Wir beginnen mit der dualen linearen / Ridge-Regression, bevor wir zeigen, wie man sie ‚kernelisiert‘. Wenn wir letzteres erklären, werden wir sehen, was Kernel sind und was der ‚Kernel-Trick‘ ist.
Dual-Form Ridge Regression
Die lineare Regression wird typischerweise in ihrer Primärform als lineare Kombination von Spalten (Features) angegeben. Es gibt jedoch eine zweite, duale Form, bei der es sich um eine lineare Kombination des inneren Produkts eines neuen Datums (auf das wir Inferenz durchführen) mit jedem der Trainingsdaten handelt.
Wir betrachten den Fall der Gratregression (L2 regularisierte lineare Regression), wobei wir uns daran erinnern, dass die grundlegende lineare Regression dem Fall entspricht, in dem \(\lambda = 0\). Dann sind die Formeln für die Gratregression, wobei \(X\) und \(Y\) sich auf die \(n\mal m\) Trainingsdaten beziehen und \(x^\prime,y^\prime\) ein neuer zu schätzender Fall sind:
\ \ \ \
Wobei \(\langle X_i,x^\prime \rangle\) das innere / Punktprodukt ist, also \(\langle X_i,x^\prime \rangle = X^T_i x^\prime = \sum_j^m X_{i,j} x^\prime_j\).
Die duale Form zeigt, dass die lineare / Grat-Regression auch als Schätzung einer gewichteten Summe des inneren Produkts eines neuen Falls mit jedem der Trainingsfälle verstanden werden kann.
Dies bedeutet, dass wir auch dann eine lineare Regression durchführen können, wenn mehr Spalten als Zeilen vorhanden sind, obwohl die Bedeutung davon überschätzt werden kann, da (i) wir dies trotzdem über die Verwendung der L2-Regularisierung tun können, da dies die \(X ^ TX\) -Matrix immer invertierbar macht; und (ii) Die \(XX ^ T \) -Matrix kann häufig trotzdem eine L2-Regularisierung erfordern, um die numerische Stabilität für die Inversion sicherzustellen. Es erlaubt uns auch, die lineare Regression eher als einen sequentiellen Lernprozess zu betrachten, bei dem jedes zusätzliche Datum in den Trainingsdaten etwas Neues bringt.
Am wichtigsten für unsere Zwecke ist jedoch, dass die duale Form die interessante Eigenschaft hat: Merkmalsvektoren treten in den Gleichungen nur innerhalb innerer Produkte auf. Dies gilt auch für die Definition von \(\alpha\) , da \(XX ^ T\) die Matrix erzeugt, die den inneren Produkten jedes Paares von Merkmalsvektoren in den Trainingsdaten entspricht. Wir werden sehen, wie wichtig dies ist, wenn wir fortfahren.
Zur Seite: Wie das Doppelformular abgeleitet wurde, können interessierte Studierende im Dokument Ableitung des Doppelformulars im Downloadbereich am Ende dieses Artikels nachlesen.
Nichtlineare Dual-Ridge-Regression
Wir können unsere Dual-Form-Ridge-Regression in ein nichtlineares Modell umwandeln, indem wir die Standardmethode der Verwendung eines nichtlinearen Merkmals verwenden: \(\phi\):
\ \
Kernelfunktionen
Eine Kernelfunktion, \(K: \mathcal X \times \mathcal X \to \mathbb{R}\), ist eine Funktion, die symmetrisch ist – \(K(x_1,x_2)=K(x_2,x_1)\) – und positiv definit (siehe das Beispiel für eine formale Definition). Positiv-Definität wird in der Mathematik verwendet, die die Verwendung von Kerneln rechtfertigt. Aber ohne signifikante mathematische Kenntnisse ist die Definition nicht intuitiv aufschlussreich. Anstatt also zu versuchen, Kernel aus der Definition der Positivdefinition zu verstehen, werden wir sie mit einer Reihe von Beispielen vorstellen.
Bevor wir dies tun, stellen wir fest, dass Kernel zwar Funktionen mit zwei Argumenten sind, es jedoch üblich ist, dass sie sich an ihrem ersten Argument befinden und eine Funktion ihres zweiten Arguments sind. Nach dieser Interpretation sehen Sie eine Notation wie \(K_x(y)\) , die \(K(x,y)\) entspricht . Insbesondere werden wir oft daran denken, dass Kernel Einzelargumentfunktionen sind, die sich an Datenpunkten (Merkmalsvektoren) in unseren Trainingsdaten befinden. Manchmal werden Sie lesen, dass wir Kernel auf Datenpunkte fallen lassen. Wenn wir also einen Merkmalsvektor \(x_i\) haben, würden wir einen Kernel darauf ablegen, der zu der Funktion \(K_{x_i}(x)\) führt, die sich bei \(x_i\) und äquivalent zu \(K(x_i,x)\) .
Wir stellen auch fest, dass Kernel häufig als Mitglieder parametrischer Familien angegeben werden. Beispiele für solche Kernelfamilien sind:
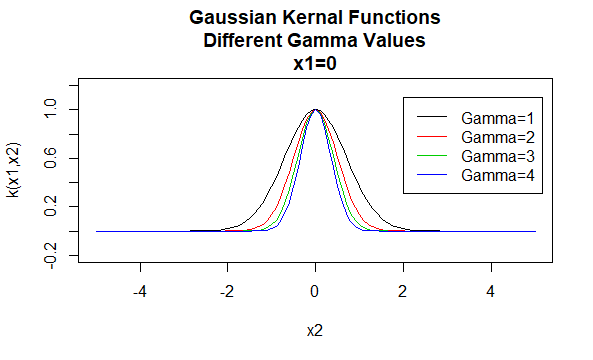
Gaußsche Kernel
Gaußsche Kernel sind ein Beispiel für radiale Basisfunktionskerne und werden manchmal als radiale Basiskerne bezeichnet. Der Wert eines radialen Basisfunktionskerns hängt nur vom Abstand zwischen den Argumentvektoren und nicht von ihrer Position ab. Solche Kerne werden auch als stationär bezeichnet.
Parameter: \(\gamma\)
Gleichungsform: \(K(X_1,X_2)=e^{-\gamma \| X_1 – X_2 \|^2}\)
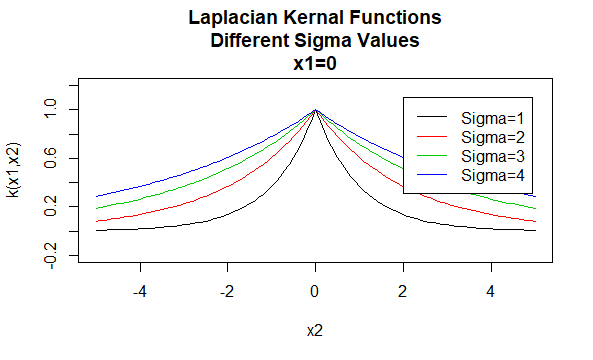
Laplace-Kernel
Laplace-Kernel sind auch radiale Basisfunktionen.
Parameter: \(\sigma\)
Gleichungsform: \(K(X_1,X_2)=e^{-\frac{\| X_1 – X_2 \|}{\sigma}}\)
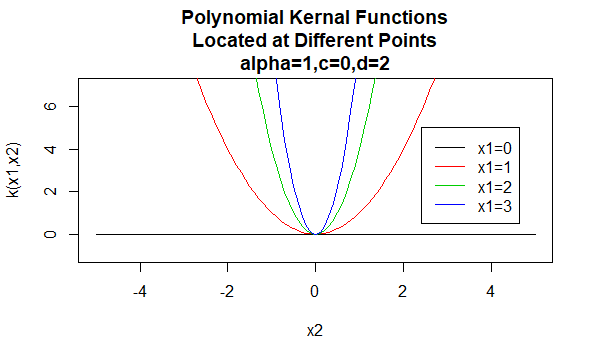
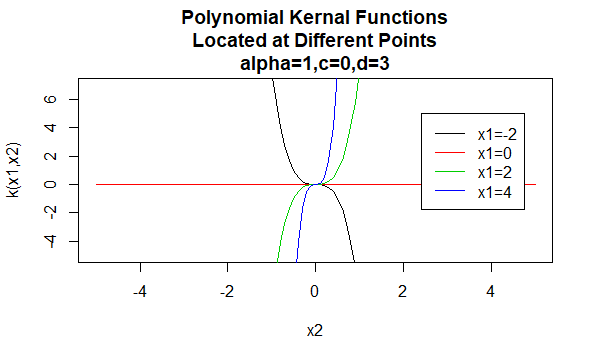
Polynomialkerne
Polynomialkerne sind ein Beispiel für nicht stationäre Kernel. Diese Kernel weisen Punktepaaren, die denselben Abstand haben, basierend auf ihren Werten unterschiedliche Werte zu. Parameterwerte müssen nicht negativ sein, um sicherzustellen, dass diese Kernel positiv definiert sind.
Parameter: \(\alpha , c , d\)
Gleichungsform: \(K(X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
Die Angabe bestimmter Werte für die Parameter einer Kernelfamilie führt zu einer Kernelfunktion. Im Folgenden finden Sie Beispiele für Kernelfunktionen aus den obigen Familien mit bestimmten Parameterwerten, die sich an verschiedenen Punkten befinden (dh der gezeichnete Graph ist eine Funktion des zweiten Arguments, wobei das erste Argument auf einen bestimmten Wert gesetzt ist).
Beiseite: Interessierte Schüler können die Definition der positiven Bestimmtheit für Kernel im Dokument Kernel und positive Bestimmtheit einsehen, das im Downloadbereich am Ende dieses Artikels verfügbar ist.
Der Kernel-Trick
Die Bedeutung von Kernel-Funktionen ergibt sich aus einer ganz besonderen Eigenschaft: Jeder positiv bestimmte Kernel, \(K\) ist mit einem mathematischen Raum verwandt, \(\mathcal{H}_K\), (bekannt als der reproduzierende Kernel-Hilbert-Raum (RKHS) des Kernels), so dass die Anwendung von \(K\) auf zwei Merkmalsvektoren, \(X_1, X_2 \) entspricht der Projektion dieser Merkmalsvektoren in \ (\mathcal{H}_K\) durch eine Projektionsfunktion, \(\phi \) und deren inneres Produkt dort:
\
Die mit Kerneln verbundenen RKHSs sind typischerweise hochdimensional. Für einige Kerne, wie Gaußsche Familienkerne, sind sie unendlich dimensional.
Das Obige ist die Grundlage für den berühmten ‚Kerntrick‘: Wenn die Eingabemerkmale nur in Form von inneren Produkten in die Gleichung eines statistischen Modells einbezogen werden, können wir die inneren Produkte in der Gleichung durch Aufrufe der Kernfunktion ersetzen und das Ergebnis ist, als hätten wir die Eingabemerkmale in einen höherdimensionalen Raum projiziert (dh eine Merkmalstransformation durchgeführt, die zu einer großen Anzahl latenter variabler Merkmale führt) und dort ihr inneres Produkt genommen. Aber wir müssen nie die eigentliche Projektion durchführen.
In der Terminologie des maschinellen Lernens wird das dem Kernel zugeordnete RKHS im Gegensatz zum Eingaberaum als Merkmalsraum bezeichnet. Über den Kernel-Trick projizieren wir implizit die Eingabe-Features in diesen Feature-Raum und nehmen dort ihr inneres Produkt.
Kernel-Regression
Dies führt zu der Technik, die als Kernel-Regression bekannt ist. Es ist einfach eine Anwendung des Kernel-Tricks auf die duale Form der Ridge-Regression. Der Einfachheit halber stellen wir die Idee des Kernels oder der Grammmatrix \(K\) vor, so dass \(K_{i,j}=k(X_i,X_j)\) . Dann können wir die Gleichungen für die Kernregression schreiben als:
\ \
Wobei \(k\) eine positiv-bestimmte Kernelfunktion ist.
Das Representer-Theorem
Betrachten Sie das Optimierungsproblem, das wir lösen möchten, wenn wir die L2-Regularisierung für ein Modell irgendeiner Form durchführen, \(f\):
\
Bei der Durchführung der Kernregression mit kernel \(k\) ist es ein wichtiges Ergebnis der Regularisierungstheorie, dass der Minimierer der obigen Gleichung die Form hat:
\
Mit \(\alpha\) wie oben beschrieben berechnet.
Dies ist das zu Recht verherrlichte Representer-Theorem. Mit anderen Worten, es besagt, dass der Minimierer des Optimierungsproblems für die lineare Regression in dem impliziten Merkmalsraum, der von einem bestimmten Kernel erhalten wird (und damit der Minimierer des nichtlinearen Kernelregressionsproblems), durch eine gewichtete Summe von Kernen gegeben ist, die sich an jedem Merkmalsvektor befinden.
Zu diesem Thema gibt es noch viel mehr zu sagen. Wir können sogar herausfinden, welche grüne Funktion (von denen Kernel eine Teilmenge sind) bestimmte Regularisierungsspezifikationen minimiert, wie z. B. die L2-Regularisierung, aber auch jede Strafe, die auf einem linearen Differentialoperator basiert. Diese Beziehung zwischen Kerneln und optimalen Lösungen für Tikhonov-Regularisierungsprobleme ist ein Hauptgrund für die Bedeutung von Kernelmethoden im maschinellen Lernen. Aber die Mathematik hier geht über diesen Kurs hinaus, und interessierte Fortgeschrittene werden auf Kapitel sieben von Haykins Neuronalen Netzen und Lernmaschinen verwiesen.
Dies gibt uns eine mathematische Rechtfertigung für die Verwendung der Kernelregression in Fällen, in denen dies möglich ist. Es ist normalerweise nicht möglich, den optimalen Kernel für die Verwendung zu ermitteln – es ist erforderlich, den optimalen linearen Differentialoperator zu kennen, der für die Regularisierungsstrafe verwendet werden soll. Die Funktionen, auf die wir projizieren sollten, um bestimmte Regularisierungsstrafen zu optimieren, wurden berechnet, und wir wissen zum Beispiel, dass der Dünnplatten-Spline-Kernel für die L2-Regularisierung optimal ist. Auf der anderen Seite, da wir die Gram–Matrix berechnen müssen, skaliert die Kernel-Regression nicht gut – für große Datensätze ist es eine bessere Idee, sich neuronalen Netzen zuzuwenden.