Nous commençons par examiner la régression linéaire / crête à double forme, avant de montrer comment la « kerneliser ». En expliquant ce dernier, nous verrons ce que sont les noyaux et quelle est la « astuce du noyau ».
Régression de crête à double forme
La régression linéaire est généralement donnée sous sa forme primaire sous la forme d’une combinaison linéaire de colonnes (caractéristiques). Cependant, il existe une deuxième forme duale où il s’agit d’une combinaison linéaire du produit interne d’une nouvelle donnée (sur laquelle nous effectuons des inférences) avec chacune des données d’apprentissage.
On considère le cas de régression de crête (régression linéaire régularisée L2), en se souvenant que la régression linéaire de base correspond au cas où \(\lambda= 0\). Ensuite, les formules de régression de crête, où \(X\) et \(Y\) se réfèrent aux données d’entraînement \(n\ fois m \) et \(x^\ prime, y^\ prime\) un nouveau cas à estimer, sont:
\ \ \ \
Où \(\langle X_i, x^\prime\rangle\) est le produit intérieur / scalaire, donc \(\langle X_i, x^\prime\rangle = X^T_i x^\prime = \sum_j^m X_{i, j} x^\prime_j\).
La forme duale montre que la régression linéaire /crête peut également être comprise comme fournissant une estimation d’une somme pondérée du produit interne d’un nouveau cas avec chacun des cas d’apprentissage.
Cela signifie que nous pouvons faire une régression linéaire même lorsqu’il y a plus de colonnes que de lignes, bien que l’importance de cela puisse être surestimée puisque (i) nous pouvons le faire de toute façon via l’utilisation de la régularisation L2 car cela rend toujours la matrice \(X ^ TX\) inversible; et (ii) la matrice \(XX^T\) peut souvent nécessiter de toute façon une régularisation L2 pour assurer la stabilité numérique de l’inversion. Cela nous permet également de considérer la régression linéaire comme un processus d’apprentissage séquentiel, où chaque donnée supplémentaire dans les données d’entraînement apporte quelque chose de nouveau.
Le plus important pour nos besoins, cependant, la forme duale a la caractéristique intéressante: les vecteurs caractéristiques ne se produisent dans les équations qu’à l’intérieur des produits internes. Cela est vrai même dans la définition de \(\alpha\), car \(XX^T\) produit la matrice correspondant aux produits internes de chaque paire de vecteurs d’entités dans les données d’apprentissage. Nous verrons l’importance de cela au fur et à mesure.
À part: Les étudiants intéressés peuvent voir comment le formulaire double a été dérivé dans le document Dérivation of Dual Form disponible dans la section téléchargements à la fin de cet article.
Régression Dual Ridge non linéaire
Nous pouvons transformer notre régression dual form ridge en un modèle non linéaire par la méthode standard d’utilisation d’une caractéristique non linéaire transformations \(\phi\):
\ \
Fonctions du noyau
Une fonction du noyau, \(K: \mathcal X\times\mathcal X\ to\mathbb{R}\), est une fonction symétrique – \(K(x_1, x_2) = K(x_2, x_1)\) – et définie positive (voir le côté pour une définition formelle). La définition positive est utilisée en mathématiques qui justifie l’utilisation de noyaux. Mais sans connaissances mathématiques significatives, la définition n’est pas intuitivement éclairante. Donc, plutôt que d’essayer de comprendre les noyaux à partir de la définition de la définition positive, nous allons les présenter avec un certain nombre d’exemples.
Avant de faire cela, nous notons que bien que les noyaux soient des fonctions à deux arguments, il est courant de les considérer comme étant situés à leur premier argument et étant une fonction de leur second. Selon cette interprétation, vous verrez une notation telle que \(K_x(y)\), qui est équivalente à \(K(x, y)\). En particulier, nous penserons souvent que les noyaux sont des fonctions à argument unique « situées » à des points de données (vecteurs d’entités) dans nos données d’entraînement. Parfois, vous lirez que nous « déposons » des noyaux sur des points de données. Donc, si nous avons un vecteur d’entités \(x_i\), nous y déposerons un noyau, conduisant à la fonction \(K_{x_i}(x)\) située à \(x_i\) et équivalente à \(K(x_i, x)\).
Nous notons également que les noyaux sont souvent spécifiés comme membres de familles paramétriques. Des exemples de telles familles de noyaux incluent:
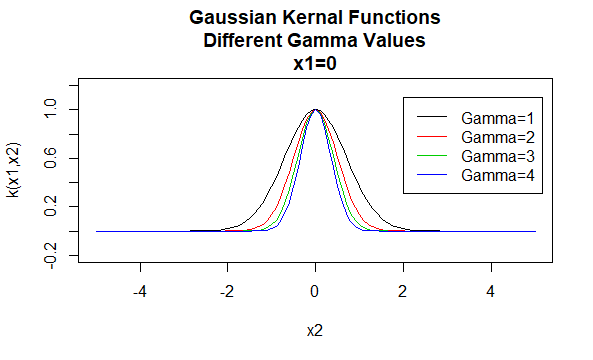
Noyaux gaussiens
Les noyaux gaussiens sont un exemple de noyaux de fonction de base radiale et sont parfois appelés noyaux de base radiale. La valeur d’un noyau de fonction de base radiale dépend uniquement de la distance entre les vecteurs d’argument, plutôt que de leur emplacement. De tels noyaux sont également appelés stationnaires.
Paramètres: \(\gamma\)
Forme d’équation: \(K(X_1, X_2) = e ^{-\gamma\/X_1-X_2 \|^2}\)
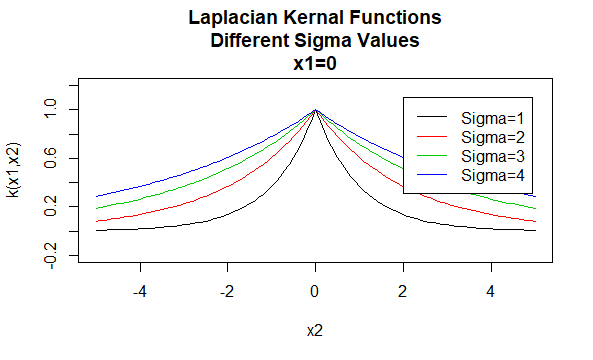
Noyaux laplaciens
Les noyaux laplaciens sont également des fonctions de base radiales.
Paramètres: \(\sigma\)
Forme d’équation: \(K(X_1, X_2) = e ^{-\frac{\|X_1–X_2\|}{\sigma}}\)
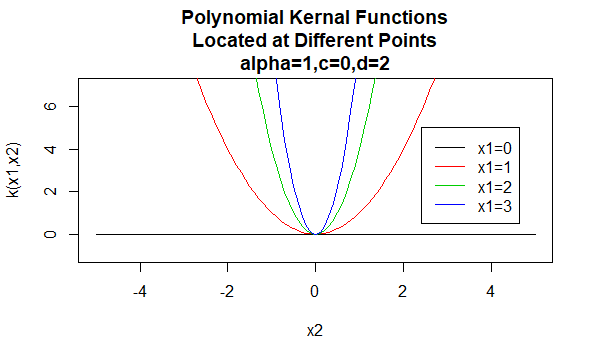
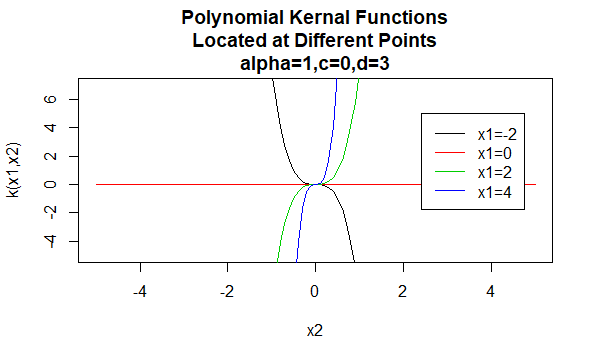
Noyaux polynomiaux
Les noyaux polynomiaux sont un exemple de noyaux non stationnaires. Ainsi, ces noyaux affecteront des valeurs différentes à des paires de points qui partagent la même distance, en fonction de leurs valeurs. Les valeurs des paramètres doivent être non négatives pour garantir que ces noyaux sont définis positivement.
Paramètres: \(\alpha, c, d\)
Forme d’équation: \(K(X_1,X_2) =(\alpha X_1 ^TX_2 +c)^d\)
La spécification de valeurs particulières pour les paramètres d’une famille de noyaux entraîne une fonction de noyau. Vous trouverez ci-dessous des exemples de fonctions de noyaux des familles ci-dessus avec des valeurs de paramètres particulières situées en différents points (c’est-à-dire que le graphique tracé est une fonction du deuxième argument, le premier argument étant défini sur une valeur spécifique).
De côté: Les étudiants intéressés peuvent voir la définition de la définition positive pour les noyaux dans le document Noyaux et Définition positive disponible dans la section téléchargements à la fin de cet article.
L’astuce du noyau
L’importance des fonctions du noyau vient d’une propriété très spéciale: Chaque noyau défini positif, \(K\) est lié à un espace mathématique, \(\mathcal{H}_K\), (connu sous le nom d’espace de Hilbert du noyau reproducteur (RKHS) du noyau) tel que l’application de \(K\) à deux vecteurs de caractéristiques, \(X_1, X_2\) équivaut à projeter ces vecteurs de caractéristiques dans \(\mathcal{H}_K\) par une fonction de projection, \(\phi\) et y prendre leur produit interne:
\
Les RKHSs associés aux noyaux sont généralement de grande dimension. Pour certains noyaux, comme les noyaux de la famille Gaussienne, ils sont de dimension infinie.
Ce qui précède est à la base de la fameuse « astuce du noyau »: Si les caractéristiques d’entrée ne sont impliquées dans l’équation d’un modèle statistique que sous la forme de produits internes, nous pouvons remplacer les produits internes de l’équation par des appels à la fonction du noyau et le résultat est comme si nous avions projeté les caractéristiques d’entrée dans un espace de dimension supérieure (c’est-à-dire effectué une transformation de caractéristiques conduisant à un grand nombre de caractéristiques variables latentes) et y avions pris leur produit interne. Mais nous n’avons jamais besoin d’effectuer la projection réelle.
Dans la terminologie de l’apprentissage automatique, le RKHS associé au noyau est connu sous le nom d’espace d’entités, par opposition à l’espace d’entrée. Via l’astuce du noyau, nous projetons implicitement les fonctionnalités d’entrée dans cet espace de fonctionnalités et y emmenons leur produit interne.
Régression du noyau
Cela conduit à la technique connue sous le nom de régression du noyau. C’est simplement une application de l’astuce du noyau à la double forme de régression de crête. Pour plus de facilité, nous introduisons l’idée du noyau, ou Gram, matrice, \(K\), telle que \(K_{i, j} = k(X_i, X_j)\). Ensuite, nous pouvons écrire les équations pour la régression du noyau comme suit:
\ \
Où \(k\) est une fonction de noyau définie positive.
Le théorème du représentant
Considérons le problème d’optimisation que nous cherchons à résoudre lors de la régularisation L2 pour un modèle d’une forme quelconque, \(f\):
\
Lors de la régression du noyau avec le noyau \(k\), c’est un résultat important de la théorie de la régularisation que le minimiseur de l’équation ci-dessus sera de la forme:
\
Avec \(\alpha\) calculé comme décrit ci-dessus.
C’est le théorème du Représentant justement lionné. En termes simples, il est dit que le minimiseur du problème d’optimisation pour la régression linéaire dans l’espace de caractéristiques implicite obtenu par un noyau particulier (et donc le minimiseur du problème de régression de noyau non linéaire) sera donné par une somme pondérée de noyaux « situés » à chaque vecteur de caractéristiques.
Il y a beaucoup plus à dire sur ce sujet. Nous pouvons même déterminer quelle fonction Verte (dont les noyaux sont un sous-ensemble) minimisera des spécifications de régularisation particulières, telles que la régularisation L2 mais aussi toute pénalité basée sur un opérateur différentiel linéaire. Cette relation entre les noyaux et les solutions optimales aux problèmes de régularisation de Tikhonov est une raison principale de l’importance des méthodes de noyau dans l’apprentissage automatique. Mais les mathématiques ici sont au-delà de ce cours, et les étudiants avancés intéressés sont renvoyés au chapitre sept des Réseaux de neurones et des machines d’apprentissage de Haykin.
Cela nous donne une justification mathématique pour utiliser la régression du noyau dans les cas où il est possible de le faire. Il n’est généralement pas possible de déterminer le noyau optimal à utiliser – cela nécessite de connaître l’opérateur différentiel linéaire optimal à utiliser pour la pénalité de régularisation. Les fonctions sur lesquelles nous devrions nous projeter pour optimiser les pénalités de régularisation particulières ont été calculées, et nous savons, par exemple, que le noyau spline à plaque mince est optimal pour la régularisation L2. D’un autre côté, puisque nous devons calculer la matrice de Gram, la régression du noyau ne s’adapte pas bien – pour les grands ensembles de données, se tourner vers les réseaux de neurones est une meilleure idée.