Tweet
Si no está seguro de qué es Kafka, consulte ¿Qué es Kafka?.
- Arquitectura Kafka
- Arquitectura Kafka: Temas, Productores y Consumidores
- Arquitectura de Kafka: Core Kafka
- Kafka necesita ZooKeeper
- Productor, Consumidor, Detalles del tema de Kafka
- Arquitectura Kafka: Partición temática, Grupo de consumidores, Offset y Productores
- Escala y velocidad de Kafka
- Corredores de Kafka
- El clúster de Kafka, Conmutación por error, ISRs
- Conmutación por error de Kafka vs. Recuperación ante desastres de Kafka
- Kafka Arquitectura: Kafka Cuidador Coordinación
- Kafka Temas de Arquitectura
- Acerca de Cloudurable
Arquitectura Kafka
Kafka consta de Registros, Temas, Consumidores, Productores, Corredores, Registros, Particiones y Clústeres. Los registros pueden tener clave (opcional), valor y marca de tiempo. Los registros de Kafka son inmutables. Un tema de Kafka es un flujo de registros ("/orders", "/user-signups"). Puedes pensar en un Tema como un nombre de fuente. Un tema tiene un registro que es el almacenamiento del tema en el disco. Un registro de temas se divide en particiones y segmentos. La API de Kafka Producer se utiliza para producir flujos de registros de datos. La API de consumo de Kafka se utiliza para consumir un flujo de registros de Kafka. Un Broker es un servidor Kafka que se ejecuta en un clúster de Kafka. Los corredores de Kafka forman un grupo. El clúster de Kafka consta de muchos corredores de Kafka en muchos servidores. Broker a veces se refiere más a un sistema lógico o como Kafka en su conjunto.
Cloudurable proporciona capacitación en Kafka, consultoría en Kafka, soporte de Kafka y ayuda a configurar clústeres de Kafka en AWS.
Arquitectura Kafka: Temas, Productores y Consumidores
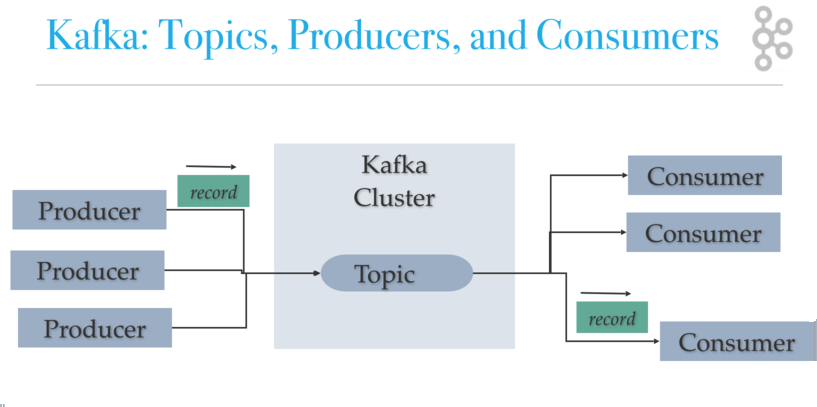
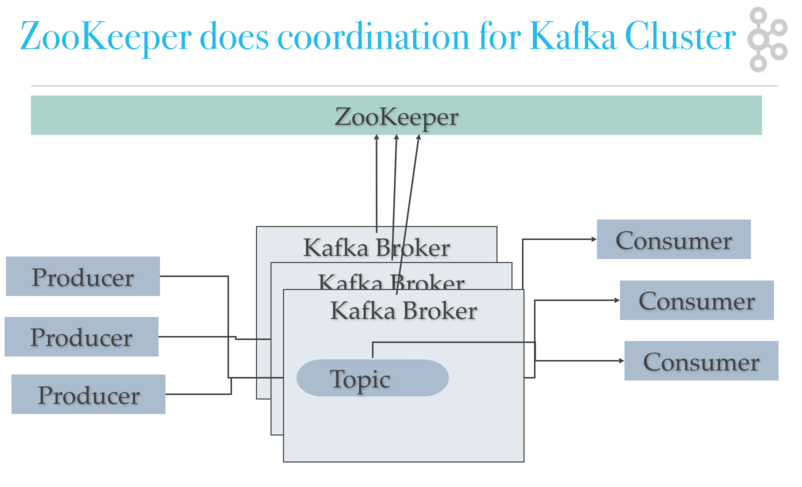
Kafka utiliza ZooKeeper para administrar el clúster. ZooKeeper se utiliza para coordinar la topología de corredores/clústeres. ZooKeeper es un sistema de archivos consistente para información de configuración. ZooKeeper se utiliza para la elección de liderazgo para Líderes de Particiones de Temas de Corredores.
Arquitectura de Kafka: Core Kafka

Kafka necesita ZooKeeper
Kafka usa Zookeeper para hacer la elección de liderazgo de los pares de Particiones de Broker y Topic de Kafka. Kafka utiliza Zookeeper para administrar la detección de servicios para los agentes de Kafka que forman el clúster. Zookeeper envía cambios de la topología a Kafka, para que cada nodo del clúster sepa cuándo se unió un nuevo agente, cuándo murió un agente, cuándo se eliminó un tema o cuándo se agregó un tema, etc. Zookeeper proporciona una vista sincronizada de la configuración del clúster de Kafka.
Productor, Consumidor, Detalles del tema de Kafka
Los productores de Kafka escriben a los temas. Los consumidores de Kafka leen Temas. Un tema está asociado a un registro que es una estructura de datos en disco. Kafka añade registros de un productor al final de un registro de temas. Un registro de temas consta de muchas particiones repartidas en varios archivos que se pueden repartir en varios nodos de clúster de Kafka. Los consumidores leen temas de Kafka a su ritmo y pueden elegir dónde están (offset) en el registro de temas. Cada grupo de consumidores rastrea el desplazamiento desde donde dejaron la lectura. Kafka distribuye particiones de registro de temas en diferentes nodos de un clúster para un alto rendimiento con escalabilidad horizontal. La distribución de particiones ayuda a escribir datos rápidamente. Las particiones de registro de temas son una forma Kafka de dividir lecturas y escrituras en el registro de temas. Además, se necesitan particiones para tener varios consumidores en un grupo de consumidores trabajando al mismo tiempo. Kafka replica particiones en muchos nodos para proporcionar conmutación por error.
Arquitectura Kafka: Partición temática, Grupo de consumidores, Offset y Productores
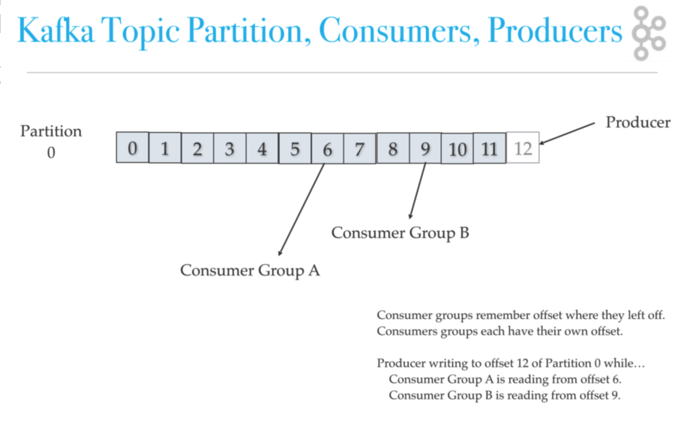
Escala y velocidad de Kafka
¿Cómo puede escalar Kafka si varios productores y consumidores leen y escriben en el mismo registro de temas de Kafka al mismo tiempo? Primero Kafka es rápido, Kafka escribe en el sistema de archivos secuencialmente, lo que es rápido. En una unidad moderna y rápida, Kafka puede escribir fácilmente hasta 700 MB o más bytes de datos por segundo. Kafka escala las escrituras y lecturas dividiendo los registros de temas en particiones. Los registros de temas de recuperación se pueden dividir en varias particiones que se pueden almacenar en varios servidores diferentes, y esos servidores pueden usar varios discos.Varios productores pueden escribir en diferentes particiones del mismo tema. Varios consumidores de varios grupos de consumidores pueden leer de diferentes particiones de manera eficiente.
Corredores de Kafka
Un clúster de Kafka está formado por varios corredores de Kafka. Cada corredor de Kafka tiene un ID (número) único.Los brokers Kafka contienen particiones de registro de temas. La conexión a un agente arranca un cliente a todo el clúster de Kafka.Para la conmutación por error, debe comenzar con al menos de tres a cinco corredores. Un clúster de Kafka puede tener, de ser necesario, 10, 100 o 1000 corredores en un clúster.
El clúster de Kafka, Conmutación por error, ISRs
Kafka admite la replicación para admitir la conmutación por error. Recuerde que Kafka utiliza Zookeperpara formar Corredores de Kafka en un clúster y cada nodo en el clúster de Kafka se denomina Corredor de Kafka.Las particiones de temas se pueden replicar en varios nodos para la conmutación por error. El tópico debe tener un factor de replicación mayor que 1 (2 o 3). Por ejemplo,si se está ejecutando en AWS, le gustaría poder sobrevivir a una única interrupción de availabilityzone.Si un Bróker Kafka cae, entonces el Bróker Kafka, que es un ISR (réplica sincronizada), puede servir datos.
Conmutación por error de Kafka vs. Recuperación ante desastres de Kafka
Kafka utiliza la replicación para la conmutación por error. La replicación de las particiones de registro de temas de Kafka permite el fallo de un bastidor o de una zona de disponibilidad de AWS (AZ). Se necesita un factor de replicación de al menos 3 para sobrevivir a una sola falla AZ. Necesita usar Mirror Maker, una utilidad Kafka que se incluye con Kafka Core, para la recuperación ante desastres. Mirror Makerreplica un clúster de Kafka a otro centro de datos o región de AWS.Ellos llaman a lo que Mirror Maker hace la duplicación como algo que no debe confundirse con la replicación.
Tenga en cuenta que no hay una regla estricta sobre cómo debe configurar el clúster de Kafka per se.Por ejemplo, puede configurar todo el clúster en una sola zona de disponibilidad para poder utilizar redes mejoradas y grupos de colocación para un mayor rendimiento y, a continuación, utilizar Mirror Makepara reflejar el clúster en otra zona de disponibilidad en la misma región que un modo de espera en caliente.
Kafka Arquitectura: Kafka Cuidador Coordinación
Kafka Temas de Arquitectura
por Favor, continúe leyendo acerca de Kafka Arquitectura. El siguiente artículo cubre la arquitectura de temas de Kafka Con una discusión sobre cómo se usan las particiones para el procesamiento por error y en paralelo.
- ¿Qué es Kafka?
Kafka Arquitectura Kafka Tema de la Arquitectura Kafka Consumidor Arquitectura Kafka Productor de la Arquitectura Kafka, la Arquitectura y el bajo nivel de diseño Kafka y el Esquema de Registro Kafka y Avro Kafka Ecosistema Kafka vs JMS Kafka frente Kinesis Kafka Tutorial: El uso de Kafka desde la línea de comandos Kafka Tutorial: Kafka Corredor de Conmutación por error y el Consumo de Conmutación por error Kafka Tutorial Kafka Tutorial: cómo Escribir un Kafka Productor ejemplo en Java Kafka Tutorial: cómo Escribir un Kafka Consumidor de ejemplo en Java Kafka Arquitectura: Registro de Compactación Kafka Arquitectura: Bajo Nivel de Diapositivas PDF
Acerca de Cloudurable
esperamos que haya disfrutado de este artículo. Por favor, proporcione sus comentarios.Cloudurable proporciona capacitación en Kafka, consultoría en Kafka, soporte de Kafka y ayuda a configurar clústeres de Kafka en AWS.
Echa un vistazo a nuestro nuevo campo de GoLang. Ofrecemos capacitación en el lugar de Go Lang, dirigida por un instructor.
Tweet