Comenzamos mirando la regresión lineal/de cresta de forma dual, antes de mostrar cómo ‘kernelizarla’. Al explicar esto último, veremos qué son los núcleos y cuál es el ‘truco del núcleo’.
Regresión de Cresta de forma dual
La regresión lineal se da típicamente en forma primaria como una combinación lineal de columnas (características). Sin embargo, existe una segunda forma dual en la que es una combinación lineal del producto interno de un nuevo dato (sobre el que estamos realizando inferencias) con cada uno de los datos de entrenamiento.
Consideramos el caso de regresión de cresta (regresión lineal regularizada L2), recordando que la regresión lineal básica corresponde al caso donde \(\lambda = 0\). A continuación, las fórmulas para la regresión de crestas, donde \(X\) y \(Y\) se refieren a los datos de entrenamiento \(n \times m\) y \(x^\prime,y^\prime\) un nuevo caso a estimar, son:
\ \ \ \
Donde \(\langle X_i,x^\prime \rangle\) es el interior de/dot producto, por lo que \(\langle X_i,x^\prime \rangle = X^T_i x^\prime = \sum_j^m X_{i,j} x^\prime_j\).
La forma dual muestra que la regresión lineal/cresta también puede entenderse como una estimación de una suma ponderada del producto interno de un nuevo caso con cada uno de los casos de entrenamiento.
Significa que podemos hacer regresión lineal incluso cuando hay más columnas que filas, aunque la importancia de esto puede exagerarse ya que (i) podemos hacerlo de todos modos a través del uso de la regularización L2, ya que esto siempre hace que la matriz \(X^TX\) sea invertible; y (ii) la matriz \(XX^T\) a menudo puede requerir la regularización L2 de todos modos para garantizar la estabilidad numérica de la inversión. También nos permite ver la regresión lineal como un proceso de aprendizaje secuencial, donde cada dato adicional en los datos de entrenamiento aporta algo nuevo.
Lo más importante para nuestros propósitos, sin embargo, la forma dual tiene la característica interesante: los vectores de características se producen en las ecuaciones solo dentro de productos internos. Esto es cierto incluso en la definición de \(\alpha\), ya que \(XX^T\) produce la matriz correspondiente a los productos internos de cada par de vectores de entidades en los datos de entrenamiento. Veremos la importancia de esto a medida que avancemos.
Aparte: Los estudiantes interesados pueden ver cómo se derivó el formulario dual en la Derivación del documento de Formulario Dual disponible en la sección de descargas al final de este artículo.
Regresión de cresta dual no lineal
Podemos convertir nuestra regresión de cresta de forma dual en un modelo no lineal mediante el método estándar de usar transformaciones de entidad no lineales \(\phi\):
\ \
Funciones del núcleo
Una función del núcleo, \(K: \mathcal X \times \mathcal X \to \mathbb{R}\), es una función simétrica – \(K(x_1,x_2)=K(x_2,x_1)\) – y definida positiva (véase el apartado para una definición formal). La definición positiva se utiliza en las matemáticas que justifica el uso de núcleos. Pero sin un conocimiento matemático significativo, la definición no es intuitivamente esclarecedora. Así que en lugar de intentar entender los núcleos a partir de la definición de definición positiva, los presentaremos con una serie de ejemplos.
Antes de hacer esto, notamos que aunque los núcleos son funciones de dos argumentos, es común pensar que están ubicados en su primer argumento, y que son una función de su segundo. De acuerdo con esta interpretación verá la notación como \(K_x(y)\), que es equivalente a \(K(x,y)\) . En particular, a menudo pensaremos que los núcleos son funciones de argumento único ‘ubicadas’ en puntos de datos (vectores de características) en nuestros datos de entrenamiento. A veces leerá de nosotros’ soltando ‘ núcleos en puntos de datos. Por lo tanto , si tenemos un vector de entidad \(x_i\), colocaríamos un núcleo en él,lo que llevaría a la función \(K_{x_i}(x)\) ubicada en \(x_i\) y equivalente a \(K(x_i, x)\) .
También observamos que los núcleos a menudo se especifican como miembros de familias paramétricas. Ejemplos de tales familias de núcleos incluyen:
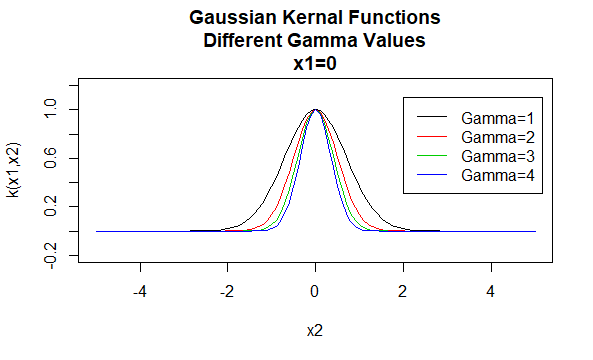
Núcleos gaussianos
Los núcleos gaussianos son un ejemplo de núcleos de función de base radial y a veces se llaman núcleos de base radial. El valor de un núcleo de función de base radial depende solo de la distancia entre los vectores de argumentos, en lugar de su ubicación. Tales granos también se denominan estacionarios.
Parámetros: \(\gamma\)
Forma de ecuación: \(K (X_1,X_2) = e^{- \gamma | / X_1-X_2 \|^2}\)
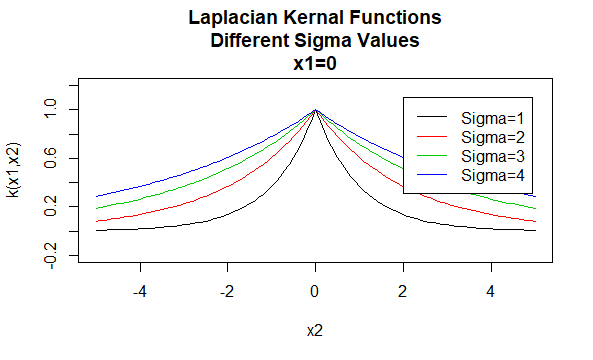
Núcleos laplacianos
Los núcleos laplacianos también son funciones de base radial.
Parámetros: \(\sigma\)
Forma de ecuación: \(K (X_1, X_2) = e^{-\frac{\| X_1 – X_2 \|}{\sigma}}\)
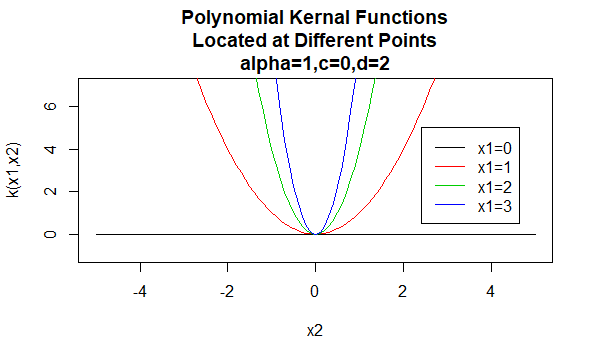
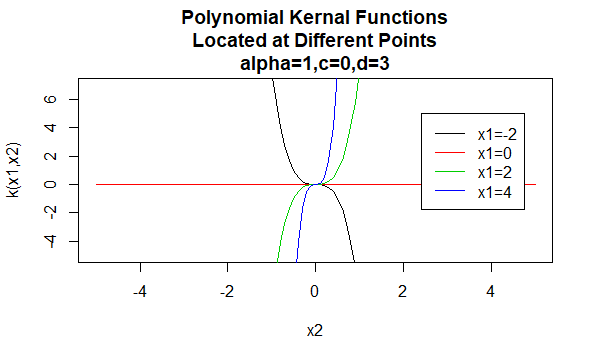
Núcleos polinómicos
Los núcleos polinómicos son un ejemplo de núcleos no estacionarios. Por lo tanto, estos núcleos asignarán diferentes valores a pares de puntos que comparten la misma distancia, en función de sus valores. Los valores de los parámetros deben ser no negativos para asegurar que estos núcleos sean positivos definidos.
Parámetros: \(\alpha, c, d\)
Forma de ecuación: \(K(X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
Especificar valores particulares para los parámetros de una familia de núcleos da como resultado una función de núcleo. A continuación se muestran ejemplos de funciones de núcleos de las familias anteriores con valores de parámetros particulares ubicados en diferentes puntos (es decir, el gráfico trazado es una función del segundo argumento, con el primer argumento establecido en un valor específico).
Aparte: Los estudiantes interesados pueden ver la definición de definición positiva para núcleos en el documento Kernels and Positive Definiteness disponible en la sección de descargas al final de este artículo.
El truco del núcleo
La importancia de las funciones del núcleo proviene de una propiedad muy especial: Cada núcleo positivo definido, \(K\) está relacionado con un espacio matemático, \(\mathcal{H}_K\), (conocido como el espacio de Hilbert del núcleo de reproducción(RKHS) del núcleo) de tal manera que aplicar\ (K\) a dos vectores de entidades,\ (X_1,X_2\) es equivalente a proyectar estos vectores de entidades en \(\mathcal{H}_K\) mediante alguna función de proyección, \(\phi\) y tomar su producto interno allí:
\
Los RKHSs asociados con los núcleos son típicamente de alta dimensión. Para algunos núcleos, como los núcleos de la familia gaussiana, son de dimensión infinita.
Lo anterior es la base del famoso «truco del núcleo»: Si las entidades de entrada están involucradas en la ecuación de un modelo estadístico solo en forma de productos internos, entonces podemos reemplazar los productos internos en la ecuación con llamadas a la función del núcleo y el resultado es como si hubiéramos proyectado las entidades de entrada en un espacio dimensional superior (es decir, realizado una transformación de entidades que conduce a un gran número de entidades variables latentes) y llevado su producto interno allí. Pero nunca necesitamos realizar la proyección real.
En terminología de aprendizaje automático, los RKHS asociados con el núcleo se conocen como espacio de entidades, en oposición al espacio de entrada. A través del truco del núcleo, proyectamos implícitamente las características de entrada en este espacio de características y llevamos su producto interno allí.
Regresión del núcleo
Esto conduce a la técnica conocida como regresión del núcleo. Es simplemente una aplicación del truco del núcleo a la forma dual de regresión de cresta. Para mayor facilidad, introducimos la idea del Núcleo, o Gramo, matriz, \(K\), de modo que \(K_{i,j}=k(X_i,X_j)\). Luego podemos escribir las ecuaciones para la regresión del núcleo como:
\ \
Donde \(k\) es una función de núcleo definida positiva.
El Teorema del Representador
Considere el problema de optimización que buscamos resolver al realizar la regularización L2 para un modelo de alguna forma, \(f\):
\
Al realizar la regresión del núcleo con kernel \(k\), un resultado importante de la teoría de regularización es que el minimizador de la ecuación anterior será de la forma:
\
Con\ (\alpha\) calculado como se describe anteriormente.
Este es el Teorema del Representador justamente lionizado. En palabras, dice que el minimizador del problema de optimización para la regresión lineal en el espacio de entidades implícito obtenido por un núcleo en particular (y por lo tanto el minimizador del problema de regresión del núcleo no lineal) se dará por una suma ponderada de núcleos ‘ubicados’ en cada vector de entidades.
Hay mucho más que decir sobre este tema. Incluso podemos averiguar qué función verde (de qué núcleos son un subconjunto) minimizará las especificaciones de regularización particulares, como la regularización L2, pero también cualquier penalización basada en un operador diferencial lineal. Esta relación entre los núcleos y las soluciones óptimas a los problemas de regularización de Tikhonov es una razón principal de la importancia de los métodos de núcleo en el aprendizaje automático. Pero las matemáticas aquí van más allá de este curso, y los estudiantes avanzados interesados se remiten al capítulo siete de las Redes Neuronales y Máquinas de Aprendizaje de Haykin.
Esto nos da una justificación matemática para usar la regresión del núcleo en los casos en que es posible hacerlo. En realidad, no es posible determinar el núcleo óptimo para usar, ya que se requiere conocer el operador diferencial lineal óptimo que se debe usar para la penalización de regularización. Las funciones que debemos proyectar para optimizar las penalizaciones de regularización particulares se han calculado, y sabemos, por ejemplo, que el núcleo de spline de placa delgada es óptimo para la regularización L2. En el lado negativo, ya que necesitamos calcular la matriz de Gram, la regresión del núcleo no se escala bien: para grandes conjuntos de datos, recurrir a redes neuronales es una mejor idea.