af: Arshad Ali | opdateret: 2013-06-24 | Kommentarer (9) | relateret: > udvikling af analysetjenester
Problem
i mine sidste par tip talte jeg om vigtigheden af en Business Intelligence-løsning, hvorfor det bliver prioriteret en typisk Business Intelligence systemarkitektur ser ud osv. I dette tip vil jeg tale i detaljerom, hvordan et datalager er forskelligt fra operationelt datalager og de forskellige designmetoder for et datalager.
løsning
dette tip vil dække datalagre (DV, engang også kaldetet Enterprise Data lager eller EDV), hvordan det adskiller sig fra Operational Data Store (ODS) og forskellige Datalagerdesignmetoder.
Enterprise Data lager Vs. Operational Data Store (ODS)
formålet med datalageret i den overordnede Business Intelligence-arkitektur er at integrere virksomhedsdata fra forskellige heterogene datakilder for at lette historisk og trendanalyserapportering. Det fungerer som en central repository og indeholder “enkelt version af sandheden” for den organisation, der er blevet omhyggeligt konstrueret ud fra data lagret i forskellige interne og eksterne operationelle databaser\systemer. For bedre ydeevne vil for det meste data i datalager være i de-normaliseret form, som kan kategoriseres i enten stjerne-eller snefnugskemaer (mere om dette i det næste tip).
formålet med Operation Data Store (ODS) er at integrere virksomhedsdata fra forskellige heterogene datakilder for at lette operationel rapportering i realtid eller nær realtid. Ofte vil data i ODS være struktureret svarende til kildesystemerne, selvom det under integration kan involvere datarensning, de-duplikering og kan anvende forretningsregler for at sikre dataintegritet. En ODS er hovedsagelig beregnet til at integrere data ganske ofte på det laveste granulære niveau for operationel rapportering i et tæt på realtid dataintegrationsscenarie. Normalt vil en ODS ikke blive optimeret til historisk og trendanalyse på enorme datasæt.
lad os opsummere forskellene mellem en ODS og DV:
- en ODS er beregnet til operationel rapportering og understøtter aktuelle eller næsten realtidsrapporteringskrav, hvor en DV er beregnet til historisk og trendanalyserapportering af en stor mængde data
- en ODS er målrettet mod lavkornede forespørgsler, mens en DV bruges til komplekse forespørgsler mod summarisk niveau eller på aggregerede data
- en ODS giver information til operationelle, taktiske beslutninger om nuværende eller næsten realtidsdata vi leverer feedback til strategiske beslutninger, der fører til overordnede systemforbedringer
- i en ODS hyppigheden af data load kan være hver time eller dagligt, mens hyppigheden af data loads kan være daglig, ugentlig, månedlig eller kvartalsvis
datalager Design metoder
der er to forskellige metoder, der normalt følges ved design af en datalager løsning og baseret på kravene i dit projekt kan du vælge, hvilken der passer til dit særlige scenario. Disse metoder er resultatet af forskning fra BillInmon og Ralph Kimball.
Bill Inmon – Top-ned datalager Design tilgang
Bill Inmon kaldes undertiden også “far til datalagring”; hans designmetode er baseret på en top-ned tilgang og definerer datalager i disse termer
- Fagorienteret – dataene i et datalager er kategoriseret på baggrund af fagområdet, og derfor er det “fagorienteret”.
- integreret – Data bliver integreret fra forskellige forskellige datakilder og dermed universelle navngivningskonventioner, målinger, klassifikationer og så videre brugt i datalageret. Datalageret giver en virksomhedskonsolideret oversigt over data og er derfor udpeget somen integreret løsning.
- ikke-flygtig – når dataene er integreret\indlæst i datalageret, kan de kun læses. Brugere kan ikke foretage ændringer i dataene, og denne praksis gør dataene ikke-flygtige.
- Tidsvariant – endelig gemmes data i lange perioder kvantificeret i år og har en dato og tidsstempel, og derfor beskrives det som “tidsvariant”.
Bill Inmon så et behov for at integrere data fra forskellige OLTP-systemer i et centraliseret lager (kaldet datavarehus) med en såkaldt ovenfra og ned tilgang. Bill Inmon forestiller sig et datalager i centrum af” Corporate Information Factory ” (CIF), som giver en logisk ramme for levering af business intelligence (BI), business analytics og business management kapaciteter.
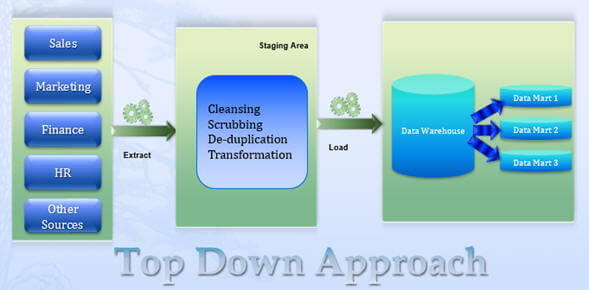
dette ovenfra og ned design giver en meget ensartet dimensionel visning af data på tværs af datamarts, da alle datamarts indlæses fra det centraliserede lager (datalager).Top-ned-designet har også vist sig at være fleksibelt til at understøtte forretningsændringer, da det ser ud til organisationen som helhed, ikke ved hver funktion eller forretningsproces i organisationen. Generering af en ny dimensionel datamarts mod de data, der er gemt idatavarehuset er en relativt simpel opgave. Selv om der er nogle udfordringer for top-ned-tilgangen, repræsenterer det for eksempel et meget stort projekt med et meget bredt omfang, og derfor er omkostningerne ved at implementere et datalager ved hjælp af top-ned-metoden betydelig.Endvidere kan varigheden af tiden fra projektets start til det punkt, hvor slutbrugerne begynder at opleve de første fordele ved løsningen, være betydelig. Top-ned-metoden kan også være ufleksibel og ikke reagere på skiftende afdelings-eller forretningsprocesbehov (en bekymring for dagens dynamisk skiftende miljø) i implementeringsfasen.
Ralph Kimball – Bottom-up datalager Design tilgang
Ralph Kimball er en berømt forfatter om emnet datalagring. Hans designmetode kaldes dimensionel modellering ellerkimball-metoden. Denne metode fokuserer på en bottom – up tilgang, understreger værdien af datalageret til brugerne så hurtigt som muligt. I hans vision er et datalager kopien af de transaktionsdata, der er specifikt struktureret til analytisk forespørgsel og rapportering for at understøttebeslutningsstøttesystemet. I henhold til hans metode oprettes datamarts først for at give rapporterings-og analysefunktioner til specifikke forretnings funktionelle processer, og senere kan disse datamarts til sidst forenes sammen for at skabe et omfattende virksomhedsdatalager. Bottom – up-tilgangen fokuserer på hver forretningsproces på et tidspunkt, så investeringsafkastet kan være så hurtigt som First data mart bliver oprettet. Selvom du ikke er omhyggeligt planlagt, mangler du muligvis det store billede af virksomhedens datalager ved at gå glip af nogle dimensioner eller ved at oprette overflødige dimensioner osv. når du er for fokuseret på en individuel forretningsproces.
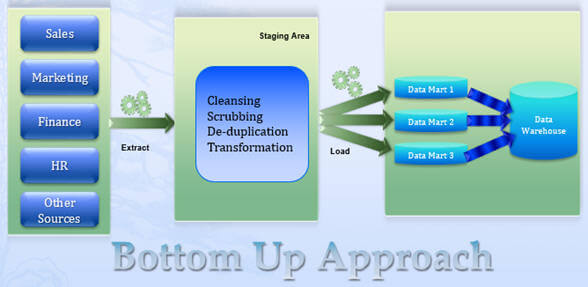
Ralph Kimballs bottom-up-tilgang foreslår at oprette en forretningsmatrice, der skal indeholde alle de fælles elementer (som bruges af datamarts som konformeret\delt dimension, foranstaltninger osv.) defineret for virksomheden som helhed. Med dette kan brugeren designe og udvikle løsninger, der understøtter analyse på tværs af forretningsprocesserne til krydssalg. Du kan læse mere om matricen her.
for en person, der ønsker at lave en karriere inden for datalager og Business Intelligence-domæne, vil jeg anbefale at studere Bill Inmons bøger (opbygning af datalageret og DV 2.0: arkitekturen til den næste Generation af datalagring) og Ralph Kimballs bog (Microsoft Data lager Toolkit).
næste trin
- Anmeldelsemicrosoft Server Business Intelligence – Hvad, hvorfor og hvordan – Del 1.
- Anmeldelsemicrosoft Server Business Intelligence systemarkitektur – Del 2.
- Tjek alle Theskl Server Business Intelligence tips om MSSQLTips.com.
sidst opdateret: 2013-06-24


om forfatteren
 Arshad Ali er en udvikler med fokus på Datalagringsprojekter for Microsoft.
Arshad Ali er en udvikler med fokus på Datalagringsprojekter for Microsoft.se alle mine tips
- flere Business Intelligence Tips…