vi begynder med at se på dual-form lineær/ridge regression, før vi viser, hvordan man ‘kerneliserer’ det. Når vi forklarer sidstnævnte, vil vi se, hvad kerner er, og hvad ‘kernel trick’ er.
Dual-form Ridge Regression
lineær regression er typisk givet i den primære form som en lineær kombination af kolonner (funktioner). Der findes dog en anden, dobbelt form, hvor det er en lineær kombination af det indre produkt af et nyt datum (som vi udfører slutning på) med hver af træningsdataene.
vi overvejer tilfældet med højderygregression (L2 reguleret lineær regression), idet vi husker, at grundlæggende lineær regression svarer til det tilfælde, hvor \(\lambda = 0\). Derefter henviser formlerne til højderygregression, hvor \(H\) og \(Y\) henviser til\ (n \ gange m\) træningsdata og\(H^\prime,y^\ prime\) en ny sag, der skal estimeres, er:
\ \ \ \
hvor \(\prime\rangle\) er det indre/prikprodukt,så\ (\langle ‘S_i, \\prime \rangle = \’ s^\prime = \sum_j^m ‘S_{i,j}’ s^\prime_j\).
den dobbelte form viser, at lineær/højderygregression også kan forstås som et skøn over en vægtet sum af det indre produkt af en ny sag med hver af træningssagerne.
det betyder, at vi kan gøre lineær regression, selv når der er flere kolonner end rækker, selvom vigtigheden af dette kan overvurderes, da (i) Vi kan gøre dette alligevel via brug af L2-regulering, da dette altid gør matricen inverterbar; og(ii) matricen kan ofte kræve L2-regulering alligevel for at sikre numerisk stabilitet for inversionen. Det giver os også mulighed for at se lineær regression som meget mere af en sekventiel læringsproces, hvor hvert yderligere datum i træningsdataene bringer noget nyt.
vigtigst for vores formål har den dobbelte form dog den interessante egenskab: funktionsvektorer forekommer kun i ligningerne inde i indre produkter. Dette gælder selv i definitionen af \ (\alpha\), som\ (\^T\) producerer matricen svarende til de indre produkter af hvert par funktionsvektorer i træningsdataene. Vi vil se vigtigheden af dette, når vi fortsætter.
bortset fra: interesserede studerende kan se, hvordan dobbeltformularen blev afledt i afledningen af Dobbeltformulardokument, der er tilgængeligt i afsnittet overførsler i slutningen af denne artikel.
ikke-lineær Dual Ridge Regression
vi kan gøre vores dual form ridge regression til en ikke-lineær model ved standardmetoden til anvendelse af en ikke-lineær funktionstransformationer \(\phi\):
\ \
kernefunktioner
en kernefunktion, \(K: \mathcal \gange \mathcal \til\ mathbb{R}\), er en funktion,der er symmetrisk – \ (K(H_1,h_2)=K(h_2, H_1)\) – og positiv bestemt (se til side for en formel definition). Positiv-definiteness bruges i matematikken, der retfærdiggør brugen af kerner. Men uden væsentlig matematisk viden er definitionen ikke intuitivt lysende. Så i stedet for at forsøge at forstå kerner fra definitionen af positiv-definiteness, vil vi introducere dem med en række eksempler.
før vi gør dette, bemærker vi, at selvom kerner er to-argumentfunktioner, er det almindeligt at tænke på dem som værende placeret ved deres første argument og være en funktion af deres andet. I henhold til denne fortolkning vil du se notation som \(K_k(y)\), hvilket svarer til \(K(H,y)\) . Især vil vi ofte tænke på, at kerner er enkeltargumentfunktioner ‘placeret’ på datapunkter (funktionsvektorer) i vores træningsdata. Nogle gange vil du læse om os ‘droppe’ kerner på datapunkter. Så hvis vi har en funktionsvektor \(h_i\), ville vi slippe en kerne på den,hvilket fører til funktionen \(K_{h_i}(h)\) placeret på \(h_i\) og svarende til \(K(h_i, h)\).
vi bemærker også, at kerner ofte er specificeret som medlemmer af parametriske familier. Eksempler på sådanne kernefamilier inkluderer:
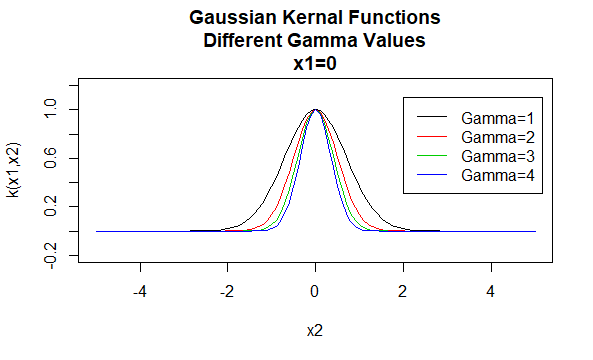
gaussiske kerner
gaussiske kerner er et eksempel på radiale basisfunktionskerner og kaldes undertiden radiale basiskerner. Værdien af en radial basisfunktion kerne afhænger kun af afstanden mellem argumentvektorerne, snarere end deres placering. Sådanne kerner kaldes også stationære.
parametre: \(\gamma\)
Ligningsform: \(K (H_1, H_2)=e^{- \gamma \ / H_1-H_2 \|^2}\)
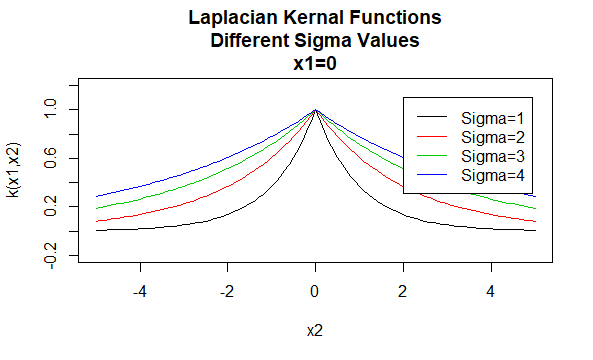
Laplacian kerner
Laplacian kerner er også radiale basisfunktioner.
parametre: \(\sigma\)
Ligningsformular: \(K (H_1, H_2)=e^{-\frac{\| H_1 – H_2 \|}{\sigma}}\)
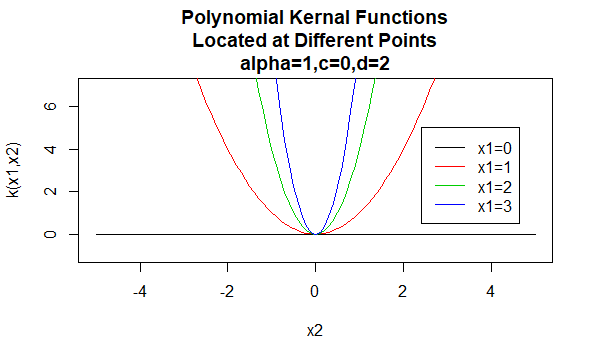
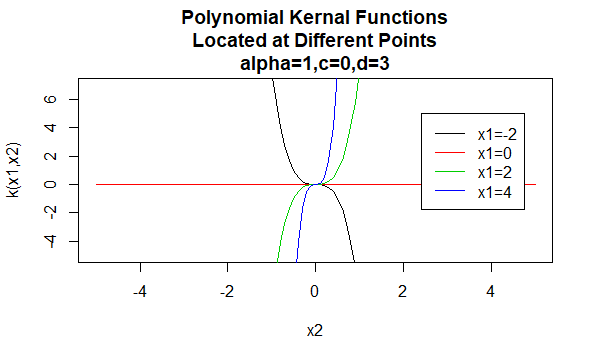
Polynomkerner
Polynomkerner er et eksempel på ikke-stationære kerner. Så disse kerner tildeler forskellige værdier til par punkter, der deler den samme afstand, baseret på deres værdier. Parameterværdier skal være ikke-negative for at sikre, at disse kerner er positive bestemte.
parametre: \(\alpha , c , d\)
Ligningsform: \(k(H_1,H_2)=(\alpha H_1^H_2 +c)^d\)
angivelse af bestemte værdier for parametrene for en kernefamilie resulterer i en kernefunktion. Nedenfor er eksempler på kernefunktioner fra ovenstående familier med bestemte parameterværdier placeret på forskellige punkter (dvs.den afbildede graf er en funktion af det andet argument, hvor det første argument er indstillet til en bestemt værdi).
Til Side: Interesserede studerende kan se definitionen af positiv definiteness for kerner i kerner og positiv Definiteness dokument tilgængelig i afsnittet overførsler i slutningen af denne artikel.
Kerneltricket
betydningen af kernefunktioner kommer fra en meget speciel egenskab: Hver positiv-bestemt kerne, \(K\) er relateret til et matematisk rum, \(\mathcal{H}_K\), (kendt som reproducerende kernel Hilbert space (rkhs) af kernen) sådan at anvendelse \(K\) på to funktionsvektorer, \(1,2\) svarer til at projicere disse funktionsvektorer i \(\mathcal{H}_K\) ved hjælp af en eller anden projektionsfunktion, \(\phi\) og tage deres indre produkt der:
\
Rkhs ‘ erne forbundet med kerner er typisk højdimensionelle. For nogle kerner, som gaussiske familiekerner, er de uendelige dimensionelle.
ovenstående er grundlaget for det berømte ‘kernetrick’: hvis inputfunktionerne kun er involveret i ligningen af en statistisk model i form af indre produkter, kan vi erstatte de indre produkter i ligningen med opkald til kernefunktionen, og resultatet er som om vi havde projiceret inputfunktionerne i et højere dimensionelt rum (dvs.udført en funktionstransformation, der fører til et stort antal latente variable funktioner) og taget deres indre produkt der. Men vi behøver aldrig at udføre den faktiske fremskrivning.
i maskinlæringsterminologi er de RKHS, der er knyttet til kernen, kendt som funktionsrummet i modsætning til inputrummet. Via kernetricket projicerer vi implicit inputfunktionerne i dette funktionsrum og tager deres indre produkt der.
Kernel Regression
dette fører til teknikken kendt som kernel regression. Det er simpelthen en anvendelse af kernen trick til den dobbelte form af højderyg regression. For at gøre det lettere introducerer vi ideen om kernen, eller Gram, matricen, \(K\), således at \(K_{i,j}=k(K_i,K_j)\). Så kan vi skrive ligningerne for kernel regression som:
\ \
hvor \(k\) er en positiv-bestemt kernefunktion.
Representer-sætningen
overvej det optimeringsproblem, vi søger at løse, når vi udfører L2-regulering for en model af en eller anden form, \(f\):
\
ved udførelse af kernelregression med kernel \(k\) er det et vigtigt resultat af reguleringsteori, at minimering af ovenstående ligning vil være af formen:
\
med \(\alpha\) beregnet som beskrevet ovenfor.
dette er den retfærdigt lioniserede Representer sætning. Med ord står det, at minimering af optimeringsproblemet for lineær regression i det implicitte funktionsrum opnået af en bestemt kerne (og dermed minimering af det ikke-lineære kerneregressionsproblem) vil blive givet af en vægtet sum af kerner ‘placeret’ ved hver funktionsvektor.
der er meget mere at sige om dette emne. Vi kan endda finde ud af, hvilken grøn funktion (hvoraf kerner er en delmængde) vil minimere særlige reguleringsspecifikationer, såsom L2-regulering, men også enhver straf baseret på en lineær differentieret operatør. Dette forhold mellem kerner og optimale løsninger på Tikhonov-regulariseringsproblemer er en principårsag til vigtigheden af kernemetoder i maskinindlæring. Men matematikken her er ud over dette kursus, og interesserede avancerede studerende henvises til kapitel syv af Haykins neurale netværk og Læringsmaskiner.
dette giver os en matematisk begrundelse for at bruge kernel regression i tilfælde, hvor det er muligt at gøre det. Det er typisk ikke muligt at udarbejde den optimale kerne, der skal bruges – det kræver at kende den optimale lineære differentieringsoperatør, der skal bruges til reguleringsstraffen. De funktioner, vi skal projicere på for at optimere bestemte reguleringsstraffe, er beregnet, og vi ved for eksempel, at tyndpladesplinekerne er optimal til L2-regulering. På nedsiden, da vi skal beregne Grammatricen, skalerer kernelregression ikke godt – for store datasæt, der vender sig til neurale netværk, er en bedre ide.