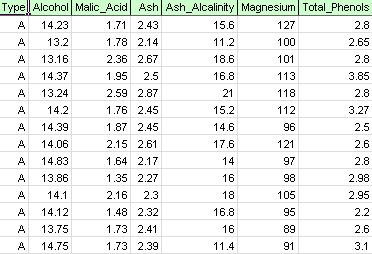
En la cinta XLMiner, en la pestaña Aplicar su modelo, seleccione Help-Examples, luego Forecasting / Data Mining Examples y abra el archivo de ejemplo Wine.xlsx. Como se muestra en la figura siguiente, cada fila de este conjunto de datos de ejemplo representa una muestra de vino tomada de una de las tres bodegas (A, B o C). En este ejemplo, se ignora la variable de Tipo que representa la bodega, y el agrupamiento se realiza simplemente sobre la base de las propiedades de las muestras de vino (las variables restantes).
Seleccione una celda dentro del conjunto de datos y, a continuación, en la cinta XLMiner, en la ficha Análisis de datos, seleccione Agrupación en clúster XLMiner – Cluster – k-Means para abrir el cuadro de diálogo Paso 1 de 3 de Agrupación en clúster de k-Means.
En la lista de variables, seleccione todas las variables excepto Tipo y, a continuación, haga clic en el botón > para mover las variables seleccionadas a la lista de variables seleccionadas.
Haga clic en Siguiente para avanzar al diálogo del Paso 2 de 3.
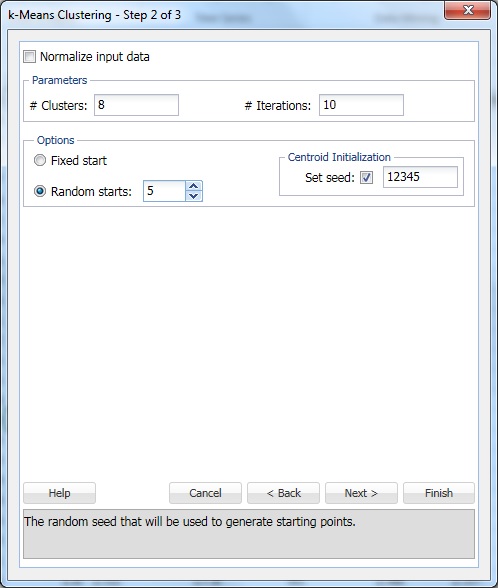
En # Clusters, ingrese 8. Este es el parámetro k en el algoritmo de agrupamiento de k-means. El número de grupos debe ser de al menos 1 y, como máximo, el número de observaciones -1 en el intervalo de datos. Establezca k en varios valores diferentes y evalúe la salida de cada uno.
Deje # Iteraciones en la configuración predeterminada de 10. El valor de esta opción determina cuántas veces el programa comenzará con una partición inicial y completará el algoritmo de agrupación en clústeres. La configuración de clústeres (y la separación de datos) puede diferir de una partición inicial a otra. El programa revisará el número de iteraciones especificado y seleccionará la configuración del clúster que minimiza la medida de distancia.
Establecer inicios aleatorios en 5. Cuando se selecciona esta opción, el algoritmo comienza a construir el modelo desde cualquier punto aleatorio. XLMiner genera cinco conjuntos de clústeres y genera la salida basada en el mejor clúster.
Set seed está seleccionado de forma predeterminada. Esta opción inicializa el generador de números aleatorios que se utiliza para calcular los centroides iniciales del clúster. Establecer la semilla de números aleatorios en un valor distinto de cero (predeterminado 12345) garantiza que se use la misma secuencia de números aleatorios cada vez que se calculen los centroides iniciales del clúster. Cuando la semilla es cero, el generador de números aleatorios se inicializa desde el reloj del sistema, por lo que la secuencia de números aleatorios es diferente cada vez que se inicializan los centroides. Establezca la semilla para ver las ejecuciones sucesivas del método de agrupación en clústeres como comparables.
Seleccione la opción Normalizar datos de entrada para normalizar los datos. En este ejemplo, los datos no se normalizarán. Seleccione Siguiente para abrir el cuadro de diálogo Paso 3 de 3.
Seleccione Mostrar resumen de datos (predeterminado) y Mostrar distancias desde cada centro de clúster (predeterminado) y, a continuación, haga clic en Finalizar.
El método de Clustering de k-Means comienza con k clusters iniciales como se especifica. En cada iteración, los registros se asignan al clúster con el centroide o centro más cercano. Después de cada iteración, se calcula la distancia desde cada registro hasta el centro del clúster. Estos dos pasos se repiten (la asignación de registros y el cálculo de la distancia) hasta que la redistribución de un registro da como resultado un mayor valor de distancia.
Cuando se especifica un inicio aleatorio, el algoritmo genera aleatoriamente los centros de clúster k y ajusta los puntos de datos de esos clústeres. Este proceso se repite para todos los inicios aleatorios especificados. La salida se basa en los clústeres que exhiben el mejor ajuste.
La hoja de trabajo KM_Output1 se inserta inmediatamente a la derecha de la hoja de datos. En la sección superior de la hoja de trabajo de salida, se enumeran las opciones seleccionadas.
En la sección central de la hoja de trabajo de salida, XLMiner ha calculado la suma de las distancias cuadradas y determinado el inicio con la Suma más baja de la Distancia Cuadrada como el Mejor Inicio (#5). Después de determinar el Mejor Inicio, XLMiner genera la salida restante utilizando el Mejor Inicio como punto de partida.
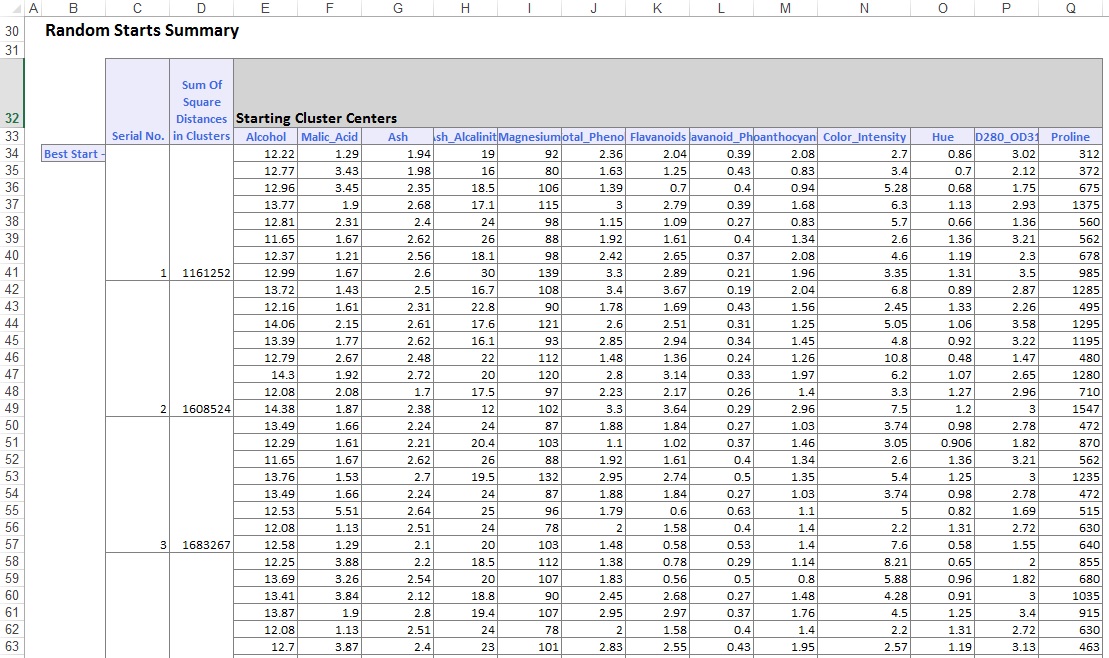
En la parte inferior de la hoja de trabajo de salida, XLMiner ha enumerado los Centros de clúster (que se muestran a continuación). El cuadro superior muestra los valores de las variables en los centros del clúster. El grupo 8 tiene el contenido promedio más alto de Alcohol, fenoles totales, Flavanoides, proantocianinas, Intensidad de color, Tonalidad y Prolina. Compare este clúster con el clúster 2, que tiene el promedio más alto de Ash_Alcalinity y Nonflavanoid_Phenols.
El cuadro inferior muestra la distancia entre los centros del clúster. A partir de los valores de esta tabla, se determina que el Clúster 3 es muy diferente del Clúster 8 debido al valor de alta distancia de 1,176.59, y el Clúster 7 está cerca del Clúster 3 con un valor de baja distancia de 89.73.
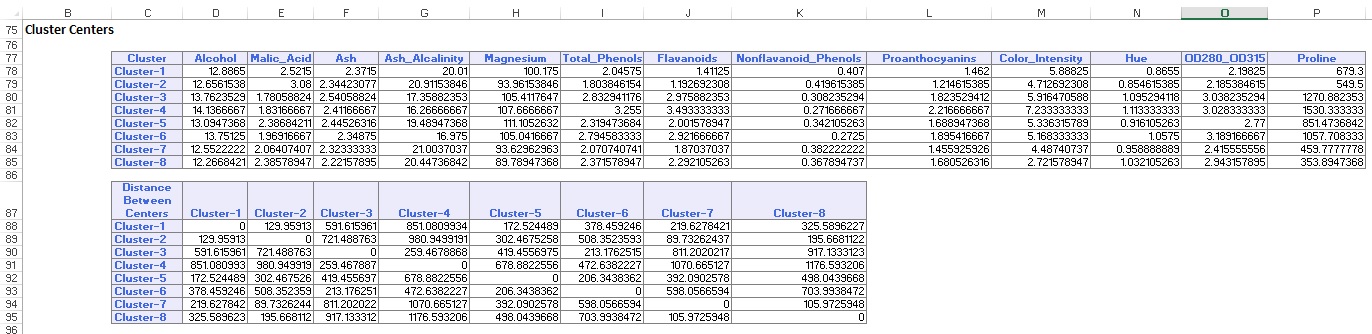
El resumen de datos (a continuación) muestra el número de registros (observaciones) incluidos en cada clúster y la distancia media entre los miembros del clúster y el centro de cada clúster. El clúster 6 tiene la distancia media más alta de 42,79, e incluye 24 registros. Compare este clúster con el clúster 2, que tiene la distancia media más pequeña de 29,66, e incluye 26 miembros.
Haga clic en la hoja de trabajo KM_Clusters1. Esta hoja de trabajo muestra el clúster al que se asigna cada registro y la distancia a cada uno de los clústeres. Para el primer registro, la distancia al clúster 6 es la distancia mínima de 23.205, por lo que este primer registro se asigna al Clúster 6.