aloitamme tarkastelemalla dual-form linear / ridge regressiota, ennen kuin näytämme, miten ”kernelize” sitä. Kun selitämme jälkimmäistä, näemme, mitä ytimet ovat ja mikä ’ytimen temppu’ on.
kaksimuotoinen Ridge-regressio
lineaarinen regressio esitetään tyypillisesti siinä primaarimuodossa sarakkeiden (ominaisuuksien) lineaarisena yhdistelmänä. On kuitenkin olemassa toinen, duaalimuoto, jossa se on lineaarinen yhdistelmä uuden datumin sisätulosta (josta teemme päätelmiä) jokaisen harjoitustiedon kanssa.
tarkastelemme ridge-regression tapausta (L2 regularisoitu lineaarinen regressio), muistaen, että lineaarinen perusregressio vastaa tapausta, jossa \(\lambda = 0\). Sitten Ridge-regression kaavat, joissa \(X\) ja \(Y\) viittaavat \(n \times m\) harjoitustietoihin ja \(x^ \ prime, y^\prime\) Uusi estimoitava tapaus ovat:
\ \ \ \
missä \(\langle X_i, x^\prime \rangle\) on sisempi/pistetulo, joten \(\langle X_i,x^\prime \rangle = X^T_i X^\prime = \sum_j^m X_{i,j} x^\prime_j\).
duaalimuoto osoittaa, että lineaarinen/ridge-regressio voidaan ymmärtää myös siten, että se antaa estimaatin painotetusta summasta uuden tapauksen sisätulosta jokaisen harjoitustapauksen kohdalla.
se tarkoittaa, että voimme tehdä lineaarisen regression silloinkin, kun sarakkeita on enemmän kuin rivejä, vaikka tämän merkitystä voidaan liioitella, koska (i) voimme tehdä tämän joka tapauksessa käyttämällä L2-regularisointia, koska tämä tekee \(X^TX\) – matriisista aina käännettävän; ja (ii) \(XX^t\) – matriisi voi usein vaatia L2-regularisointia joka tapauksessa inversion numeerisen vakauden varmistamiseksi. Sen avulla voimme myös nähdä lineaarisen regression paljon enemmän peräkkäisenä oppimisprosessina, jossa jokainen ylimääräinen datum harjoitusdatassa tuo jotain uutta.
meille tärkeintä on kuitenkin, että duaalimuodolla on mielenkiintoinen ominaisuus: ominaisvektorit esiintyvät yhtälöissä vain sisätuotteiden sisällä. Tämä pätee myös \(\alpha\) – sanan määritelmässä, sillä \(XX^t\) tuottaa harjoitustietojen jokaisen ominaisuusvektoriparin sisätuotteita vastaavan matriisin. Näemme asian tärkeyden edetessämme.
syrjään: kiinnostuneet opiskelijat voivat nähdä, miten duaalimuoto johdettiin Kaksimuotoisen asiakirjan Derivoinnissa, joka löytyy tämän artikkelin lopussa olevasta Lataukset-osiosta.
epälineaarinen Dual Ridge-regressio
duaalimuoto ridge-regressio voidaan muuttaa epälineaariseksi malliksi standardimenetelmällä, jossa käytetään epälineaarista ominaisuusmuunnosta \(\phi\):
\ \
ytimen funktiot
ytimen funktio \(K: \mathcal X \times \mathcal X \to \mathbb{R}\) on funktio, joka on symmetrinen – \(k(x_1, x_2)=K(x_2,x_1)\) – ja positiivinen definiitti (katso sivusta formaali määritelmä). Positiivis-definitenessiä käytetään matematiikassa, joka oikeuttaa ytimien käytön. Mutta ilman merkittävää matemaattista tietämystä määritelmä ei ole intuitiivisesti valaiseva. Sen sijaan, että yrittäisimme ymmärtää ytimiä myönteisen määritelmän perusteella, esittelemme ne useilla esimerkeillä.
ennen tätä toteamme, että vaikka ytimet ovat kahden argumentin funktioita,on tavallista ajatella niiden sijaitsevan ensimmäisessä argumentissaan ja olevan toisen funktionsa. Tämän tulkinnan mukaan näet merkintää \(K_x(y)\), joka vastaa \(K(x,y)\) . Erityisesti ajattelemme usein, että ytimet ovat yhden argumentin funktioita, jotka ”sijaitsevat” datapisteissä (ominaisuusvektorit) koulutustietoissamme. Joskus voitte lukea meistä’ pudottamassa ’ ytimiä datapisteisiin. Joten jos meillä on ominaisuusvektori \(x_i\), pudotamme ytimen sille,mikä johtaa funktioon \(K_{x_i}(x)\), joka sijaitsee \(x_i\) ja vastaa \(K(x_i, x)\).
huomaamme myös, että ytimet on usein määritelty parametristen perheiden jäseniksi. Esimerkkejä tällaisista kernel-perheistä ovat:
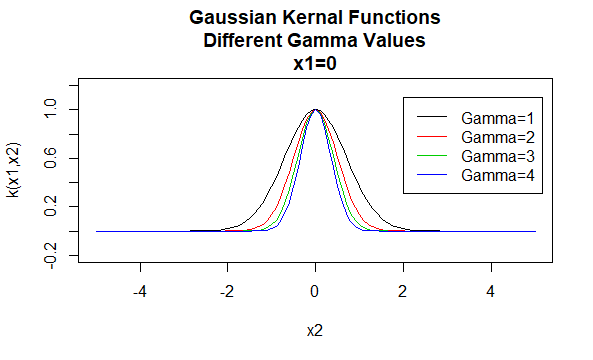
Gaussin ytimet
Gaussin ytimet ovat esimerkki säteittäisestä perusfunktiosta, ja niitä kutsutaan joskus säteittäiseksi perusytimeksi. Säteittäisen perusfunktion ytimen arvo riippuu vain argumenttivektorien välisestä etäisyydestä, ei niinkään niiden sijainnista. Tällaisia ytimiä sanotaan myös paikallaan pysyviksi.
parametrit: \(\gamma\)
yhtälön muoto: \(K (X_1, X_2)=e^{- \gamma \ / X_1-X_2 \|^2}\)
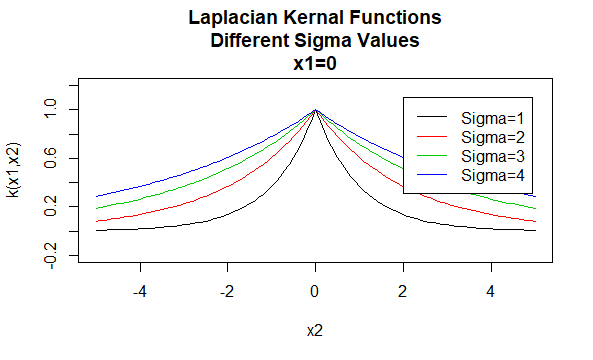
Laplacian ytimet
Laplacian ytimet ovat myös säteittäisiä perusfunktioita.
parametrit: \(\sigma\)
Yhtälömuoto: \(K (X_1, X_2)=e^{-\frac{\| X_1 – X_2 \|}{\sigma}}\)
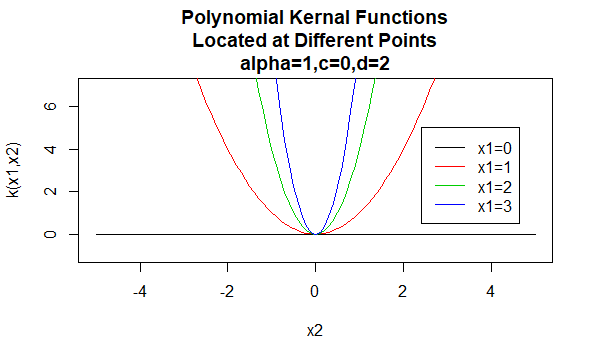
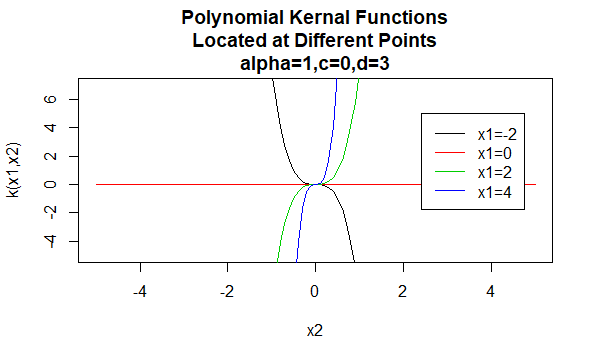
Polynomiydimet
Polynomiydimet ovat esimerkki ei-paikallaan pysyvistä ytimistä. Joten nämä ytimet antavat eri arvoja pareille pisteitä, jotka jakavat saman etäisyyden, niiden arvojen perusteella. Parametrien arvojen on oltava ei-negatiivisia, jotta nämä ytimet ovat positiivisia.
parametrit: \(\alpha , c,d\)
yhtälön muoto: \(K(X_1, X_2)=(\alpha X_1^tx_2 +c)^d\)
tiettyjen arvojen määrittäminen ytimen perheen parametreille johtaa ytimen funktioon. Alla on esimerkkejä edellä mainittujen perheiden ytimien funktioista, joiden tietyt parametriarvot sijaitsevat eri pisteissä (eli piirretty graafi on toisen argumentin funktio, jonka ensimmäinen argumentti on asetettu tietylle arvolle).
Sivuun: Kiinnostuneet opiskelijat voivat nähdä määritelmän positiivinen definiteness ytimet ytimet ja positiivinen Definiteness asiakirja saatavilla lataukset osassa lopussa tämän artikkelin.
ytimen temppu
ytimen funktioiden merkitys tulee hyvin erikoisesta ominaisuudesta: Jokainen positiivinen-definiittinen ydin \(k\) liittyy matemaattiseen avaruuteen \(\mathcal{H}_K\) (tunnetaan ytimen toistettavana Hilbert-avaruutena (RKHS)) siten, että \(K\): n soveltaminen kahteen ominaisuusvektoriin \(X_1, X_2\) vastaa näiden ominaisuusvektorien projisoimista \(\mathcal{H}_K\) jollakin projektiofunktiolla \(\phi\) ja niiden sisäisen tulon ottaminen sinne:
\
ytimiin liittyvät RKHSs: t ovat tyypillisesti suuriulotteisia. Joillekin ytimille, kuten Gaussin suvun ytimille, ne ovat äärettömyysulotteisia.
edellä oleva on perusta kuuluisalle ”ytimen tempulle”: jos syötteen ominaisuudet ovat mukana tilastollisen mallin yhtälössä vain sisätuotteiden muodossa, voimme korvata yhtälön sisätuotteet kutsuilla ytimen funktiolle ja tuloksena on ikään kuin olisimme projisoineet syötteen ominaisuudet korkeampaan ulottuvuuteen (eli suorittaneet ominaisuuden muunnoksen, joka johtaa suureen määrään piileviä muuttuvia ominaisuuksia) ja vieneet sisätuotteen sinne. Mutta meidän ei koskaan tarvitse suorittaa varsinaista projektiota.
koneoppimisen terminologiassa ytimeen liittyvät RKHS: t tunnetaan ominaisuusavaruutena erotuksena tuloavaruudesta. Via kernel temppu me implisiittisesti project input ominaisuudet tähän ominaisuus tilaa ja ottaa niiden sisäinen tuote siellä.
ytimen regressio
tämä johtaa menetelmään, joka tunnetaan nimellä ytimen regressio. Se on yksinkertaisesti kernel-tempun soveltaminen Ridge-regression kaksoismuotoon. Helppouden vuoksi esittelemme ytimen eli Gram-matriisin idean \(k\) siten,että \(K_{i,j}=k(X_i, X_j)\). Sitten voimme kirjoittaa yhtälöt ytimen regressio kuin:
\ \
missä \(k\) on jokin positiivis-definiittinen ytimen funktio.
Repressorin lause
harkitse optimointiongelmaa, jonka pyrimme ratkaisemaan suorittaessamme L2-regularisointia jonkinlaiselle mallille \(f\):
\
suoritettaessa ytimen regressiota ytimen \(k\) avulla on tärkeä regularisaatioteorian tulos, että yllä olevan yhtälön minimoija on muotoa:
\
jossa \(\alpha\) lasketaan edellä kuvatulla tavalla.
tämä on oikeudenmukaisesti lionisoitu Repressorin lause. Sanoin se sanoo, että lineaarisen regression optimointiongelman minimoija tietyn ytimen saavuttamassa implisiittisessä ominaisuusavaruudessa (ja siten epälineaarisen ytimen regressio-ongelman minimoija) annetaan painotetulla summalla ytimiä, jotka ”sijaitsevat” kussakin ominaisuusvektorissa.
aiheesta on paljon muutakin sanottavaa. Voimme jopa selvittää, mitä vihreä toiminto (joista ytimet ovat osajoukko) minimoi erityisesti Regularisointi TEKNISET, kuten L2 Regularisointi mutta myös kaikki rangaistus perustuu lineaarinen differentiaali operaattori. Tämä suhde ytimien ja optimaalisten ratkaisujen Tihonov regularisointiongelmiin on pääsyy ytimen menetelmien tärkeyteen koneoppimisessa. Mutta matematiikka tässä on tämän kurssin ulkopuolella, ja kiinnostuneita edistyneitä opiskelijoita viitataan haykinin neuroverkkojen ja Oppimiskoneiden seitsemänteen lukuun.
tämä antaa matemaattisen perustelun ytimen regression käytölle tapauksissa, joissa se on mahdollista. Itse treenata optimaalinen ydin käyttää ei yleensä ole mahdollista-se vaatii tietää optimaalinen lineaarinen differentiaalioperaattori käyttää regularisation rangaistus. Toiminnot meidän pitäisi projisoida optimoida erityisesti Regularisointi seuraamuksia on laskettu, ja tiedämme, esimerkiksi, että ohut spline kernel on optimaalinen L2 Regularisointi. Toisaalta, koska meidän on laskettava Gram-matriisi, ytimen regressio ei skaalaudu hyvin – suurten datajoukkojen kääntyminen neuroverkkoihin on parempi idea.