Kuvittele, että sinulla on työkalu, joka voi automaattisesti havaita parlamentaarisen edustajakokouksen ja Hibernate suorituskykyongelmat. Hypersistence Optimizer on se työkalu!
Johdanto
jos mietit, miksi ja milloin sinun pitäisi käyttää yhteistä parlamentaarista edustajakokousta tai Hibernatea, niin tämä artikkeli antaa sinulle vastauksen tähän hyvin yleiseen kysymykseen. Koska olen nähnyt tämän kysymyksen kysyttävän hyvin usein /R / java Reddit-kanavalla, päätin, että kannattaa kirjoittaa perusteellinen vastaus JPA: n ja Hibernaten vahvuuksista ja heikkouksista.
vaikka JPA on ollut standardi siitä lähtien, kun se julkaistiin ensimmäisen kerran vuonna 2006, se ei ole ainoa tapa toteuttaa tietojen käyttöoikeuskerros Javalla. Aiomme keskustella yhteisen parlamentaarisen edustajakokouksen tai muiden suosittujen vaihtoehtojen käytön eduista ja haitoista.
miksi ja milloin JDBC luotiin
vuonna 1997, Java 1.1 esitteli JDBC (Java Database Connectivity) API, joka oli hyvin vallankumouksellinen sen aikaa, koska se tarjosi mahdollisuuden kirjoittaa tietojen access layer kerran käyttäen joukko rajapintoja ja ajaa sitä tahansa relaatiotietokanta, joka toteuttaa JDBC API tarvitsematta muuttaa sovelluksen koodi.
JDBC API tarjosi Connection – rajapinnan, jolla voidaan hallita tapahtuman rajoja ja luoda yksinkertaisia SQL-lausekkeita Statement API: n kautta tai valmiita lausekkeita, joiden avulla voidaan sitoa parametriarvoja PreparedStatement API: n kautta.
joten, olettaen, että meillä on post tietokantataulukko ja haluamme lisätä 100 riviä, näin voisimme saavuttaa tämän tavoitteen JDBC: llä:
int postCount = 100;int batchSize = 50;try (PreparedStatement postStatement = connection.prepareStatement(""" INSERT INTO post ( id, title ) VALUES ( ?, ? ) """)) { for (int i = 1; i <= postCount; i++) { if (i % batchSize == 0) { postStatement.executeBatch(); } int index = 0; postStatement.setLong( ++index, i ); postStatement.setString( ++index, String.format( "High-Performance Java Persistence, review no. %1$d", i ) ); postStatement.addBatch(); } postStatement.executeBatch();} catch (SQLException e) { fail(e.getMessage());}
vaikka käytimme hyväksi monirivisiä tekstilohkoja ja try-with-resources-lohkoja poistaaksemme PreparedStatement close – puhelun, toteutus on edelleen hyvin monisanainen. Huomaa, että bind-parametrit alkavat 1: stä, eivät 0: stä, kuten muut tunnetut sovellusliittymät saattavat tehdä.
hakeaksemme ensimmäiset 10 riviä, saatamme joutua suorittamaan SQL-kyselyn PreparedStatement: n kautta, joka palauttaa ResultSet, joka edustaa taulukkopohjaista kyselyn tulosta. Koska sovellukset kuitenkin käyttävät hierarkkisia rakenteita, kuten JSON tai DTOs, edustamaan vanhempien ja lasten yhteenliittymiä, useimmat sovellukset tarvitsivat JDBC ResultSet: n muuntamiseen eri muotoon tiedonsaantikerroksessa, kuten seuraava esimerkki osoittaa:
int maxResults = 10;List<Post> posts = new ArrayList<>();try (PreparedStatement preparedStatement = connection.prepareStatement(""" SELECT p.id AS id, p.title AS title FROM post p ORDER BY p.id LIMIT ? """)) { preparedStatement.setInt(1, maxResults); try (ResultSet resultSet = preparedStatement.executeQuery()) { while (resultSet.next()) { int index = 0; posts.add( new Post() .setId(resultSet.getLong(++index)) .setTitle(resultSet.getString(++index)) ); } }} catch (SQLException e) { fail(e.getMessage());}
jälleen, tämä on mukavin tapa kirjoittaa tämä JDBC: n kanssa, koska käytämme tekstilohkoja, try-with-resources, ja sujuvaa tyylistä API: ta rakentamaan Post – objekteja.
JDBC API on kuitenkin edelleen hyvin monisanainen ja, mikä vielä tärkeämpää, siitä puuttuu monia ominaisuuksia, joita tarvitaan nykyaikaista tiedonsiirtokerrosta toteutettaessa, kuten:
- tapa hakea objekteja suoraan kyselyn tulosjoukosta. Kuten olemme nähneet yllä olevassa esimerkissä, meidän täytyy iteroida
ReusltSetja poimia sarakearvot asettaaksemmePostobjektin ominaisuudet. - avoin tapa eräkohtaisten lausekkeiden laatimiseen ilman, että tietojen käyttöoikeuskoodia tarvitsee kirjoittaa uudelleen siirryttäessä oletuserittelemättömästä tilasta eräerittelyn käyttöön.
- tuki optimistiselle lukitukselle
- paginaatiorajapinta, joka kätkee taustalla olevan tietokantakohtaisen Top-n-ja Next-n-kyselyn syntaksin
miksi ja milloin Hibernate luotiin
vuonna 1999 Sun julkaisi J2EE: n (Java Enterprise Edition), joka tarjosi vaihtoehdon JDBC: lle nimeltä Entity Beans.
koska Entiteettipavut olivat tunnetusti hitaita, liian monimutkaisia ja hankalia käyttää, Gavin King päätti vuonna 2001 luoda ORM-kehyksen, joka voisi kartoittaa tietokantataulukoita Pojosiin (Plain Old Java Objects), ja näin syntyi Hibernate.
koska Hibernate oli kevytrakenteisempi kuin Entity Beans ja vähemmän verbaalinen kuin JDBC, se kasvoi yhä suositummaksi, ja siitä tuli pian suosituin Java persistence framework, voittaen JDO: n, ibatisin, Oracle Toplinkin ja Apache cayennen.
miksi ja milloin yhteinen edustajakokous perustettiin?
Hibernate-projektin menestyksen jälkeen Java EE-alusta päätti standardoida Hibernaten ja Oracle Toplinkin tavan, ja näin syntyi JPA (Java Persistence API).
yhteinen parlamentaarinen edustajakokous on vain spesifikaatio, eikä sitä voida käyttää yksinään, vaan se tarjoaa vain joukon rajapintoja, jotka määrittelevät yhteisen edustajakokouksen tarjoajan toteuttaman standardin pysyvyysrajapinnan, kuten Hibernate, EclipseLink tai OpenJPA.
kun käytät JPA: ta, sinun on määriteltävä tietokantataulukon ja siihen liittyvän Java entity-olion välinen kartoitus:
@Entity@Table(name = "post")public class Post { @Id private Long id; private String title; public Long getId() { return id; } public Post setId(Long id) { this.id = id; return this; } public String getTitle() { return title; } public Post setTitle(String title) { this.title = title; return this; }}
jälkeenpäin voidaan kirjoittaa uudelleen edellinen esimerkki, joka pelasti 100 post tietueet näyttää tältä:
for (long i = 1; i <= postCount; i++) { entityManager.persist( new Post() .setId(i) .setTitle( String.format( "High-Performance Java Persistence, review no. %1$d", i ) ) );}
jotta JDBC erä insertit, meidän täytyy vain tarjota yksi kokoonpano ominaisuus:
<property name="hibernate.jdbc.batch_size" value="50"/>
kun tämä ominaisuus on annettu, Hibernate voi siirtyä automaattisesti eräajosta eräajoon tarvitsematta muuttaa mitään tietojen käyttöoikeuskoodia.
ja hakeaksemme ensimmäiset 10 post riviä voimme suorittaa seuraavan JPQL-kyselyn:
int maxResults = 10;List<Post> posts = entityManager.createQuery(""" select p from post p order by p.id """, Post.class).setMaxResults(maxResults).getResultList();
jos vertaat tätä JDBC versio, näet, että JPA on paljon helpompi käyttää.
yhteisen parlamentaarisen edustajakokouksen ja yleisesti yhteisen edustajakokouksen
yhteisen edustajakokouksen ja erityisesti Hibernaten käytön edut ja haitat tarjoavat monia etuja.
- voi hakea entiteettejä tai Dtoja. Voit jopa hakea hierarkkista vanhemman ja lapsen Dto-projektiota.
- voit ottaa käyttöön JDBC-erittelyn muuttamatta tietojen käyttöoikeuskoodia.
- sinulla on tuki optimistiselle lukitukselle.
- sinulla on pessimistinen lukitusabstraktio, joka on riippumaton taustalla olevasta tietokantakohtaisesta syntaksista, jotta voit hankkia luku-ja KIRJOITUSLUKON tai jopa HYPPYLUKON.
- käytössä on tietokannasta riippumaton sivurajapinta.
- voit antaa
Listarvoja kyselylausekkeelle, kuten tässä artikkelissa selitetään. - voit käyttää vahvasti johdonmukaista välimuistiratkaisua, jonka avulla voit purkaa ensisijaisen solmun, jota voidaan rea-write-tapahtumissa kutsua vain pystysuunnassa.
- sinulla on sisäänrakennettu tuki tilintarkastuskirjautumiselle Hibernate Enversin kautta.
- sinulla on sisäänrakennettu tuki moniajoon.
- voit luoda alkuperäisen skeema-skriptin entiteettien kartoituksista käyttämällä Hibernate hbm2ddl-työkalua, jonka voit toimittaa flywayn kaltaiselle automaattiselle skeemasiirtotyökalulle.
- sen lisäksi, että sinulla on vapaus suorittaa mikä tahansa natiivi SQL-kysely, voit myös käyttää Sqlresultsetmappingia muuttaaksesi JDBC
ResultSetJPA-yksiköiksi tai DTOs-yksiköiksi.
JPA: n ja Hibernaten käytön haitat ovat seuraavat:
- vaikka pääseminen alkuun JPA on erittäin helppoa, tulla asiantuntija vaatii merkittävää aikaa investointeja, koska, lukemisen lisäksi sen käsikirja, sinun täytyy vielä oppia, miten tietokantajärjestelmät toimivat, SQL-standardi sekä erityisiä SQL maku käyttää projektin relation database.
- on joitain vähemmän intuitiivisia käyttäytymismalleja, jotka saattavat yllättää aloittelijat, kuten huuhteluoperaatiojärjestys.
- kriteerien API on melko monisanainen, joten dynaamisten kyselyiden kirjoittamiseen on käytettävä Codotan kaltaista työkalua helpommin.
yleinen yhteisö-ja kansanintegraatiot
JPA ja Hibernate ovat erittäin suosittuja. Snykin vuoden 2018 Java ecosystem-raportin mukaan Hibernatea käyttää 54% jokaisesta Java-kehittäjästä, joka on vuorovaikutuksessa relaatiotietokannan kanssa.
tätä tulosta voi tukea Google Trends. Jos vertaamme esimerkiksi yhteisen parlamentaarisen edustajakokouksen Google trendejä sen pääkilpailijoihin (esim.MyBatis, QueryDSL ja jOOQ), voimme nähdä, että yhteinen edustajakokous on monta kertaa suositumpi eikä osoita merkkejä hallitsevan markkinaosuutensa menettämisestä.

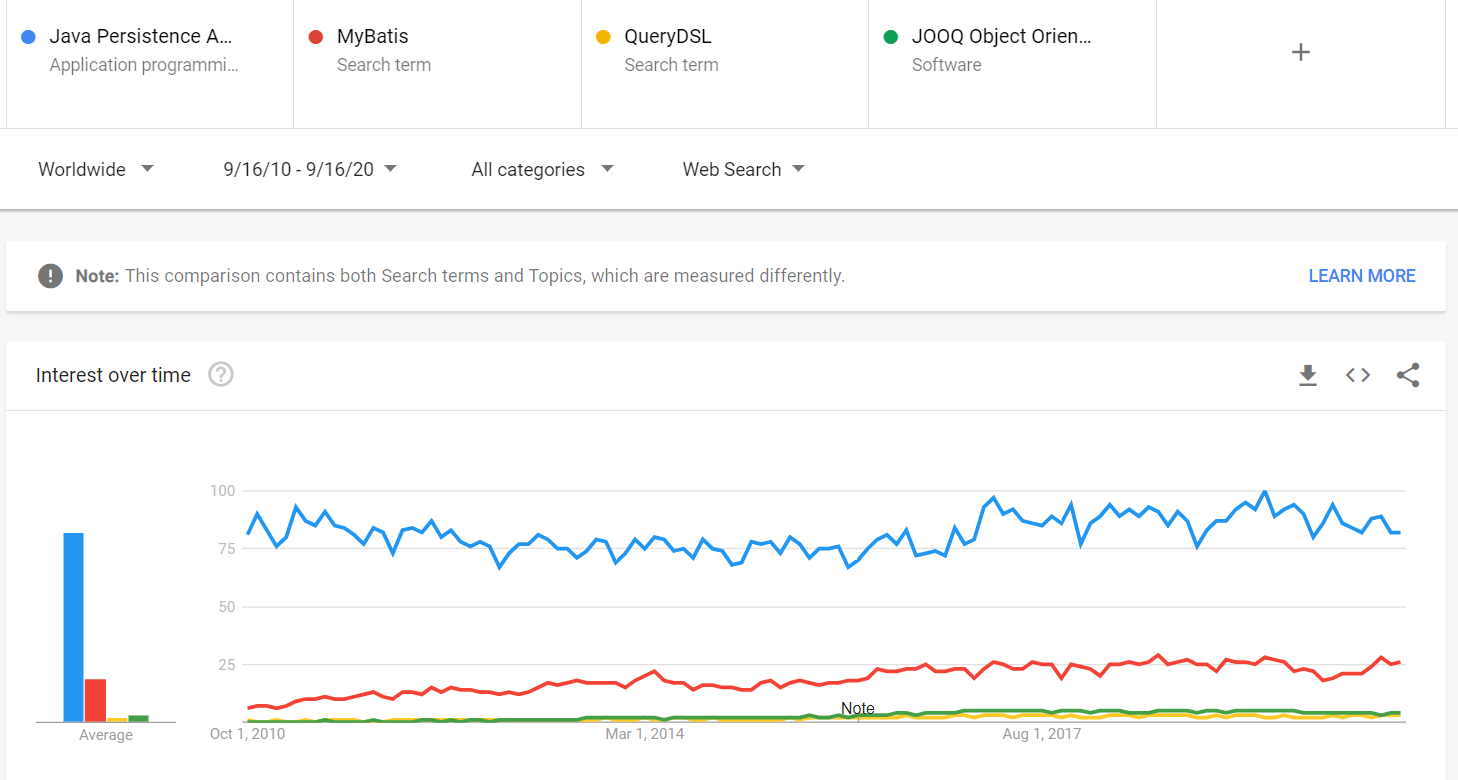
on niin suosittu tuo monia etuja, kuten:
- Spring Data JPA-integraatio toimii kuin unelma. Itse asiassa yksi suurimmista syistä, miksi JPA ja Hibernate ovat niin suosittuja, koska Spring Boot käyttää Spring Data JPA, joka puolestaan käyttää Hibernate kulissien takana.
- jos sinulla on jokin ongelma, on hyvin mahdollista, että nämä 30k Hibernateen liittyvät StackOverflow-vastaukset ja 16K JPA: han liittyvät StackOverflow-vastaukset tarjoavat sinulle ratkaisun.
- tarjolla on 73k Hibernate tutorials. Vain oma sivusto yksin tarjoaa yli 250 JPA ja Hibernate tutorials, jotka opettavat sinulle, miten saat kaiken irti JPA ja Hibernate.
- voit käyttää myös monia videokursseja, kuten korkean suorituskyvyn Java Persistence-videokurssini.
- Amazonin Hibernatesta on yli 300 kirjaa, joista yksi on myös minun korkean suorituskyvyn Java Persistence-kirjani.
YPA-vaihtoehdot
Jaavan ekosysteemin suurimpia asioita on laadukkaiden puitteiden runsaus. Jos JPA ja Hibernate eivät sovi käyttötapaukseesi, voit käyttää mitä tahansa seuraavista kehyksistä:
- MyBatis, joka on erittäin kevyt SQL query mapper framework.
- QueryDSL, jonka avulla voit rakentaa SQL -, JPA -, Lucene-ja MongoDB-kyselyjä dynaamisesti.
- jOOQ, joka tarjoaa Java-metamodelin taustalla oleville taulukoille, tallennetuille prosesseille ja toiminnoille ja mahdollistaa SQL-kyselyn rakentamisen dynaamisesti erittäin intuitiivisella DSL: llä ja tyyppiturvallisella tavalla.
käytä siis sitä, mikä sopii sinulle parhaiten.
Online Workshops
If you enjoyed this article, I bet you are going to love my coming 4-day x 4 hours High-Performance Java Persistence Online Workshop

johtopäätös
tässä artikkelissa näimme, miksi JPA luotiin ja milloin sitä kannattaa käyttää. Vaikka JPA tuo monia etuja, sinulla on monia muita laadukkaita vaihtoehtoja käyttää, jos JPA ja Hibernate eivät toimi parhaiten nykyisen sovelluksen vaatimukset.
ja joskus, kuten selitin tässä ilmaisessa otoksessa korkean suorituskyvyn Java Persistence-kirjassani, sinun ei tarvitse edes valita JPA: n tai muiden puitteiden välillä. Voit helposti yhdistää JPA kanssa puitteet kuten jOOQ saada parhaat puolet molemmista maailmoista.



