začneme tím, že se podíváme na duální lineární / ridge regresi, než ukážeme, jak ji „kernelizovat“. Při vysvětlování toho druhého uvidíme, co jsou jádra a co je „trik jádra“.
Dvouformová Ridge regrese
lineární regrese je v ní typicky dána jako lineární kombinace sloupců (znaků). Existuje však druhá, duální Forma, kde se jedná o lineární kombinaci vnitřního produktu nového data (na kterém provádíme závěr) s každým z tréninkových dat.
uvažujeme případ regrese hřebene (L2 regularized linear regression), přičemž si pamatujeme, že základní lineární regrese odpovídá případu, kdy \(\lambda = 0\). Pak vzorce pro regresi hřebene, kde \(X\) a \(Y\) odkazují na \(n \times m\) tréninková data a \(x^ \ prime, y^\prime\) nový případ, který má být odhadnut, jsou:
\ \ \ \
kde \(\langle X_i, x^\prime \ rangle\) je vnitřní / bodový součin, takže \(\langle X_i, x^\prime \ rangle = X^T_i x^\prime = \ sum_j^m X_{i, j} x^\prime_j\).
duální forma ukazuje, že lineární / hřebenová regrese může být také chápána jako poskytnutí odhadu váženého součtu vnitřního produktu nového případu s každým z tréninkových případů.
to znamená, že můžeme udělat lineární regresi, i když existuje více sloupců než řádků, i když význam tohoto může být nadhodnocen, protože (i) to můžeme udělat stejně pomocí L2 regularizace, protože to vždy dělá \(X^TX\) matici invertovatelnou; a (ii) matice \(XX^T\) může často vyžadovat L2 regularizaci, aby byla zajištěna numerická stabilita inverze. Umožňuje nám také zobrazit lineární regresi jako mnohem více sekvenčního procesu učení, kde každý další údaj v tréninkových datech přináší něco nového.
pro naše účely je však nejdůležitější, že duální forma má zajímavou charakteristiku: vektory funkcí se vyskytují v rovnicích pouze uvnitř vnitřních produktů. To platí i v definici \(\alpha\), protože \(XX^T\) vytváří matici odpovídající vnitřním produktům každé dvojice vektorů funkcí v tréninkových datech. Jak budeme postupovat, uvidíme, jak je to důležité.
stranou: zájemci mohou vidět, jak byla duální forma odvozena v odvození duálního formuláře dokumentu dostupného v sekci Ke stažení na konci tohoto článku.
nelineární regrese duálního hřebene
můžeme naši regresi duálního tvaru ridge přeměnit na nelineární model standardní metodou použití nelineárních transformací prvků \(\phi\):
\ \
funkce jádra
funkce jádra, \(K: \ mathcal X \ times \ mathcal X \ to \mathbb{R}\), je funkce,která je symetrická – \(k(x_1,x_2)=k(x_2, x_1)\) – a pozitivní definitivní (viz stranou pro formální definici). Pozitivní definitivita se používá v matematice, která ospravedlňuje použití jader. Ale bez významných matematických znalostí není definice intuitivně osvětlující. Takže spíše než se pokoušet porozumět jádrům z definice pozitivní definitivity, představíme je s řadou příkladů.
než to uděláme, poznamenáváme, že ačkoli jádra jsou funkce se dvěma argumenty, je běžné myslet na ně jako na jejich prvním argumentu a na funkci jejich druhého. Podle této interpretace uvidíte notaci jako \(K_x (y)\), která je ekvivalentní \(k (x, y)\) . Zejména budeme často myslet na to, že jádra jsou funkce s jedním argumentem „umístěné“ v datových bodech (vektory funkcí) v našich tréninkových datech. Někdy se dočtete o nás „klesá“ jádra na datových bodech. Pokud tedy máme vektor funkcí \(x_i\), spustili bychom na něj jádro, což by vedlo k funkci \(k_{x_i} (x)\) umístěné na \(x_i\) a ekvivalentní \(k (x_i, x)\).
také si všimneme, že jádra jsou často specifikována jako členové parametrických rodin. Příklady takových rodin jádra zahrnují:
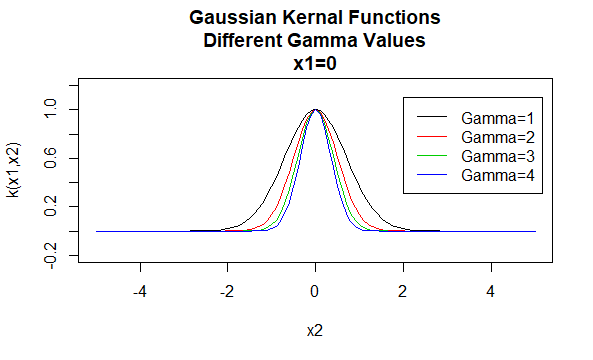
Gaussova jádra
Gaussova jádra jsou příkladem radiálních základních funkčních jader a někdy se nazývají radiální základní jádra. Hodnota jádra radiální bazické funkce závisí pouze na vzdálenosti mezi vektory argumentů, spíše než na jejich umístění. Taková jádra se také nazývají stacionární.
parametry: \(\gamma\)
tvar rovnice: \(k (X_1, X_2)=e^{- \gamma \ / X_1-X_2 \|^2}\)
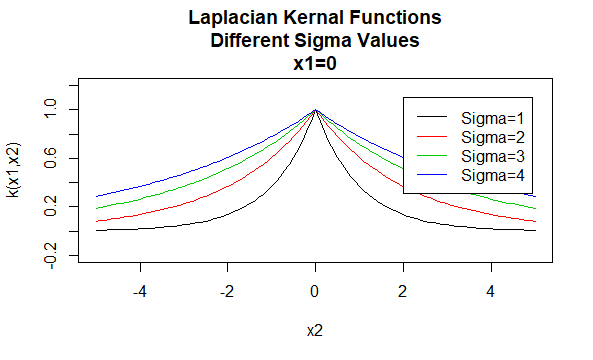
Laplacian jádra
Laplacian jádra jsou také radiální základní funkce.
parametry: \(\sigma\)
tvar rovnice: \(K (X_1,X_2)=e^{-\frac{\| X_1 – X_2 \|}{\sigma}}\)
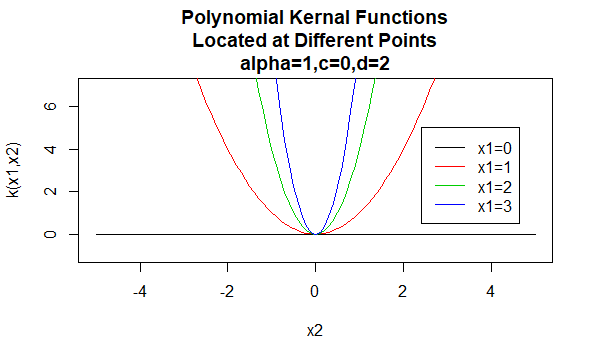
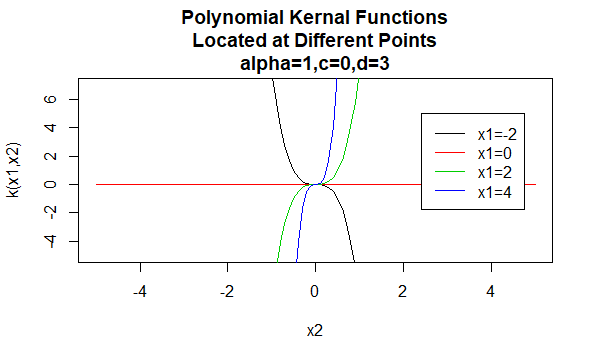
polynomiální jádra
polynomiální jádra jsou příkladem nestacionárních jader. Takže tato jádra přiřadí různé hodnoty dvojicím bodů, které sdílejí stejnou vzdálenost, na základě jejich hodnot. Hodnoty parametrů musí být nezáporné, aby se zajistilo, že tato jádra jsou kladná.
parametry: \(\alpha, c, d\)
forma rovnice: \(k(X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
zadání konkrétních hodnot pro parametry rodiny jádra má za následek funkci jádra. Níže jsou uvedeny příklady funkcí jader z výše uvedených rodin s konkrétními hodnotami parametrů umístěnými v různých bodech (tj. vynesený graf je funkcí druhého argumentu, přičemž první argument je nastaven na určitou hodnotu).
Stranou: Zájemci mohou vidět definici pozitivní definitivity pro jádra v dokumentu jádra a pozitivní Definitivita, který je k dispozici v sekci Ke stažení na konci tohoto článku.
trik jádra
význam funkcí jádra pochází z velmi zvláštní vlastnosti: Každé kladné definitivní jádro, \(k\) souvisí s matematickým prostorem, \(\mathcal{H}_K\), (známé jako reprodukční Hilbertův prostor jádra (RKHS) jádra) tak, že použití \(k\) na dva vektory prvků, \(X_1, X_2\) je ekvivalentní promítání těchto vektorů prvků do \(\mathcal{H}_K\) nějakou projekční funkcí, \(\phi\) a jejich vnitřní součin tam:
\
Rkhss spojené s jádry jsou obvykle vysoce dimenzionální. Pro některá jádra, jako jsou jádra Gaussovy rodiny, jsou nekonečně dimenzionální.
výše uvedené je základem slavného „triku jádra“: pokud jsou vstupní prvky zapojeny do rovnice statistického modelu pouze ve formě vnitřních produktů, můžeme nahradit vnitřní produkty v rovnici voláním do funkce jádra a výsledek je, jako bychom promítli vstupní prvky do vyššího rozměrového prostoru (tj. provedli transformaci prvků vedoucí k velkému počtu latentních proměnných prvků) a vzali tam jejich vnitřní produkt. Ale nikdy nepotřebujeme provést skutečnou projekci.
v terminologii strojového učení jsou RKHS spojené s jádrem známé jako prostor funkcí, na rozdíl od vstupního prostoru. Pomocí triku jádra implicitně promítneme vstupní prvky do tohoto prostoru a vezmeme tam jejich vnitřní produkt.
regrese jádra
to vede k technice známé jako regrese jádra. Jedná se jednoduše o aplikaci triku jádra na duální formu ridge regrese. Pro usnadnění představíme myšlenku jádra, nebo Gram, matrix, \(k\), takové, že \(k_{i, j}=K (X_i,X_j)\). Pak můžeme napsat rovnice pro regresi jádra jako:
\ \
kde \(k\) Je nějaká kladně definovaná funkce jádra.
Representerova věta
zvažte optimalizační problém, který se snažíme vyřešit při provádění regularizace L2 pro model nějaké formy, \(f\):
\
při provádění regrese jádra s jádrem \(k\) je důležitým výsledkem teorie regularizace, že minimalizátor výše uvedené rovnice bude mít tvar:
\
s \(\alpha\) vypočteno, jak je popsáno výše.
Toto je spravedlivě lionizovaná reprezentační věta. Slovy se říká, že minimalizátor optimalizačního problému pro lineární regresi v implicitním prostoru prvků získaném konkrétním jádrem (a tedy minimalizátor nelineárního regresního problému jádra) bude dán váženým součtem jader „umístěných“ v každém vektoru prvků.
k tomuto tématu je toho mnohem více. Můžeme dokonce zjistit, jaká Zelená funkce (jejíž jádra jsou podmnožinou) minimalizuje konkrétní specifikace regularizace, jako je regularizace L2, ale také jakákoli penalizace založená na lineárním diferenciálním operátoru. Tento vztah mezi jádry a optimálními řešeními Tikhonovových regularizačních problémů je zásadním důvodem důležitosti metod jádra ve strojovém učení. Ale matematika je zde za tímto kurzem a zainteresovaní pokročilí studenti jsou odkázáni na sedmou kapitolu Haykinových neuronových sítí a učebních strojů.
to nám dává matematické zdůvodnění pro použití regrese jádra v případech, kdy je to možné. Ve skutečnosti vypracování optimálního jádra pro použití obvykle není možné-vyžaduje znalost optimálního lineárního diferenciálního operátora, který má být použit pro regularizační trest. Byly vypočteny funkce, které bychom měli promítnout do optimalizace konkrétních regularizačních sankcí, a víme například, že jádro spline s tenkými deskami je optimální pro regularizaci L2. Na druhou stranu, protože musíme vypočítat Gram matici, regrese jádra není dobře škálovatelná – pro velké datové sady je lepší obrátit se na neuronové sítě.