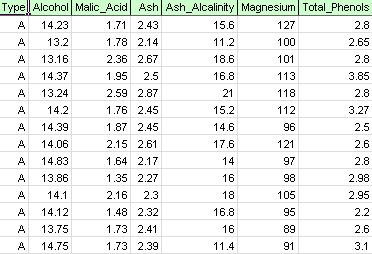
på fanen Anvend din Model skal du vælge Hjælp – eksempler og derefter prognoser/Data Mining eksempler og åbne eksempelfilen vin.- Nej. Som vist i nedenstående figur repræsenterer hver række i dette eksempel datasæt en prøve vin taget fra en af tre vingårde (A, B eller C). I dette eksempel ignoreres Typevariablen, der repræsenterer vingården, og klyngningen udføres simpelthen på basis af egenskaberne af vinprøverne (de resterende variabler).
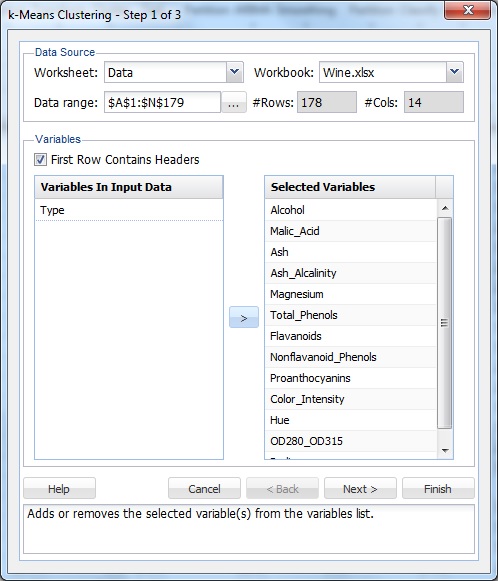
vælg en celle i datasættet, og vælg derefter på fanen dataanalyse på fanen dataanalyse.
fra listen Variabler skal du vælge alle variabler undtagen Type og derefter klikke på knappen > for at flytte de valgte variabler til listen Valgte variabler.
Klik på Næste for at gå videre til Trin 2 af 3 dialog.
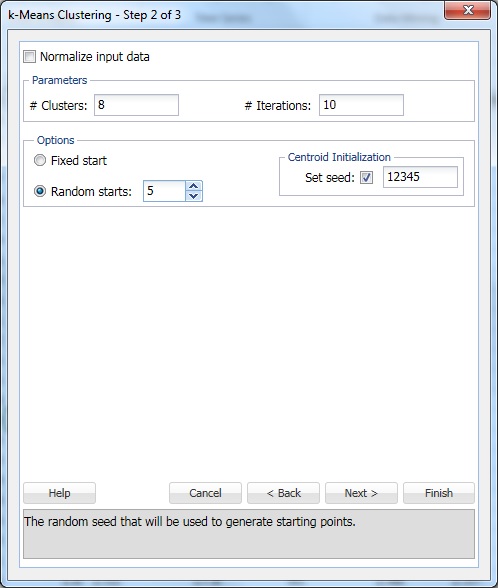
ved # Clusters, indtast 8. Dette er parameteren k i k-betyder klyngealgoritme. Antallet af klynger skal være mindst 1 og højst antallet af observationer -1 i dataområdet. Indstil k til flere forskellige værdier, og evaluer output fra hver.
Forlad #iterationer ved standardindstillingen på 10. Værdien for denne indstilling bestemmer, hvor mange gange programmet vil starte med en indledende partition og fuldføre clustering algoritme. Konfigurationen af klynger (og dataseparation) kan variere fra en startpartition til en anden. Programmet gennemgår det angivne antal iterationer og vælger klyngekonfigurationen, der minimerer afstandsmålet.
sæt tilfældig starter til 5. Når denne indstilling er valgt, begynder algoritmen at bygge modellen fra ethvert tilfældigt punkt. Vi genererer fem klynge sæt og genererer output baseret på den bedste klynge.
sæt frø er valgt som standard. Denne indstilling initialiserer den tilfældige talgenerator, der bruges til at beregne de oprindelige klyngecentroider. Indstilling af tilfældigt talfrø til en værdi, der ikke er nul (standard 12345) sikrer, at den samme sekvens af tilfældige tal bruges hver gang de oprindelige klyngecentroider beregnes. Når frøet er nul, initialiseres den tilfældige talgenerator fra systemuret, så sekvensen af tilfældige tal er forskellig hver gang centroiderne initialiseres. Indstil frøet til at se successive kørsler af klyngemetoden som sammenlignelige.
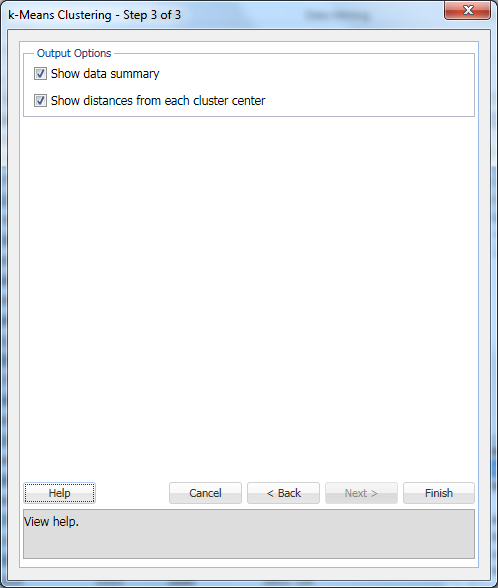
Vælg indstillingen Normaliser inputdata for at normalisere dataene. I dette eksempel vil dataene ikke blive normaliseret. Vælg Næste for at åbne dialogboksen Trin 3 af 3.
vælg Vis datasammendrag (standard) og vis afstande fra hvert klyngecenter (standard), og klik derefter på Udfør.
k-betyder Clustering metode starter med k indledende klynger som angivet. Ved hver iteration tildeles posterne til klyngen med det nærmeste centroid eller center. Efter hver iteration beregnes afstanden fra hver post til midten af klyngen. Disse to trin gentages (posttildelingen og afstandsberegningen), indtil omfordelingen af en post resulterer i en øget afstandsværdi.
når en tilfældig start er angivet, genererer algoritmen k-klyngecentrene tilfældigt og passer til datapunkterne i disse klynger. Denne proces gentages for alle angivne tilfældige starter. Udgangen er baseret på de klynger, der udviser den bedste pasform.
regnearket KM_Output1 indsættes straks til højre for dataarket. I det øverste afsnit af output-regnearket vises de valgte indstillinger.
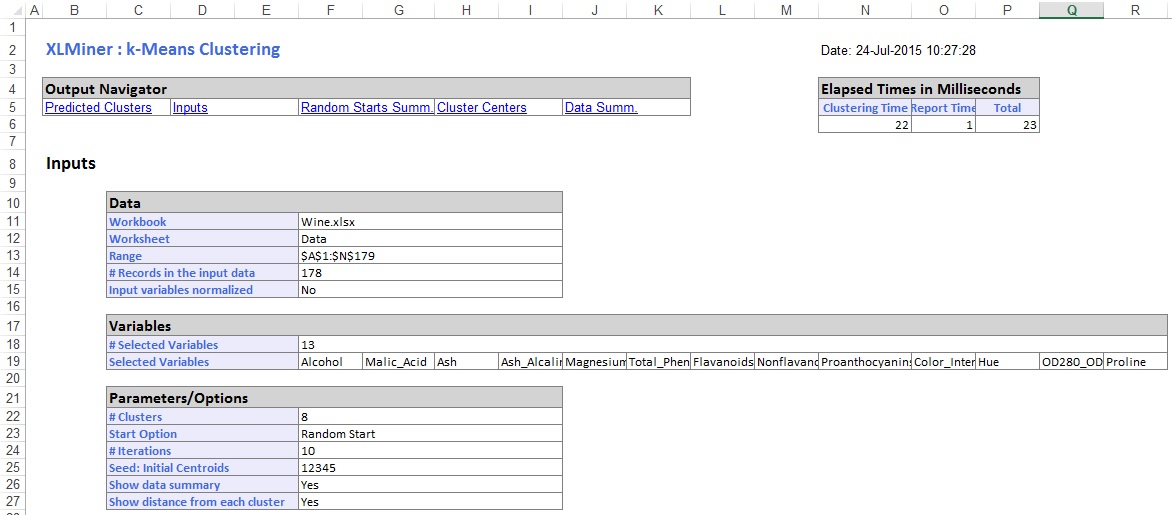
i den midterste del af outputarket har Lminer beregnet summen af de kvadratiske afstande og bestemt starten med den laveste sum af Kvadratafstand som den bedste Start (#5). Når den bedste Start er bestemt, genererer Lminer det resterende output ved hjælp af den bedste Start som udgangspunkt.
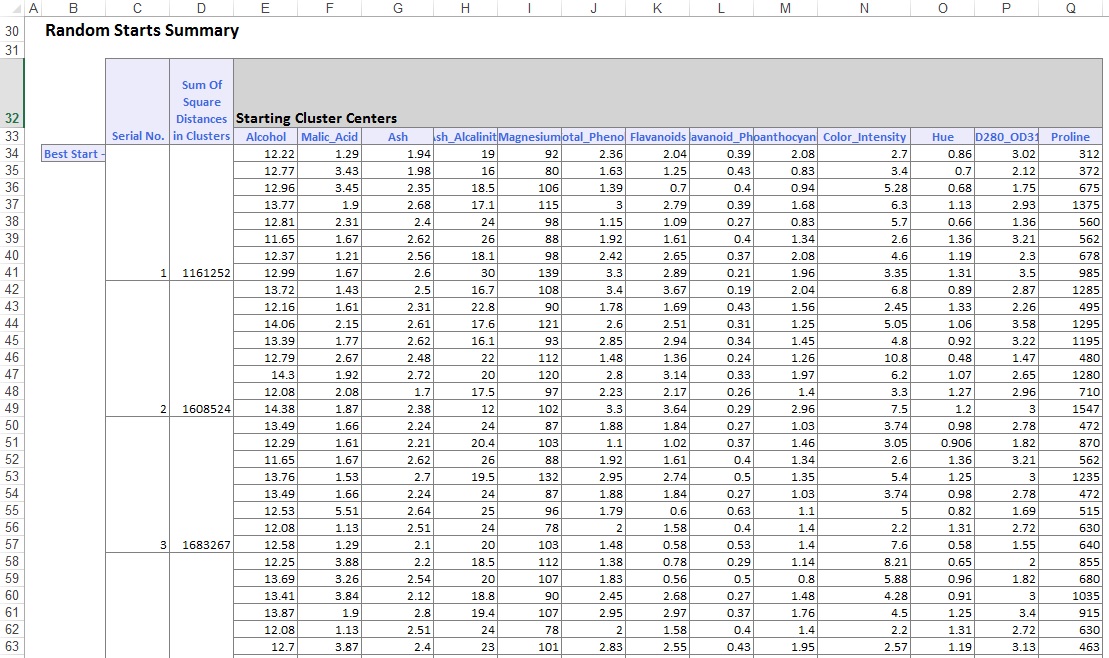
i den nederste del af output-regnearket har Lminer listet Klyngecentrene (vist nedenfor). Den øverste boks viser de variable værdier ved Klyngecentrene. Cluster 8 har den højeste gennemsnitlige alkohol, Total_phenoler, flavanoider, Proanthocyaniner, Color_Intensity, Hue og prolin indhold. Sammenlign denne klynge med klynge 2, som har den højeste gennemsnitlige Ash_alcalinitet og Nonflavanoid_phenoler.
den nederste boks viser afstanden mellem Klyngecentrene. Fra værdierne i denne tabel bestemmes det, at klynge 3 er meget forskellig fra klynge 8 på grund af den høje afstandsværdi på 1.176, 59, og klynge 7 er tæt på klynge 3 med en lav afstandsværdi på 89,73.
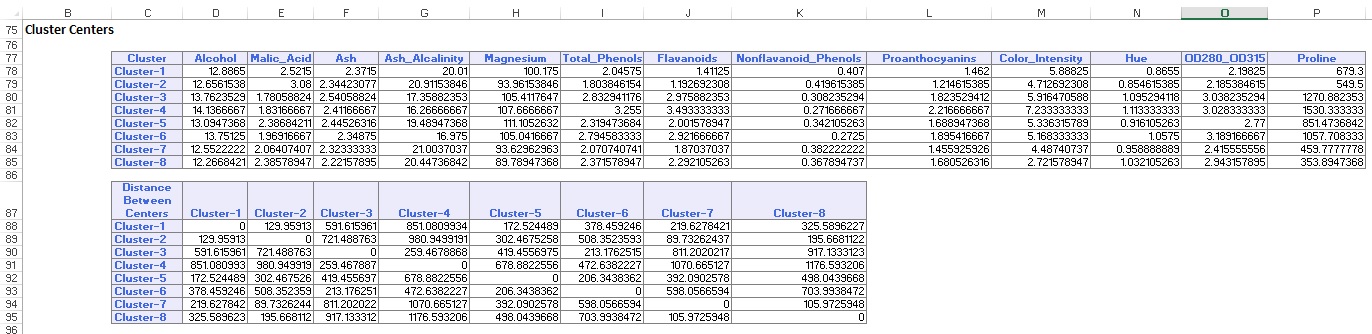
Dataoversigten (nedenfor) viser antallet af poster (observationer) inkluderet i hver klynge og den gennemsnitlige afstand fra klyngemedlemmer til midten af hver klynge. Cluster 6 har den højeste gennemsnitlige afstand på 42,79 og inkluderer 24 poster. Sammenlign denne klynge med klynge 2, som har den mindste gennemsnitlige afstand på 29,66, og inkluderer 26 medlemmer.
Klik på km_clusters1 regneark. Dette regneark viser den klynge, som hver post er tildelt, og afstanden til hver af klyngerne. For den første post er afstanden til Cluster 6 den mindste afstand på 23.205, så denne første post er tildelt Cluster 6.