Par: Arshad Ali | Mise à jour: 2013-06-24 | Commentaires (9) | Liés: > Développement de services d’analyse
- Problème
- Solution
- Entrepôt de données d’entreprise (EDW ou DW) Vs. Magasin de données opérationnelles (ODS)
- Méthodologies de conception d’entrepôt de données
- Bill Inmon – Approche de conception d’entrepôt de données Descendante
- Ralph Kimball – Approche ascendante de conception d’entrepôts de données
- Prochaines étapes
- À propos de l’auteur
Problème
Dans mes derniers conseils, j’ai parlé de l’importance d’une solution de Business Intelligence, pourquoi elle devient prioritaire pourexécutifs, quelle est une solution typique L’architecture du système de Business Intelligence ressemble, etc. Dans cette astuce, je vais parler en détail de la différence entre un entrepôt de données et un magasin de données opérationnel et des différentes méthodologies de conception d’un entrepôt de données.
Solution
Cette astuce va couvrir les Entrepôts de données (DW, parfois aussi appelé Entrepôt de données d’entreprise ou EDW), en quoi il diffère du Magasin de Données opérationnelles (ODS) et des différentes méthodologies de conception d’Entrepôt de données.
Entrepôt de données d’entreprise (EDW ou DW) Vs. Magasin de données opérationnelles (ODS)
Le but de l’entrepôt de données dans l’architecture globale de Business Intelligence est d’intégrer des données d’entreprise provenant de différentes sources de données hétérogènes afin de faciliter les rapports d’analyse historique et de tendance. Il agit comme un référentiel central et contient la « version unique de la vérité » pour l’organisation qui a été soigneusement construite à partir de données stockées dans des bases de données opérationnelles internes et externes disparates \ systèmes. Pour de meilleures performances, la plupart des données de l’entrepôt de données seront sous une forme normalisée qui peut être catégorisée dans des schémas en étoile ou en flocon de neige (plus à ce sujet dans la prochaine astuce).
Le but du Magasin de données opérationnelles (ODS) est d’intégrer des données d’entreprise provenant de différentes sources de données hétérogènes afin de faciliter le reporting opérationnel en temps réel ou quasi réel. Souvent, les données du SACO seront structurées de manière similaire aux systèmes sources, bien que lors de l’intégration, cela puisse impliquer un nettoyage des données, une déduplication et l’application de règles métier pour assurer l’intégrité des données. Un SACO est principalement destiné à intégrer des données assez fréquemment au niveau granulaire le plus bas pour le reporting opérationnel dans un scénario d’intégration de données proche du temps réel. Normalement, une SACO ne sera pas optimisée pour l’analyse historique et des tendances sur un vaste ensemble de données.
Résumons les différences entre un SACO et un DW:
- Un SACO est destiné au reporting opérationnel et prend en charge les exigences de reporting actuelles ou en temps quasi réel, tandis qu’un SACO est destiné aux rapports d’analyse historique et de tendance sur un grand volume de données
- Un SACO est ciblé pour les requêtes peu granulaires, tandis qu’un SACO est utilisé pour les requêtes complexes au niveau du résumé ou sur des données agrégées
- Un SACO fournit des informations pour les décisions opérationnelles et tactiques concernant l’acquisition de données en temps actuel ou quasi réel où un SACO fournit des informations pour les décisions opérationnelles et tactiques concernant l’acquisition de données en temps réel ou presque. DW fournit une rétroaction pour les décisions stratégiques menant à des améliorations globales du système
- Dans un ODS le la fréquence de chargement des données peut être horaire ou quotidienne alors que dans un DWLA fréquence de chargement des données peut être quotidienne, hebdomadaire, mensuelle ou trimestrielle
Méthodologies de conception d’entrepôt de données
Il existe deux méthodologies différentes normalement suivies lors de la conception d’une solution d’entrepôt de données et en fonction des exigences de votre projet, vous pouvez choisir celle qui convient à votre scénario particulier. Ces méthodologies sont le résultat de recherches menées par BillInmon et Ralph Kimball.
Bill Inmon – Approche de conception d’entrepôt de données Descendante
Bill Inmon est parfois également appelé le « père de l’entreposage de données »; sa méthodologie de conception est basée sur une approche descendante et définit l’entrepôt de données en ces termes
- Orienté sujet – Les données d’un entrepôt de données sont classées en fonction du domaine et sont donc « orientées sujet ».
- Intégré – Les données sont intégrées à partir de différentes sources de données disparates et, par conséquent, des conventions de dénomination universelles, des mesures, des classifications, etc. utilisées dans l’entrepôt de données. L’entrepôt de données fournit une vue consolidée des données de l’entreprise et est donc désigné comme une solution intégrée.
- Non volatile – Une fois les données intégrées \ chargées dans l’entrepôt de données, elles ne peuvent être lues que. Les utilisateurs ne peuvent pas apporter de modifications aux données et cette pratique rend les données non volatiles.
- Variante temporelle – Enfin, les données sont stockées pendant de longues périodes quantifiées en années et ont une date et un horodatage et sont donc décrites comme une « variante temporelle ».
Bill Inmon a constaté la nécessité d’intégrer les données de différents systèmes OLTP dans un référentiel centralisé (appelé entrepôt de données) avec une approche dite descendante. Bill Inmon envisage un entrepôt de données au centre de la « Corporate Information Factory » (CIF), qui fournit un cadre logique pour fournir des capacités de business intelligence (BI), d’analyse commerciale et de gestion d’entreprise.
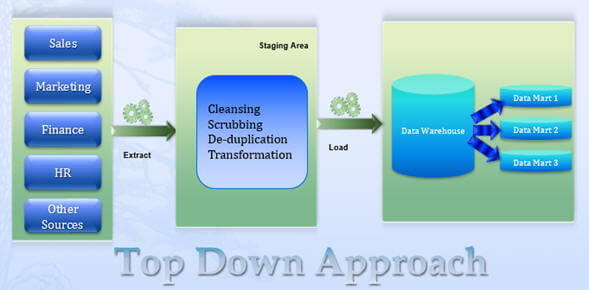
Cette conception descendante fournit une vue dimensionnelle très cohérente des données sur les magasins de données, car tous les magasins de données sont chargés à partir du référentiel centralisé (Entrepôt de données).La conception descendante s’est également avérée flexible pour soutenir les changements opérationnels dans l’ensemble de l’organisation, et non à chaque fonction ou processus métier de l’organisation. Générer de nouveaux marts de données dimensionnelles par rapport aux données stockées dansl’entrepôt de données est une tâche relativement simple. Bien qu’il y ait quelques défis pour l’approche descendante, par exemple, il s’agit d’un projet de très grande envergure avec une portée très large et, par conséquent, le coût initial de la mise en œuvre d’un entrepôt de données utilisant la méthodologie descendante est important.De plus, la durée entre le début du projet et le moment où les utilisateurs finaux commencent à bénéficier des avantages initiaux de la solution peut être importante. De plus, la méthodologie descendante peut être inflexible et ne pas répondre aux besoins changeants des processus ministériels ou opérationnels (une préoccupation pour l’environnement actuel en évolution dynamique) pendant la phase de mise en œuvre.
Ralph Kimball – Approche ascendante de conception d’entrepôts de données
Ralph Kimball est un auteur renommé sur le thème de l’entreposage de données. Sa méthodologie de conception s’appelle modélisation dimensionnelle oula méthodologie Kimball. Cette méthodologie se concentre sur une approche ascendante, en mettant l’accent sur la valeur de l’entrepôt de données pour les utilisateurs le plus rapidement possible. Dans sa vision, un entrepôt de données est la copie des données transactionnelles spécifiquement structurées pour l’interrogation analytique et le reporting afin de soutenir le système d’aide à la décision. Selon sa méthodologie, les data marts sont d’abord créés pour fournir des capacités de reporting et d’analyse pour des processus fonctionnels spécifiques et, plus tard, ces data marts peuvent éventuellement être combinés pour créer un entrepôt de données d’entreprise complet. L’approche ascendante se concentre sur chaque processus métier à un moment donné, de sorte que le retour sur investissement pourrait être aussi rapide que la création de first data mart. Bien que s’il n’est pas soigneusement planifié, vous risquez de ne pas avoir une vue d’ensemble de l’entrepôt de données d’entreprise en manquant certaines dimensions ou en créant des dimensions redondantes, etc. lorsque vous êtes trop concentré sur un processus métier individuel.
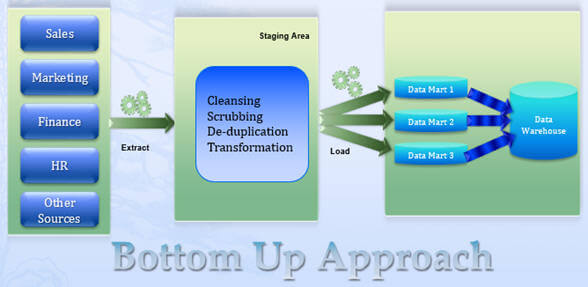
L’approche ascendante de Ralph Kimball propose de créer une matrice métier qui devrait contenir tous les éléments communs (utilisés par les data marts tels que la dimension conforme\partagée, les mesures, etc.) défini pour l’ensemble de l’entreprise. Avec cela, l’utilisateur peut concevoir et développer des solutions qui prennent en charge l’analyse des processus métier pour la vente croisée. Vous pouvez en savoir plus sur la matrice ici.
Pour une personne qui souhaite faire carrière dans le domaine de l’Entrepôt de données et de l’informatique décisionnelle, j’ai recommandé d’étudier les livres de Bill Inmon (Building the Data Warehouse et DW 2.0: The Architecture for the Next Generation of Data Warehousing) et le livre de Ralph Kimball (The Microsoft Data Warehouse Toolkit).
Prochaines étapes
- Avismicrosoft SQL Server Business Intelligence – Quoi, Pourquoi et comment – Partie 1.
- Avisarchitecture du système d’intelligence d’affaires MICROSOFT SQL Server – Partie 2.
- Découvrez tous les conseils de Business Intelligence du serveur SQL sur MSSQLTips.com.
Dernière Mise à Jour: 2013-06-24


À propos de l’auteur
 Arshad Ali est un développeur SQL et BI spécialisé dans les projets d’entreposage de données pour Microsoft.
Arshad Ali est un développeur SQL et BI spécialisé dans les projets d’entreposage de données pour Microsoft.Voir tous mes conseils
- Plus de conseils en Business Intelligence…