Stellen Sie sich ein Tool vor, das JPA- und Hibernate-Leistungsprobleme automatisch erkennt. Hypersistence Optimizer ist das Werkzeug!
Einführung
Wenn Sie sich fragen, warum und wann Sie JPA oder Hibernate verwenden sollten, gibt Ihnen dieser Artikel eine Antwort auf diese sehr häufige Frage. Da ich diese Frage sehr oft auf dem Reddit-Kanal / r / java gesehen habe, habe ich beschlossen, dass es sich lohnt, eine ausführliche Antwort auf die Stärken und Schwächen von JPA und Hibernate zu schreiben.
Obwohl JPA seit seiner ersten Veröffentlichung im Jahr 2006 ein Standard ist, ist dies nicht die einzige Möglichkeit, eine Datenzugriffsschicht mit Java zu implementieren. Wir werden die Vor- und Nachteile der Verwendung von JPA oder anderen beliebten Alternativen diskutieren.
Warum und wann JDBC erstellt wurde
In 1997, Java 1.1 führte die JDBC-API (Java Database Connectivity) ein, die für ihre Zeit sehr revolutionär war, da sie die Möglichkeit bot, die Datenzugriffsschicht einmal über eine Reihe von Schnittstellen zu schreiben und sie in jeder relationalen Datenbank auszuführen, die die JDBC-API implementiert, ohne dass Sie Ihren Anwendungscode ändern müssen.
Die JDBC-API bot eine Connection -Schnittstelle, um die Transaktionsgrenzen zu steuern und einfache SQL-Anweisungen über die Statement -API oder vorbereitete Anweisungen zu erstellen, mit denen Sie Parameterwerte über die PreparedStatement -API binden können.
Angenommen, wir haben eine post -Datenbanktabelle und möchten 100 Zeilen einfügen, können wir dieses Ziel mit JDBC folgendermaßen erreichen:
int postCount = 100;int batchSize = 50;try (PreparedStatement postStatement = connection.prepareStatement(""" INSERT INTO post ( id, title ) VALUES ( ?, ? ) """)) { for (int i = 1; i <= postCount; i++) { if (i % batchSize == 0) { postStatement.executeBatch(); } int index = 0; postStatement.setLong( ++index, i ); postStatement.setString( ++index, String.format( "High-Performance Java Persistence, review no. %1$d", i ) ); postStatement.addBatch(); } postStatement.executeBatch();} catch (SQLException e) { fail(e.getMessage());}
Während wir mehrzeilige Textblöcke und try-with-resources-Blöcke nutzten, um den PreparedStatement close -Aufruf zu eliminieren, ist die Implementierung immer noch sehr ausführlich. Beachten Sie, dass die Bindungsparameter bei 1 beginnen, nicht bei 0, wie Sie es von anderen bekannten APIs gewohnt sind.
Um die ersten 10 Zeilen abzurufen, müssen wir möglicherweise eine SQL-Abfrage über PreparedStatement ausführen, die ein ResultSet zurückgibt, das das tabellenbasierte Abfrageergebnis darstellt. Da Anwendungen jedoch hierarchische Strukturen wie JSON oder DTOs verwenden, um Eltern-Kind-Zuordnungen darzustellen, mussten die meisten Anwendungen JDBC ResultSet in ein anderes Format in der Datenzugriffsschicht umwandeln, wie im folgenden Beispiel veranschaulicht:
int maxResults = 10;List<Post> posts = new ArrayList<>();try (PreparedStatement preparedStatement = connection.prepareStatement(""" SELECT p.id AS id, p.title AS title FROM post p ORDER BY p.id LIMIT ? """)) { preparedStatement.setInt(1, maxResults); try (ResultSet resultSet = preparedStatement.executeQuery()) { while (resultSet.next()) { int index = 0; posts.add( new Post() .setId(resultSet.getLong(++index)) .setTitle(resultSet.getString(++index)) ); } }} catch (SQLException e) { fail(e.getMessage());}
Auch dies ist der schönste Weg, dies mit JDBC zu schreiben, da wir Textblöcke, try-with-resources und eine API im Fluent-Stil verwenden, um die Post -Objekte zu erstellen.
Trotzdem ist die JDBC-API immer noch sehr ausführlich und, was noch wichtiger ist, es fehlen viele Funktionen, die bei der Implementierung einer modernen Datenzugriffsschicht erforderlich sind:
- Eine Möglichkeit, Objekte direkt aus der Abfrageergebnismenge abzurufen. Wie wir im obigen Beispiel gesehen haben, müssen wir die
ReusltSetiterieren und die Spaltenwerte extrahieren, um diePostObjekteigenschaften festzulegen. - Eine transparente Methode zum Stapeln von Anweisungen, ohne den Datenzugriffscode neu schreiben zu müssen, wenn vom Standardmodus ohne Stapelverarbeitung auf Stapelverarbeitung umgeschaltet wird.
- Unterstützung für optimistisches Sperren
- Eine Paginierungs-API, die die zugrunde liegende datenbankspezifische Top-N- und Next-N-Abfragesyntax verbirgt
Warum und wann Hibernate erstellt wurde
1999 veröffentlichte Sun J2EE (Java Enterprise Edition), das eine Alternative zu JDBC namens Entity Beans bot.
Da Entity Beans jedoch notorisch langsam, überkompliziert und umständlich zu verwenden waren, beschloss Gavin King 2001, ein ORM-Framework zu erstellen, das Datenbanktabellen POJOs (Plain Old Java Objects) zuordnen konnte, und so wurde Hibernate geboren.
Da Hibernate leichter als Entity Beans und weniger ausführlich als JDBC war, wurde es immer beliebter und wurde bald zum beliebtesten Java Persistence Framework, das JDO, iBatis, Oracle TopLink und Apache Cayenne gewann.
Warum und wann wurde JPA erstellt?
Nach dem Erfolg des Hibernate-Projekts entschied sich die Java EE-Plattform, die Art und Weise, wie Hibernate und Oracle TopLink standardisiert werden, zu standardisieren, und so wurde JPA (Java Persistence API) geboren.
JPA ist nur eine Spezifikation und kann nicht alleine verwendet werden, da es nur eine Reihe von Schnittstellen bereitstellt, die die Standard-Persistenz-API definieren, die von einem JPA-Anbieter wie Hibernate, EclipseLink oder OpenJPA implementiert wird.
Wenn Sie JPA verwenden, müssen Sie die Zuordnung zwischen einer Datenbanktabelle und dem zugehörigen Java-Entitätsobjekt definieren:
@Entity@Table(name = "post")public class Post { @Id private Long id; private String title; public Long getId() { return id; } public Post setId(Long id) { this.id = id; return this; } public String getTitle() { return title; } public Post setTitle(String title) { this.title = title; return this; }}
Danach können wir das vorherige Beispiel, in dem 100 post Datensätze gespeichert wurden, wie folgt umschreiben:
for (long i = 1; i <= postCount; i++) { entityManager.persist( new Post() .setId(i) .setTitle( String.format( "High-Performance Java Persistence, review no. %1$d", i ) ) );}
Um JDBC-Batch-Einfügungen zu aktivieren, müssen wir nur eine einzige Konfigurationseigenschaft bereitstellen:
<property name="hibernate.jdbc.batch_size" value="50"/>
Sobald diese Eigenschaft bereitgestellt wurde, kann Hibernate automatisch von Nicht-Batching zu Batching wechseln, ohne dass der Datenzugriffscode geändert werden muss.
Und um die ersten 10 post Zeilen abzurufen, können wir die folgende JPQL-Abfrage ausführen:
int maxResults = 10;List<Post> posts = entityManager.createQuery(""" select p from post p order by p.id """, Post.class).setMaxResults(maxResults).getResultList();
Wenn Sie dies mit der JDBC-Version vergleichen, werden Sie feststellen, dass JPA viel einfacher zu verwenden ist.
Die Vor- und Nachteile der Verwendung von JPA und Hibernate
JPA im Allgemeinen und Hibernate im Besonderen bieten viele Vorteile.
- Sie können Entitäten oder DTOs abrufen. Sie können sogar eine hierarchische Eltern-Kind-DTO-Projektion abrufen.
- Sie können das JDBC-Batching aktivieren, ohne den Datenzugriffscode zu ändern.
- Sie haben Unterstützung für optimistisches Sperren.
- Sie verfügen über eine pessimistische Sperrabstraktion, die unabhängig von der zugrunde liegenden datenbankspezifischen Syntax ist, sodass Sie eine LESE- und SCHREIBSPERRE oder sogar eine SKIP-SPERRE erhalten können.
- Sie haben eine datenbankunabhängige Paginierungs-API.
- Sie können eine
Listvon Werten für eine IN query-Klausel bereitstellen, wie in diesem Artikel erläutert. - Sie können eine stark konsistente Caching-Lösung verwenden, mit der Sie den primären Knoten auslagern können, der für Rea-Write-Transaktionen nur vertikal aufgerufen werden kann.
- Sie haben integrierte Unterstützung für die Überwachungsprotokollierung über Hibernate Envers.
- Sie haben integrierte Unterstützung für Mandantenfähigkeit.
- Sie können ein initiales Schema-Skript aus den Entitätszuordnungen mit dem Hibernate hbm2ddl-Tool generieren, das Sie einem automatischen Schema-Migrationstool wie Flyway zur Verfügung stellen können.
- Sie haben nicht nur die Freiheit, eine beliebige native SQL-Abfrage auszuführen, sondern können auch das SqlResultSetMapping verwenden, um JDBC
ResultSetin JPA-Entitäten oder DTOs umzuwandeln.
Die Nachteile der Verwendung von JPA und Hibernate sind die folgenden:
- Der Einstieg in JPA ist zwar sehr einfach, aber ein Experte zu werden erfordert eine erhebliche Zeitinvestition, da Sie neben dem Lesen des Handbuchs noch lernen müssen, wie Datenbanksysteme funktionieren, den SQL-Standard sowie die spezifische SQL-Variante, die von Ihrer projektbezogenen Datenbank verwendet wird.
- Es gibt einige weniger intuitive Verhaltensweisen, die Anfänger überraschen könnten, wie die Reihenfolge der Spülvorgänge.
- Die Kriterien-API ist ziemlich ausführlich, daher müssen Sie ein Tool wie Codota verwenden, um dynamische Abfragen einfacher zu schreiben.
Die gesamte Community und beliebte Integrationen
JPA und Hibernate sind sehr beliebt. Laut dem 2018 Java Ecosystem Report von Snyk wird Hibernate von 54% aller Java-Entwickler verwendet, die mit einer relationalen Datenbank interagieren.
Dieses Ergebnis kann von Google Trends unterstützt werden. Wenn wir beispielsweise die Google Trends von JPA mit seinen Hauptkonkurrenten (z. B. MyBatis, QueryDSL und jOOQ) vergleichen, können wir feststellen, dass JPA um ein Vielfaches beliebter ist und keine Anzeichen dafür zeigt, dass es seine dominante Marktanteilsposition verliert.

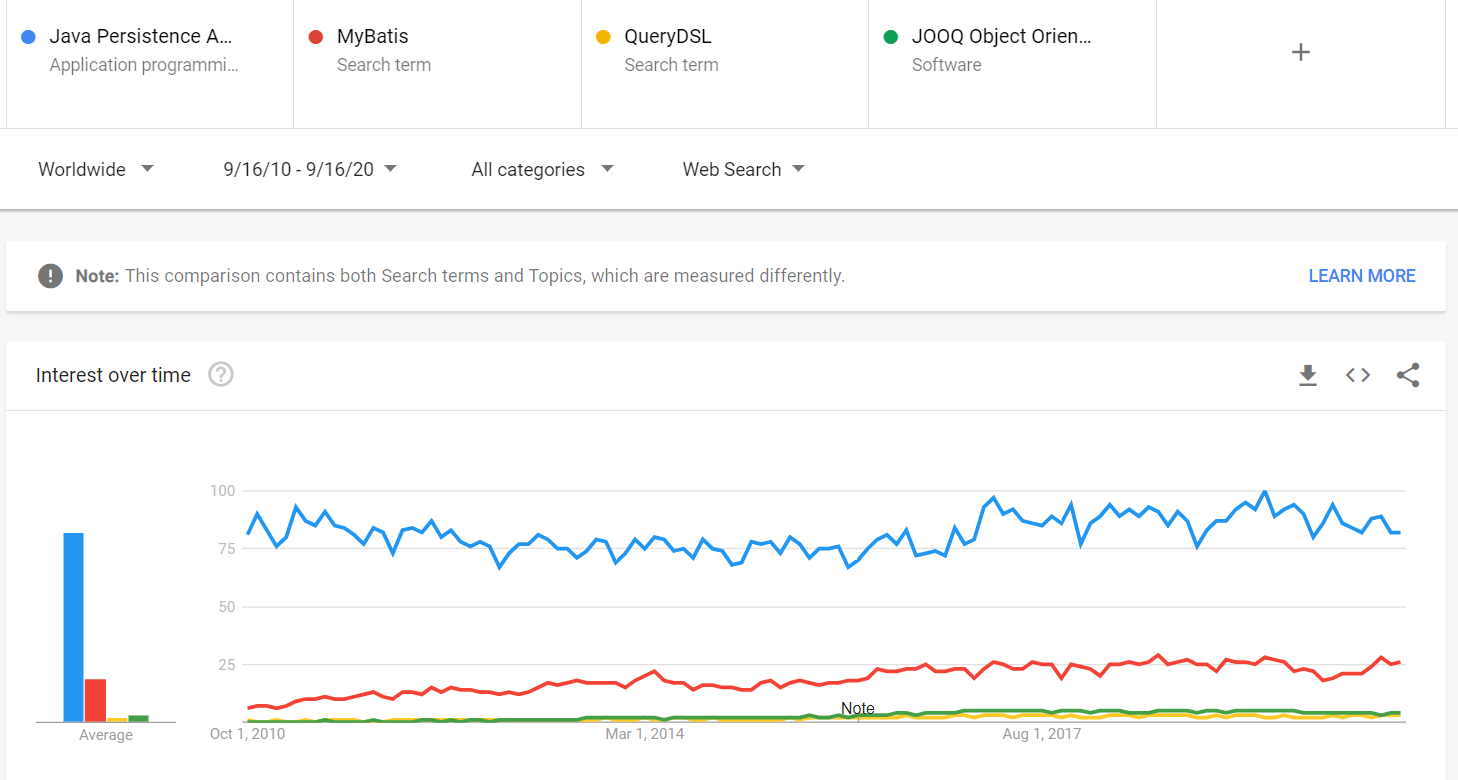
So beliebt zu sein, bringt viele Vorteile, wie:
- Die Spring Data JPA-Integration funktioniert wie ein Zauber. Einer der Hauptgründe, warum JPA und Hibernate so beliebt sind, ist, dass Spring Boot Spring Data JPA verwendet, das wiederum Hibernate hinter den Kulissen verwendet.
- Wenn Sie ein Problem haben, besteht eine gute Chance, dass diese 30k Hibernate-bezogenen StackOverflow-Antworten und 16k JPA-bezogenen StackOverflow-Antworten Ihnen eine Lösung bieten.
- Es sind 73k Hibernate Tutorials verfügbar. Allein meine Website bietet über 250 JPA- und Hibernate-Tutorials, in denen Sie lernen, wie Sie JPA und Hibernate optimal nutzen können.
- Es gibt viele Videokurse, die Sie auch verwenden können, wie mein Hochleistungs-Java-Persistenz-Videokurs.
- Es gibt über 300 Bücher über Hibernate auf Amazon, von denen eines auch mein Hochleistungs-Java-Persistenzbuch ist.
JPA-Alternativen
Eines der größten Dinge am Java-Ökosystem ist die Fülle hochwertiger Frameworks. Wenn JPA und Hibernate nicht gut zu Ihrem Anwendungsfall passen, können Sie eines der folgenden Frameworks verwenden:
- MyBatis, das ist ein sehr leichtes SQL Query Mapper Framework.
- QueryDSL, mit dem Sie SQL-, JPA-, Lucene- und MongoDB-Abfragen dynamisch erstellen können.
- jOOQ, das ein Java-Metamodell für die zugrunde liegenden Tabellen, gespeicherten Prozeduren und Funktionen bereitstellt und es Ihnen ermöglicht, eine SQL-Abfrage dynamisch mit einem sehr intuitiven DSL und typsicher zu erstellen.
Verwenden Sie also das, was für Sie am besten geeignet ist.
Online-Workshops
Wenn Ihnen dieser Artikel gefallen hat, werden Sie meinen bevorstehenden 4-tägigen x 4-stündigen Hochleistungs-Java-Persistenz-Online-Workshop lieben

Fazit
In diesem Artikel haben wir gesehen, warum JPA erstellt wurde und wann Sie es verwenden sollten. Während JPA viele Vorteile mit sich bringt, stehen Ihnen viele andere hochwertige Alternativen zur Verfügung, wenn JPA und Hibernate für Ihre aktuellen Anwendungsanforderungen nicht am besten geeignet sind.
Und manchmal, wie ich in diesem kostenlosen Beispiel meines Hochleistungs-Java-Persistenzbuchs erklärt habe, müssen Sie nicht einmal zwischen JPA oder anderen Frameworks wählen. Sie können JPA einfach mit einem Framework wie jOOQ kombinieren, um das Beste aus beiden Welten zu erhalten.



