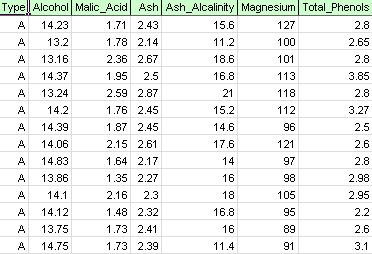
On the Xlminer ribbon, from the Applying your Model tab, valitse Help – Examples, then Forecasting / Data Mining Examples, and open the example file Wine.xlsx. Kuten jäljempänä olevasta kuvasta ilmenee, tämän esimerkkitietoaineiston jokainen rivi edustaa näytettä viinistä, joka on otettu jostakin kolmesta viinitilasta (A, B tai C). Tässä esimerkissä viinitilaa edustava Tyyppimuuttuja jätetään huomiotta, ja ryhmittely suoritetaan yksinkertaisesti viininäytteiden ominaisuuksien perusteella (muut muuttujat).
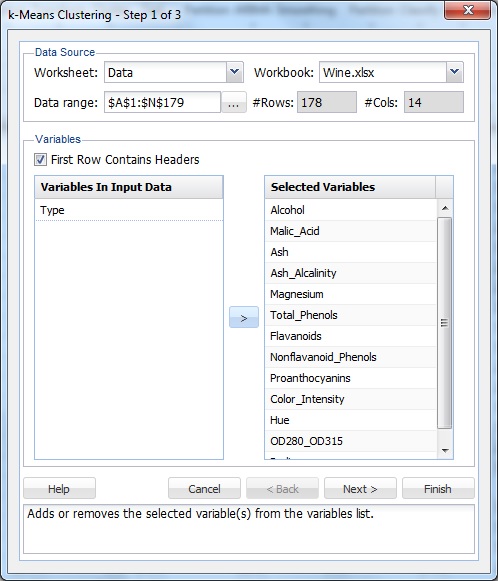
valitse solu tietojoukossa ja valitse sitten Xlminer-nauhassa Data-analyysi-välilehdestä XLMiner – Cluster-k-Means Clustering avataksesi k-Means Clustering-vaiheen 1 3 dialogista.
valitse muuttujien luettelosta kaikki muuttujat tyyppiä lukuun ottamatta ja napsauta sitten > – painiketta siirtääksesi valitut muuttujat valittujen muuttujien luetteloon.
klikkaa Seuraava edetäksesi 3 dialogin vaiheeseen 2.
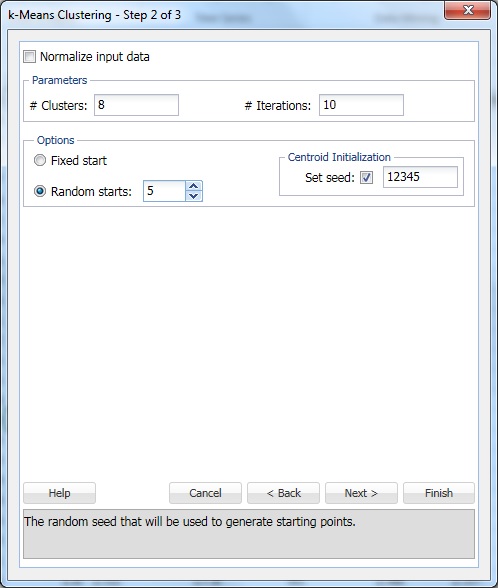
# klustereissa, syötä 8. Tämä on parametri k K-means-ryhmittelyalgoritmissa. Klusterien lukumäärän tulee olla vähintään 1 ja enintään havaintojen määrän -1 aineistoalueella. Aseta k useisiin eri arvoihin ja arvioi kunkin tuotos.
jätä # – iteraatiot oletusasetukseen 10. Tämän vaihtoehdon arvo määrittää, kuinka monta kertaa ohjelma alkaa alkuosiolla ja täydentää ryhmittelyalgoritmia. Klusterien kokoonpano (ja tietojen erottaminen) voi vaihdella aloitusosiosta toiseen. Ohjelma käy läpi määrätyn määrän iteraatioita ja valitsee klusterin kokoonpanon, joka minimoi etäisyysmittarin.
Aseta Satunnainen alku arvoon 5. Kun tämä vaihtoehto on valittu, algoritmi alkaa rakentaa mallia mistä tahansa satunnaisesta pisteestä. XLMiner tuottaa viisi klusterisarjaa ja tuottaa tuotoksen parhaan klusterin perusteella.
Set seed valitaan oletusarvoisesti. Tämä asetus alustaa satunnaislukugeneraattorin, jota käytetään alkurykelmän centroidien laskemiseen. Asettamalla satunnaislukusiemen arvoon, joka ei ole nolla (oletusarvo 12345), varmistetaan, että sama satunnaislukusarja käytetään aina, kun alkuperäinen klusterin centroids lasketaan. Kun siemen on nolla, satunnaislukugeneraattori alustetaan järjestelmän kellosta, joten satunnaislukujen järjestys on erilainen joka kerta, kun centroidit alustetaan. Aseta siemen pitämään ryhmittelymenetelmän peräkkäisiä suorituksia vertailukelpoisina.
valitse normalisoi syöttötiedot-asetus normalisoidaksesi tiedot. Tässä esimerkissä tietoja ei normalisoida. Valitse Seuraava avataksesi vaiheen 3 3 dialogista.
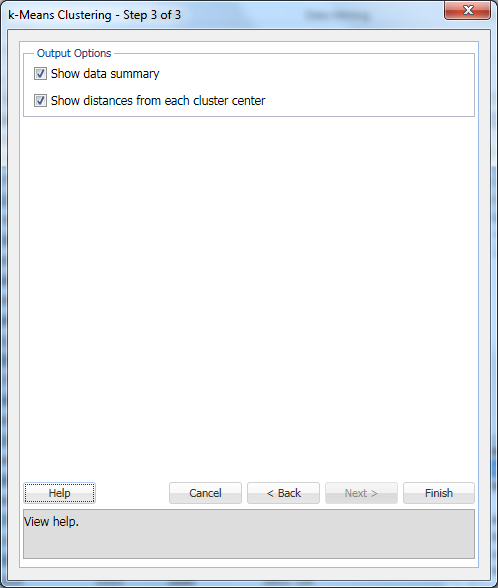
valitse Näytä tietojen yhteenveto (oletus) ja näytä etäisyydet kustakin klusterin keskuksesta (oletus) ja valitse sitten Valmis.
K-tarkoittaa ryhmittelyä menetelmä alkaa K: n alkuklustereilla määritellyllä tavalla. Jokaisessa iteraatiossa tietueet osoitetaan klusterille, jolla on lähin centroid eli keskus. Jokaisen iteraation jälkeen lasketaan kunkin tietueen etäisyys klusterin keskipisteeseen. Nämä kaksi vaihetta toistetaan (tietueen jakaminen ja etäisyyslaskenta), kunnes tietueen uudelleenjako lisää etäisyyden arvoa.
kun satunnainen alku on määritelty, algoritmi luo k-klusterin keskukset satunnaisesti ja sopii näiden klustereiden datapisteisiin. Tämä prosessi toistetaan kaikille määritellyille satunnaisille aloituksille. Tuotos perustuu klustereita, jotka osoittavat parhaiten sopivat.
laskentataulukko KM_Output1 lisätään välittömästi laskentataulukon oikealle puolelle. Tuotoksen laskentataulukon ylimmässä osassa on lueteltu valitut vaihtoehdot.
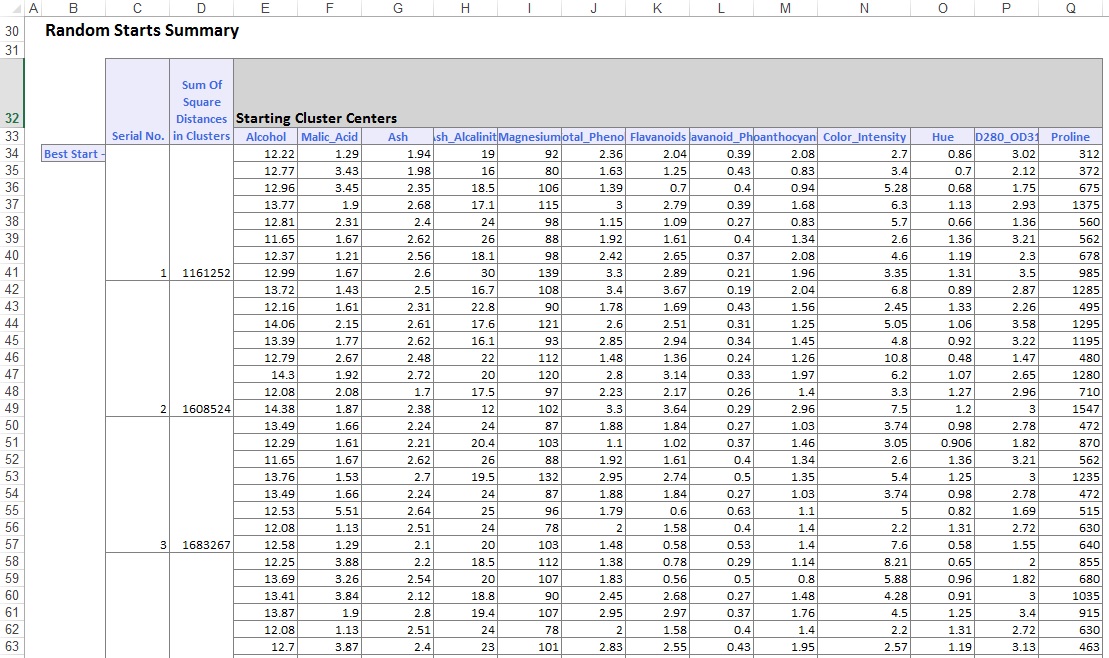
in the middle section of the output worksheet, XLMiner on laskenut potenssietäisyyksien summan ja määrittänyt alun PIENIMMÄLLÄ Neliöetäisyyden summalla parhaaksi aloitukseksi (#5). Kun paras startti on määritetty, XLMiner tuottaa jäljellä olevan lähdön käyttäen parasta starttia lähtöpisteenä.
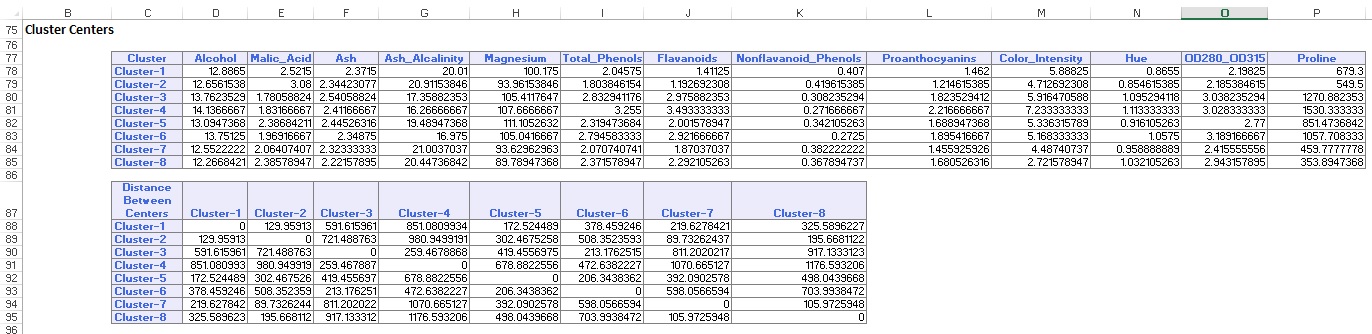
lähtötaulukon alaosassa XLMiner on listannut Klusterikeskukset (alla). Ylempi laatikko näyttää muuttujan arvot klusterin keskuksissa. Cluster 8 on korkein keskimääräinen alkoholi, Total_Phenols, flavanoidit, Proantosyaniinit, Color_Intensity, Hue, ja Proline pitoisuus. Vertaa tätä klusteria klusteriin 2, jolla on korkein keskimääräinen Ash_Alcalinity ja Nonflavanoid_Phenols.
alempi laatikko näyttää klusterin keskusten välisen etäisyyden. Tämän taulukon arvoista on päätelty, että klusteri 3 on hyvin erilainen kuin klusteri 8 johtuen suuresta etäisyysarvosta 1,176.59, ja klusteri 7 on lähellä klusteria 3 pienellä etäisyysarvolla 89,73.
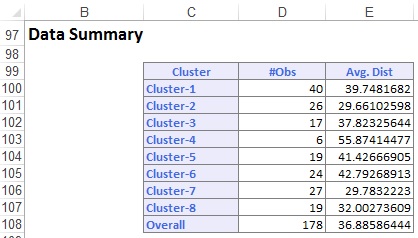
alla oleva Tietoyhteenveto näyttää kuhunkin klusteriin sisältyvien tietueiden (havaintojen) määrän ja keskimääräisen etäisyyden klusterin jäsenistä kunkin klusterin keskipisteeseen. Rypäs 6: lla on korkein keskimatka 42,79, ja se sisältää 24 ennätystä. Vertaa tätä klusteria klusteriin 2, jonka pienin keskimatka on 29,66, ja johon kuuluu 26 jäsentä.
Click the KM_Clusters1 worksheet. Tämä laskentataulukko näyttää klusterin, johon kukin tietue on osoitettu, ja etäisyyden kuhunkin klusteriin. Ensimmäisen ennätyksen etäisyys klusteriin 6 on vähimmäisetäisyys 23,205, joten tämä ensimmäinen ennätys on osoitettu klusteriin 6.