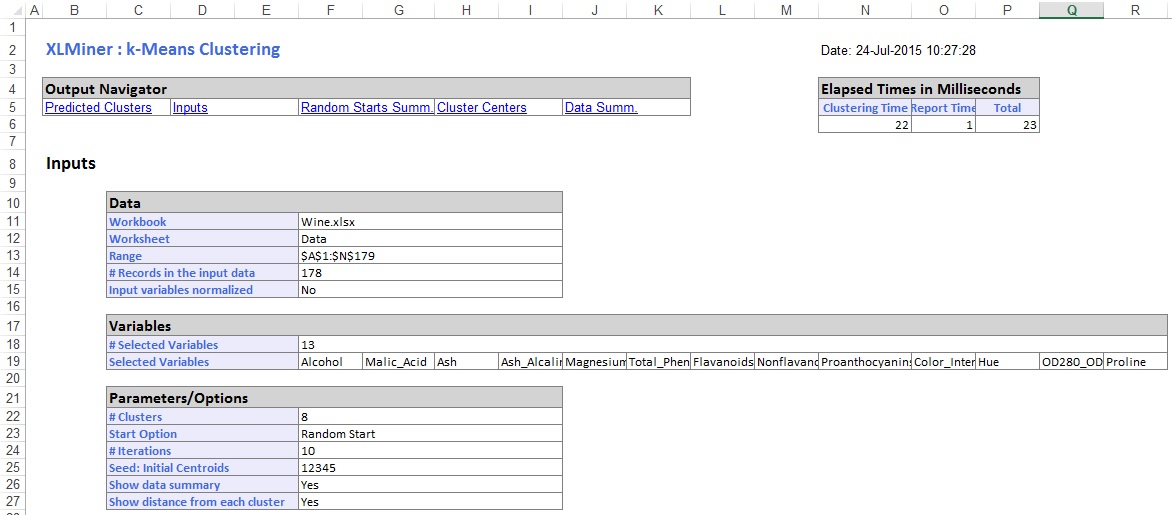
ve střední části výstupního listu xlminer vypočítal součet čtvercových vzdáleností a určil začátek s nejnižším součtem čtvercové vzdálenosti jako nejlepší Start (#5). Po určení nejlepšího startu vygeneruje XLMiner zbývající výstup pomocí nejlepšího startu jako výchozího bodu.
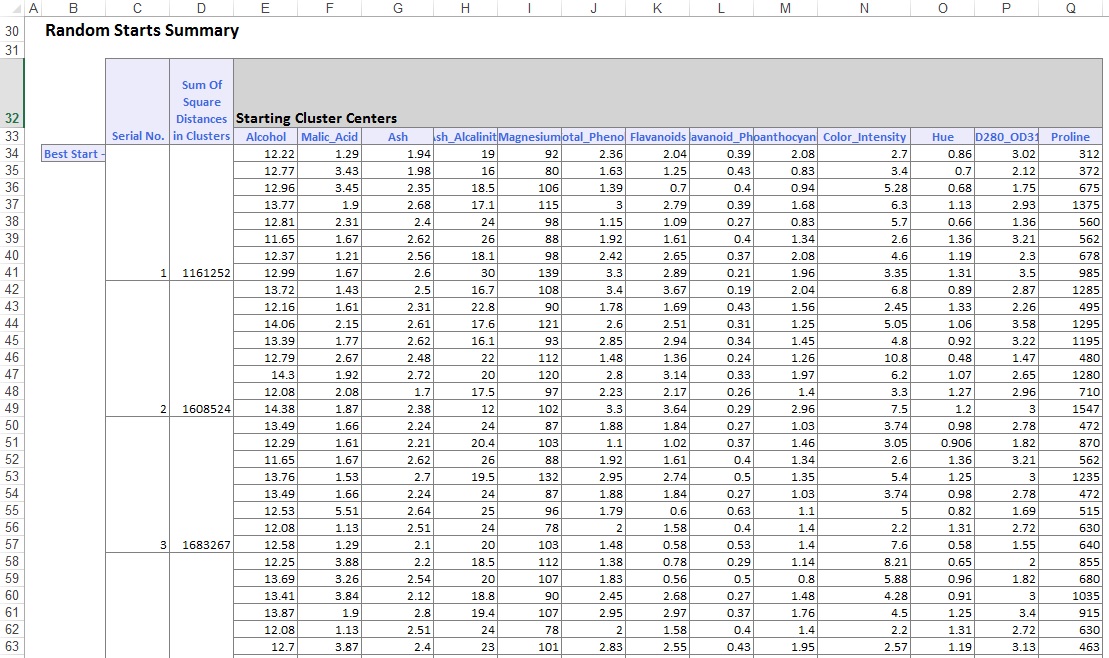
ve spodní části výstupního listu XLMiner uvedl centra clusteru (viz níže). Horní pole zobrazuje hodnoty proměnných ve středech clusteru. Cluster 8 má nejvyšší průměrný obsah alkoholu, Total_fenolů, flavanoidů, Proanthokyaninů, Color_Intensity, Hue a prolinu. Porovnejte tento cluster s clusterem 2, který má nejvyšší průměrnou Ash_alcalinitu a Neflavanoid_fenoly.
dolní pole zobrazuje vzdálenost mezi středy clusteru. Z hodnot v této tabulce je určeno, že Cluster 3 je velmi odlišný od clusteru 8 kvůli vysoké hodnotě vzdálenosti 1 176, 59 a Cluster 7 je blízko clusteru 3 s nízkou hodnotou vzdálenosti 89,73.
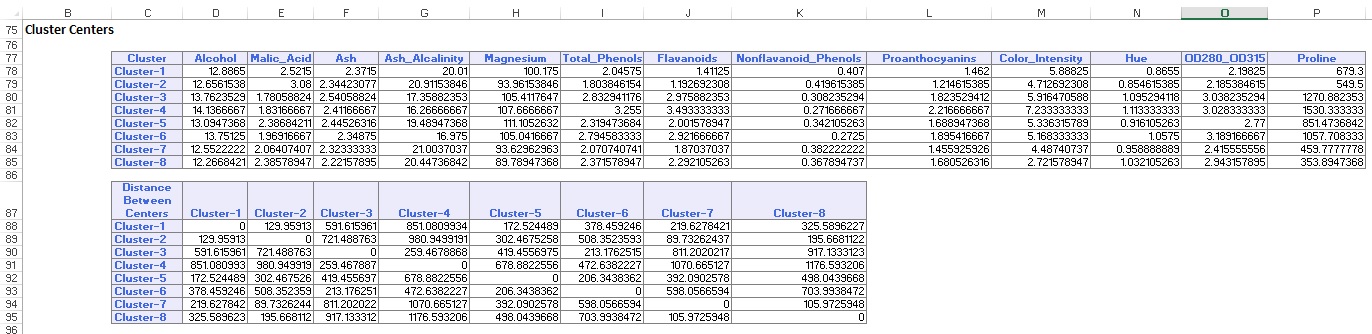
souhrn údajů (níže) zobrazuje počet záznamů (pozorování) zahrnutých v každém clusteru a průměrnou vzdálenost od členů clusteru ke středu každého clusteru. Cluster 6 má nejvyšší průměrnou vzdálenost 42.79 a zahrnuje 24 záznamů. Porovnejte tento cluster s clusterem 2, který má nejmenší průměrnou vzdálenost 29,66 a zahrnuje 26 členů.
klikněte na pracovní list KM_Clusters1. Tento list zobrazuje cluster, ke kterému je každý záznam přiřazen, a vzdálenost ke každému clusteru. Pro první záznam je vzdálenost ke clusteru 6 minimální vzdálenost 23.205, takže tento první záznam je přiřazen clusteru 6.