Tweet
Wenn Sie nicht sicher sind, was Kafka ist, lesen Sie Was ist Kafka?.
- Kafka-Architektur
- Kafka-Architektur: Themen, Produzenten und Konsumenten
- Kafka Architektur: Core Kafka
- Kafka benötigt ZooKeeper
- Kafka-Produzent, Verbraucher, Themendetails
- Kafka-Architektur: Themenpartition, Verbrauchergruppe, Offset und Produzenten
- Kafka-Skalierung und -geschwindigkeit
- Kafka Brokers
- Kafka Cluster, Failover, ISRs
- Kafka Failover vs. Kafka Disaster Recovery
- Kafka Architektur: Kafka Zookeeper Koordination
- Kafka Topics Architecture
- Über Cloudurable
Kafka-Architektur
Kafka besteht aus Datensätzen, Themen, Verbrauchern, Produzenten, Brokern, Protokollen, Partitionen und Clustern. Datensätze können Schlüssel (optional), Wert und Zeitstempel haben. Kafka-Datensätze sind unveränderlich. Ein Kafka-Thema ist ein Stream von Datensätzen ("/orders", "/user-signups"). Sie können sich ein Thema als Feednamen vorstellen. Ein Thema verfügt über ein Protokoll, bei dem es sich um den Speicher des Themas auf der Festplatte handelt. Ein Themenprotokoll ist in Partitionen und Segmente unterteilt. Die Kafka Producer API wird verwendet, um Ströme von Datensätzen zu erzeugen. Die Kafka Consumer API wird verwendet, um einen Stream von Datensätzen aus Kafka zu konsumieren. Ein Broker ist ein Kafka-Server, der in einem Kafka-Cluster ausgeführt wird. Kafka-Broker bilden einen Cluster. Der Kafka-Cluster besteht aus vielen Kafka-Brokern auf vielen Servern. Sie beziehen sich manchmal eher auf ein logisches System oder als Kafka als Ganzes.
Cloudcloud bietet Kafka-Schulungen, Kafka-Beratung, Kafka-Support und hilft beim Einrichten von Kafka-Clustern in AWS.
Kafka-Architektur: Themen, Produzenten und Konsumenten
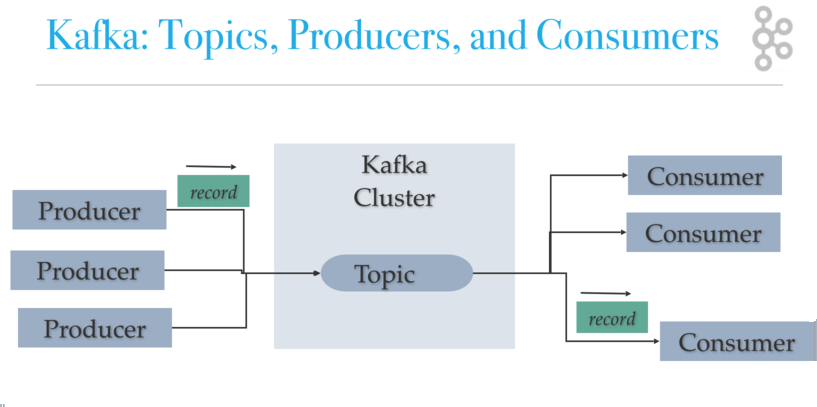
Kafka verwendet ZooKeeper, um den Cluster zu verwalten. ZooKeeper wird verwendet, um die Broker / Cluster-Topologie zu koordinieren. ZooKeeper ist ein konsistentes Dateisystem für Konfigurationsinformationen. ZooKeeper wird für die Führungswahl für Broker- und Partitionsleiter verwendet.
Kafka Architektur: Core Kafka

Kafka benötigt ZooKeeper
Kafka verwendet Zookeeper, um die Wahl von Kafka-Broker- und Themenpartitionspaaren durchzuführen. Kafka verwendet Zookeeper, um die Diensterkennung für Kafka-Broker zu verwalten, die den Cluster bilden. Zookeeper sendet Änderungen der Topologie an Kafka, sodass jeder Knoten im Cluster weiß, wann ein neuer Broker beigetreten ist, ein Broker gestorben ist, ein Thema entfernt oder ein Thema hinzugefügt wurde usw. Zookeeper bietet eine synchrone Ansicht der Kafka-Clusterkonfiguration.
Kafka-Produzent, Verbraucher, Themendetails
Kafka-Produzenten schreiben an Themen. Kafka-Konsumenten lesen aus Themen. Ein Thema ist einem Protokoll zugeordnet, bei dem es sich um eine Datenstruktur auf der Festplatte handelt. Kafka hängt Datensätze von Produzenten an das Ende eines Themenprotokolls an. Ein Themenprotokoll besteht aus vielen Partitionen, die über mehrere Dateien verteilt sind, die auf mehreren Kafka-Clusterknoten verteilt sein können. Verbraucher lesen in ihrer Trittfrequenz aus Kafka-Themen und können im Themenprotokoll auswählen, wo sie sich befinden (versetzt). Jede Verbrauchergruppe verfolgt Offset von wo sie aufgehört zu lesen. Kafka verteilt Themenprotokollpartitionen auf verschiedene Knoten in einem Cluster für hohe Leistung bei horizontaler Skalierbarkeit. Das Verteilen von Partitionen hilft beim schnellen Schreiben von Daten. Themenprotokollpartitionen sind eine Kafka-Methode zum Shard-Lesen und -Schreiben in das Themenprotokoll. Außerdem sind Partitionen erforderlich, damit mehrere Verbraucher in einer Verbrauchergruppe gleichzeitig arbeiten können. Kafka repliziert Partitionen auf viele Knoten, um ein Failover bereitzustellen.
Kafka-Architektur: Themenpartition, Verbrauchergruppe, Offset und Produzenten
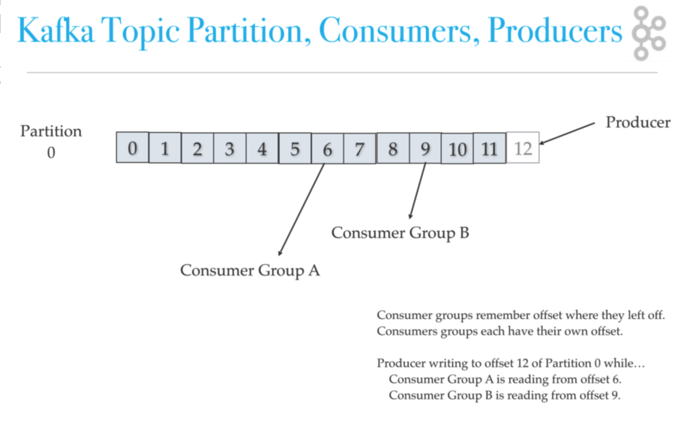
Kafka-Skalierung und -geschwindigkeit
Wie kann Kafka skaliert werden, wenn mehrere Produzenten und Konsumenten gleichzeitig dasselbe Kafka-Themenprotokoll lesen und schreiben? Zuerst ist Kafka schnell, Kafka schreibt sequenziell in das Dateisystem, was schnell ist. Auf einem modernen schnellen Laufwerk kann Kafka problemlos bis zu 700 MB oder mehr Datenbytes pro Sekunde schreiben. Kafka skaliert das Schreiben und Lesen durch Sharding von Themenprotokollen in Partitionen. Denken Sie daran, dass Protokolle in mehrere Partitionen aufgeteilt werden können, die auf mehreren verschiedenen Servern gespeichert werden können, und diese Server können mehrere Festplatten verwenden.Mehrere Produzenten können auf verschiedene Partitionen desselben Themas schreiben. Mehrere Verbraucher aus mehreren Verbrauchergruppen können effizient von verschiedenen Partitionen lesen.
Kafka Brokers
Ein Kafka-Cluster besteht aus mehreren Kafka-Brokern. Jeder Kafka-Broker hat eine eindeutige ID (Nummer).Kafka-Broker enthalten Themenprotokollpartitionen. Durch die Verbindung mit einem Broker wird ein Client mit dem gesamten Kafka-Cluster gestartet.Für das Failover sollten Sie mit mindestens drei bis fünf Brokern beginnen. Ein Kafka-Cluster kann bei Bedarf 10, 100 oder 1.000 Broker in einem Cluster haben.
Kafka Cluster, Failover, ISRs
Kafka unterstützt die Replikation, um Failover zu unterstützen. Denken Sie daran, dass Kafka ZooKeeperto verwendet, um Kafka-Broker zu einem Cluster zu formen, und jeder Knoten im Kafka-Cluster wird als Kafka-Broker bezeichnet.Themenpartitionen können für Failover über mehrere Knoten repliziert werden. Das Thema sollte einen Replikationsfaktor größer als 1 (2 oder 3) haben. Wenn Sie beispielsweise in AWS ausgeführt werden, möchten Sie in der Lage sein, einen einzelnen Availabilityzone-Ausfall zu überstehen.Wenn ein Kafka-Broker ausfällt, kann der Kafka-Broker, der ein ISR (In-Sync Replica) ist, Daten bereitstellen.
Kafka Failover vs. Kafka Disaster Recovery
Kafka verwendet die Replikation für das Failover. Replikation von Kafka-Themenprotokollpartitionenermöglicht den Ausfall eines Racks oder einer AWS Availability Zone (AZ). Sie benötigen einen Replikationsfaktor von mindestens 3, um einen einzelnen AZ-Fehler zu überstehen. Sie müssen Mirror Maker, ein Kafka-Dienstprogramm, das mit Kafka Core ausgeliefert wird, für die Notfallwiederherstellung verwenden. Mirror Makerrepliziert einen Kafka-Cluster in ein anderes Rechenzentrum oder eine andere AWS-Region.Sie nennen das, was Mirror Maker macht, Spiegelung, um nicht mit Replikation verwechselt zu werden.
Beachten Sie, dass es keine feste Regel gibt, wie Sie den Kafka-Cluster an sich einrichten müssen.Sie können beispielsweise den gesamten Cluster in einer einzigen AZ einrichten, sodass Sie AWS Enhanced Networking und Placement Groups für einen höheren Durchsatz verwenden können, und dann Mirror Makerum den Cluster auf eine andere AZ in derselben Region wie ein Hot-Standby zu spiegeln.
Kafka Architektur: Kafka Zookeeper Koordination
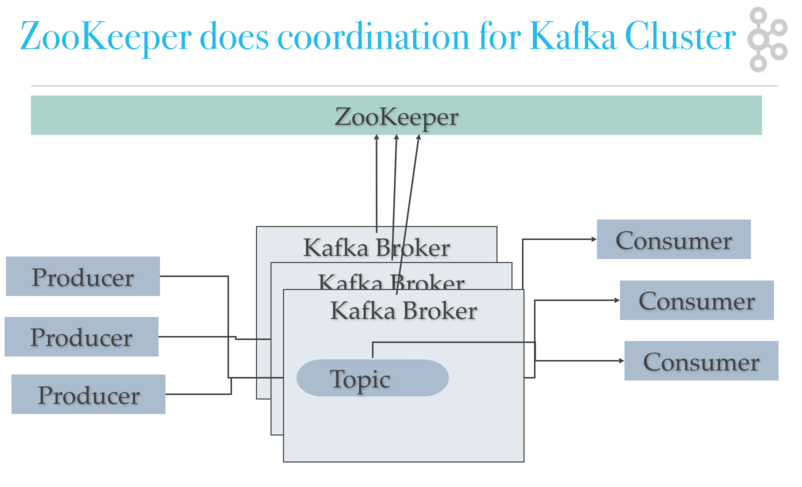
Kafka Topics Architecture
Bitte lesen Sie weiter über Kafka Architecture. Der nächste Artikel behandelt die Kafka-Themenarchitektur mit einer Diskussion darüber, wie Partitionen für Failover und parallele Verarbeitung verwendet werden.
- Was ist Kafka?
- Kafka Architektur
- Kafka Topic Architektur
- Kafka Consumer Architektur
- Kafka Producer Architektur
- Kafka Architektur und Low Level Design
- Kafka und Schema Registry
- Kafka und Avro
- Kafka-Ökosystem
- Kafka gegen JMS
- Kafka gegen Kinesis
- Kafka Tutorial: Verwenden von Kafka über die Befehlszeile
- Kafka-Tutorial: Kafka Broker-Failover und Consumer-Failover
- Kafka-Tutorial
- Kafka-Tutorial: Schreiben eines Kafka Producer-Beispiels in Java
- Kafka-Tutorial: Schreiben eines Kafka Consumer-Beispiels in Java
- Kafka-Architektur: Protokollkomprimierung
- Kafka-Architektur: PDF-Folien auf niedriger Ebene
Über Cloudurable
Wir hoffen, dass Ihnen dieser Artikel gefallen hat. Bitte geben Sie Feedback.Cloudcloud bietet Kafka-Schulungen, Kafka-Beratung, Kafka-Support und hilft beim Einrichten von Kafka-Clustern in AWS.
Schauen Sie sich unseren neuen GoLang-Kurs an. Wir bieten Go Lang-Schulungen vor Ort an, die von Lehrern geleitet werden.
Twittern