Wählen Sie im XLMiner-Menüband auf der Registerkarte Anwenden Ihres Modells die Option Hilfe – Beispiele, dann Forecasting/Data Mining-Beispiele aus, und öffnen Sie die Beispieldatei Wine.xlsx. Wie in der folgenden Abbildung dargestellt, stellt jede Zeile in diesem Beispieldatensatz eine Weinprobe aus einem der drei Weingüter (A, B oder C) dar. In diesem Beispiel wird die Typvariable, die das Weingut darstellt, ignoriert, und das Clustering wird einfach auf der Grundlage der Eigenschaften der Weinproben (der verbleibenden Variablen) durchgeführt.
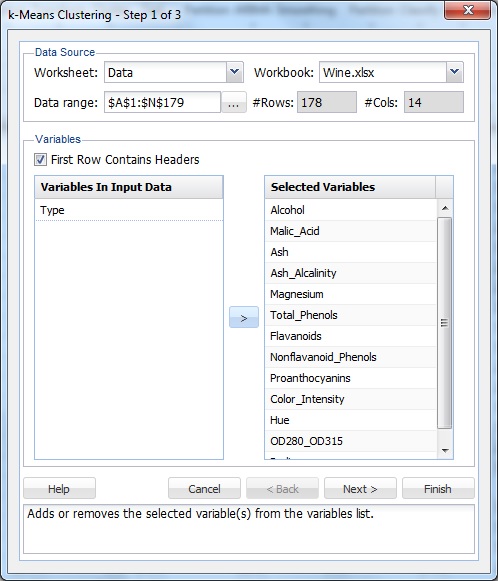
Wählen Sie eine Zelle innerhalb des Datensatzes aus, und wählen Sie dann im XLMiner-Menüband auf der Registerkarte Datenanalyse die Option XLMiner – Cluster – k-Means-Clustering aus, um das Dialogfeld k-Means-Clustering Schritt 1 von 3 zu öffnen.
Wählen Sie in der Liste Variablen die Option Alle Variablen außer Typ aus, und klicken Sie dann auf die Schaltfläche >, um die ausgewählten Variablen in die Liste Ausgewählte Variablen zu verschieben.
Klicken Sie auf Weiter, um zum Dialogfeld Schritt 2 von 3 zu gelangen.
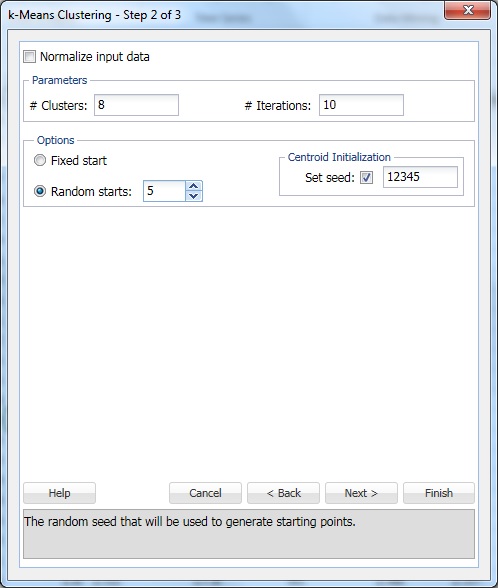
Geben Sie unter # Clusters 8 ein. Dies ist der Parameter k im k-Means-Clustering-Algorithmus. Die Anzahl der Cluster sollte mindestens 1 und höchstens die Anzahl der Beobachtungen -1 im Datenbereich betragen. Setzen Sie k auf mehrere verschiedene Werte und werten Sie die Ausgabe von jedem aus.
Belassen Sie #Iterations bei der Standardeinstellung 10. Der Wert für diese Option bestimmt, wie oft das Programm mit einer anfänglichen Partition startet und den Clustering-Algorithmus abschließt. Die Konfiguration von Clustern (und die Datentrennung) kann von Startpartition zu Startpartition unterschiedlich sein. Das Programm durchläuft die angegebene Anzahl von Iterationen und wählt die Clusterkonfiguration aus, die das Entfernungsmaß minimiert.
Setzen Sie zufällige Starts auf 5. Wenn diese Option ausgewählt ist, beginnt der Algorithmus mit der Erstellung des Modells von einem beliebigen zufälligen Punkt aus. XLMiner generiert fünf Cluster-Sets und generiert die Ausgabe basierend auf dem besten Cluster.
Set seed ist standardmäßig ausgewählt. Diese Option initialisiert den Zufallszahlengenerator, der zur Berechnung der anfänglichen Clusterschwerpunkte verwendet wird. Wenn Sie den Startwert für Zufallszahlen auf einen Wert ungleich Null setzen (Standardwert 12345), wird sichergestellt, dass bei jeder Berechnung der anfänglichen Clusterschwerpunkte dieselbe Folge von Zufallszahlen verwendet wird. Wenn der Startwert Null ist, wird der Zufallszahlengenerator von der Systemuhr initialisiert, sodass die Folge der Zufallszahlen bei jeder Initialisierung der Schwerpunkte unterschiedlich ist. Legen Sie den Startwert fest, um aufeinanderfolgende Durchläufe der Clustermethode als vergleichbar anzuzeigen.
Wählen Sie die Option Eingabedaten normalisieren, um die Daten zu normalisieren. In diesem Beispiel werden die Daten nicht normalisiert. Wählen Sie Weiter, um das Dialogfeld Schritt 3 von 3 zu öffnen.
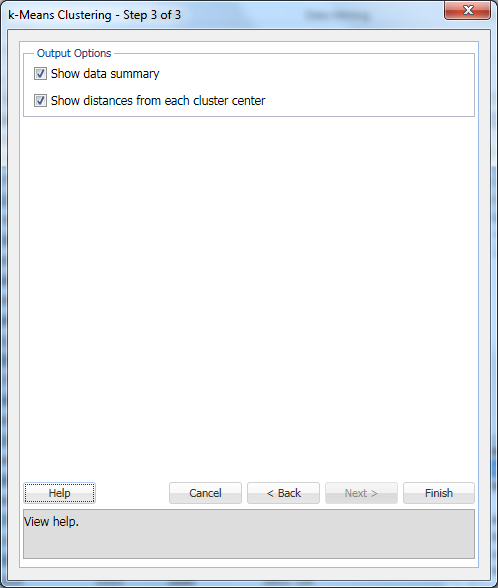
Wählen Sie Datenzusammenfassung anzeigen (Standard) und Entfernungen von jedem Clusterzentrum anzeigen (Standard) aus, und klicken Sie dann auf Fertig stellen.
Die k-Means-Clustering-Methode beginnt mit k anfänglichen Clustern wie angegeben. Bei jeder Iteration werden die Datensätze dem Cluster mit dem nächstgelegenen Schwerpunkt oder Mittelpunkt zugewiesen. Nach jeder Iteration wird der Abstand von jedem Datensatz zur Mitte des Clusters berechnet. Diese beiden Schritte werden wiederholt (Datensatzzuordnung und Abstandsberechnung), bis die Umverteilung eines Datensatzes zu einem erhöhten Abstandswert führt.
Wenn ein zufälliger Start angegeben wird, generiert der Algorithmus die k Clusterzentren zufällig und passt die Datenpunkte in diesen Clustern an. Dieser Vorgang wird für alle angegebenen Zufallsstarts wiederholt. Die Ausgabe basiert auf den Clustern, die die beste Anpassung aufweisen.
Das Arbeitsblatt KM_Output1 wird unmittelbar rechts neben dem Datenarbeitsblatt eingefügt. Im oberen Abschnitt des Ausgabeblatts werden die ausgewählten Optionen aufgelistet.
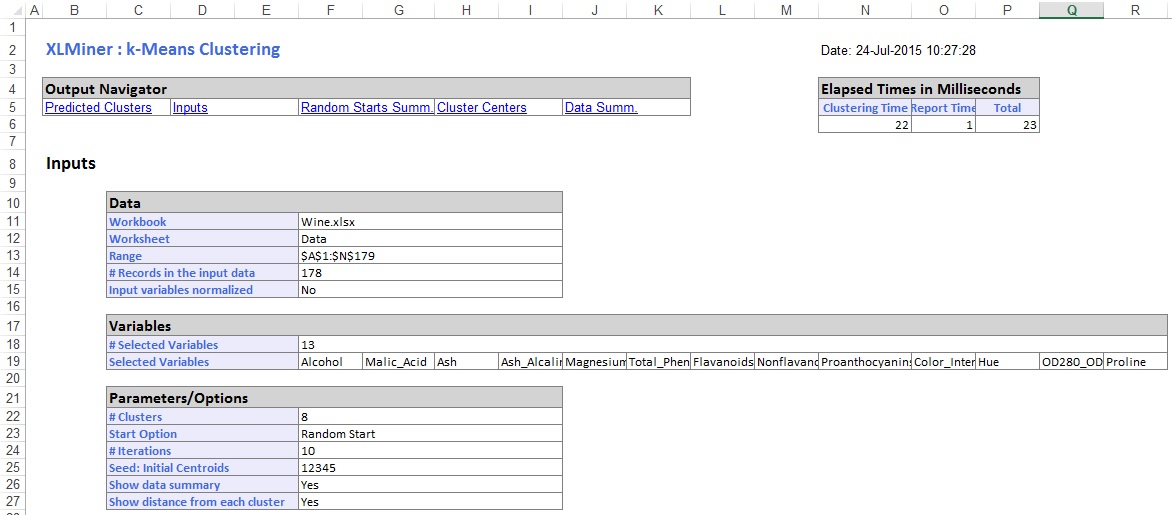
Im mittleren Abschnitt des Ausgabe-Arbeitsblatts hat XLMiner die Summe der quadratischen Abstände berechnet und den Start mit der niedrigsten Summe der quadratischen Abstände als besten Start bestimmt (# 5). Nachdem der beste Start ermittelt wurde, generiert XLMiner die verbleibende Ausgabe unter Verwendung des besten Starts als Ausgangspunkt.
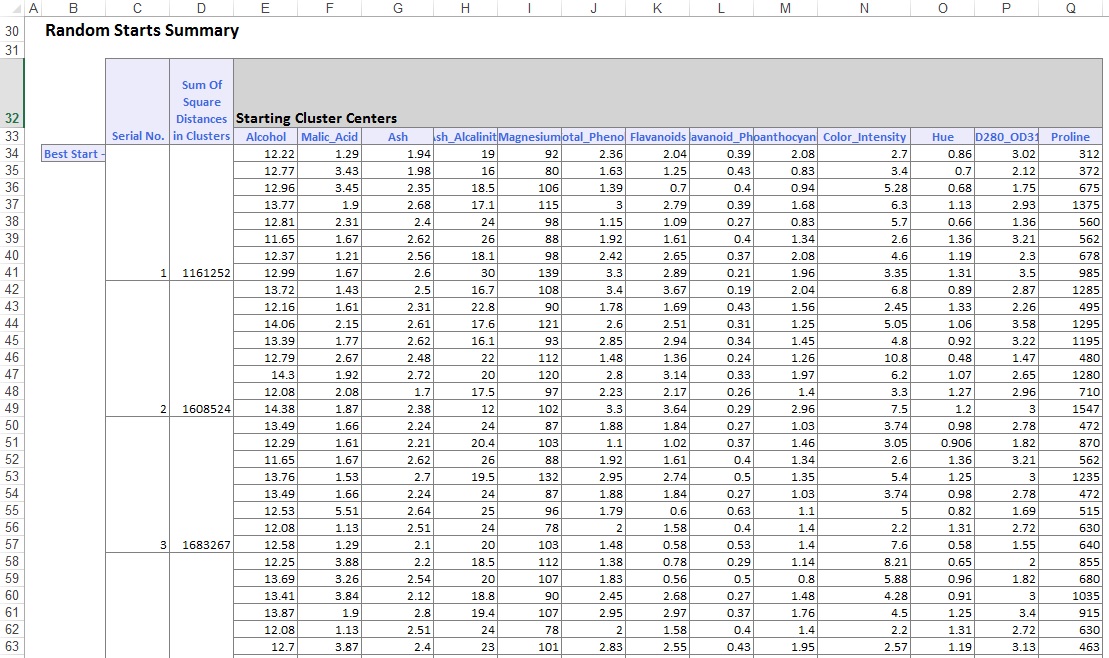
Im unteren Teil des Ausgabe-Arbeitsblatts hat XLMiner die Cluster-Zentren aufgelistet (siehe unten). Das obere Feld zeigt die Variablenwerte in den Clusterzentren. Cluster 8 hat den höchsten durchschnittlichen Alkohol-, Gesamtphenol-, Flavanoid-, Proanthocyanin-, Farbintensitäts-, Farbton- und Prolingehalt. Vergleichen Sie diesen Cluster mit Cluster 2, der die höchste durchschnittliche Ash_Alcalinity und Nonflavanoid_Phenole aufweist.
Das untere Feld zeigt den Abstand zwischen den Clusterzentren. Aus den Werten in dieser Tabelle wird ermittelt, dass sich Cluster 3 aufgrund des hohen Entfernungswerts von 1.176,59 stark von Cluster 8 unterscheidet und Cluster 7 mit einem niedrigen Entfernungswert von 89,73 nahe an Cluster 3 liegt.
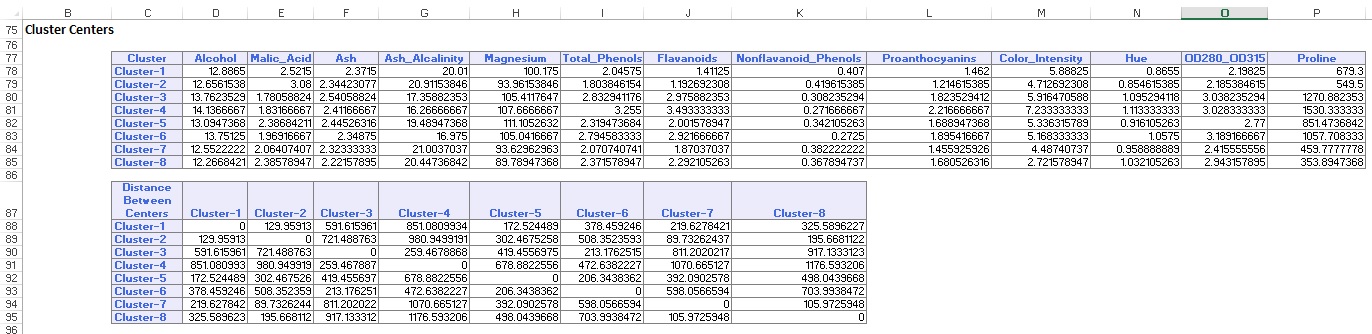
Die Datenzusammenfassung (unten) zeigt die Anzahl der Datensätze (Beobachtungen) an, die in jedem Cluster enthalten sind, und die durchschnittliche Entfernung von Clustermitgliedern zum Zentrum jedes Clusters. Cluster 6 hat die höchste durchschnittliche Entfernung von 42,79 und enthält 24 Datensätze. Vergleichen Sie diesen Cluster mit Cluster 2, der die kleinste durchschnittliche Entfernung von 29,66 aufweist und 26 Mitglieder umfasst.
Klicken Sie auf das Arbeitsblatt KM_Clusters1. In diesem Arbeitsblatt werden der Cluster, dem jeder Datensatz zugeordnet ist, und die Entfernung zu den einzelnen Clustern angezeigt. Für den ersten Datensatz ist der Abstand zu Cluster 6 der Mindestabstand von 23,205, sodass dieser erste Datensatz Cluster 6 zugewiesen wird.