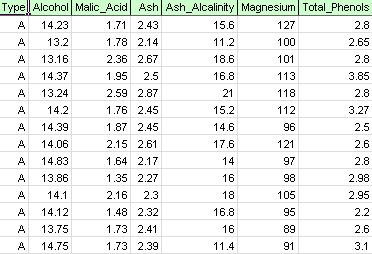
Sur le ruban XLMiner, dans l’onglet Appliquer Votre modèle, sélectionnez Aide-Exemples, puis Exemples de prévision / Exploration de données, et ouvrez le fichier d’exemple Wine.xlsx. Comme le montre la figure ci-dessous, chaque ligne de cet exemple de jeu de données représente un échantillon de vin prélevé dans l’un des trois établissements vinicoles (A, B ou C). Dans cet exemple, la variable Type représentant la cave est ignorée et le regroupement est effectué simplement sur la base des propriétés des échantillons de vin (les variables restantes).
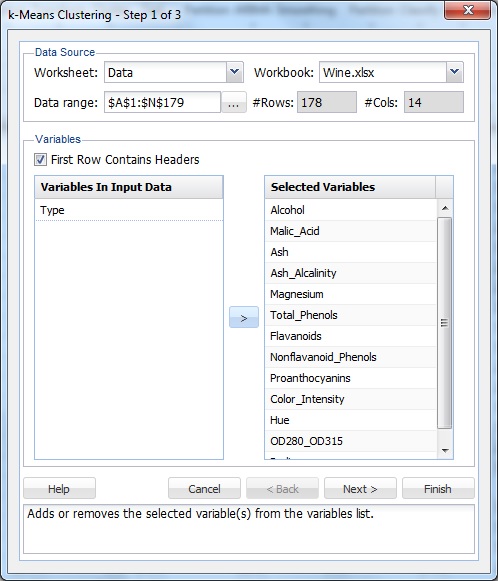
Sélectionnez une cellule dans l’ensemble de données, puis sur le ruban XLMiner, dans l’onglet Analyse de données, sélectionnez XLMiner-Cluster-k-Means Clustering pour ouvrir la boîte de dialogue Étape 1 de 3 de Clustering k-Means.
Dans la liste des variables, sélectionnez toutes les variables sauf le type, puis cliquez sur le bouton > pour déplacer les variables sélectionnées vers la liste des variables sélectionnées.
Cliquez sur Suivant pour passer à la boîte de dialogue Étape 2 de 3.
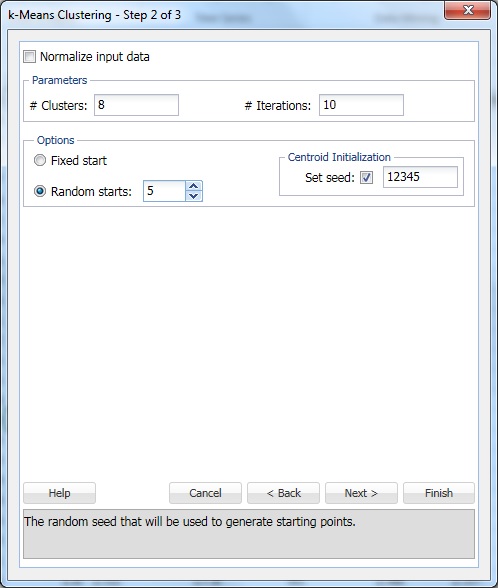
À #Clusters, entrez 8. Il s’agit du paramètre k de l’algorithme de clustering k-means. Le nombre de grappes doit être d’au moins 1 et au plus le nombre d’observations -1 dans la plage de données. Définissez k sur plusieurs valeurs différentes et évaluez la sortie de chacune.
Laissez #Itérations au réglage par défaut de 10. La valeur de cette option détermine combien de fois le programme commencera avec une partition initiale et terminera l’algorithme de clustering. La configuration des clusters (et la séparation des données) peut différer d’une partition de départ à l’autre. Le programme parcourra le nombre d’itérations spécifié et sélectionnera la configuration du cluster qui minimise la mesure de distance.
Définissez les démarrages aléatoires sur 5. Lorsque cette option est sélectionnée, l’algorithme commence à construire le modèle à partir de n’importe quel point aléatoire. XLMiner génère cinq ensembles de clusters et génère la sortie en fonction du meilleur cluster.
Set seed est sélectionné par défaut. Cette option initialise le générateur de nombres aléatoires utilisé pour calculer les centroïdes de cluster initiaux. La définition de la graine de nombres aléatoires à une valeur non nulle (valeur par défaut 12345) garantit que la même séquence de nombres aléatoires est utilisée chaque fois que les centroïdes de cluster initiaux sont calculés. Lorsque la graine est nulle, le générateur de nombres aléatoires est initialisé à partir de l’horloge système, de sorte que la séquence de nombres aléatoires est différente à chaque initialisation des centroïdes. Définissez la graine pour afficher les exécutions successives de la méthode de clustering comme comparables.
Sélectionnez l’option Normaliser les données d’entrée pour normaliser les données. Dans cet exemple, les données ne seront pas normalisées. Sélectionnez Suivant pour ouvrir la boîte de dialogue Étape 3 de 3.
Sélectionnez Afficher le résumé des données (par défaut) et Afficher les distances à partir de chaque centre de cluster (par défaut), puis cliquez sur Terminer.
La méthode de Clustering k-Means commence par k clusters initiaux comme spécifié. À chaque itération, les enregistrements sont affectés au cluster avec le centroïde ou centre le plus proche. Après chaque itération, la distance entre chaque enregistrement et le centre du cluster est calculée. Ces deux étapes sont répétées (affectation de l’enregistrement et calcul de la distance) jusqu’à ce que la redistribution d’un enregistrement entraîne une augmentation de la valeur de la distance.
Lorsqu’un début aléatoire est spécifié, l’algorithme génère les k centres de cluster de manière aléatoire et adapte les points de données de ces clusters. Ce processus est répété pour tous les démarrages aléatoires spécifiés. La sortie est basée sur les clusters qui présentent le meilleur ajustement.
La feuille de calcul KM_Output1 est insérée immédiatement à droite de la feuille de calcul de données. Dans la section supérieure de la feuille de calcul de sortie, les options sélectionnées sont répertoriées.
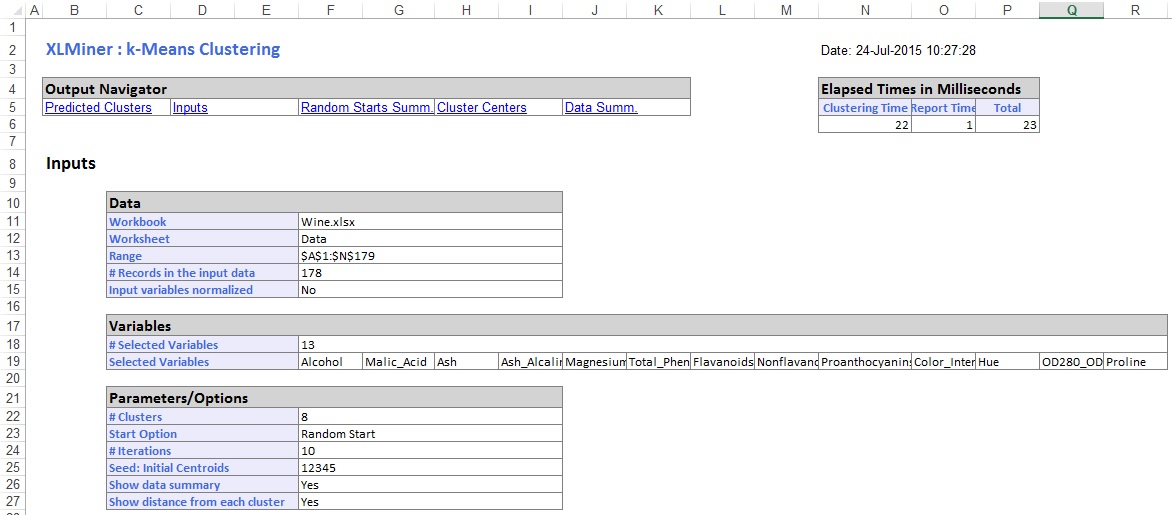
Dans la section centrale de la feuille de calcul de sortie, XLMiner a calculé la somme des distances au carré et déterminé le début avec la somme la plus faible de la Distance au carré comme Meilleur début (#5). Une fois le Meilleur Départ déterminé, XLMiner génère la sortie restante en utilisant le Meilleur départ comme point de départ.
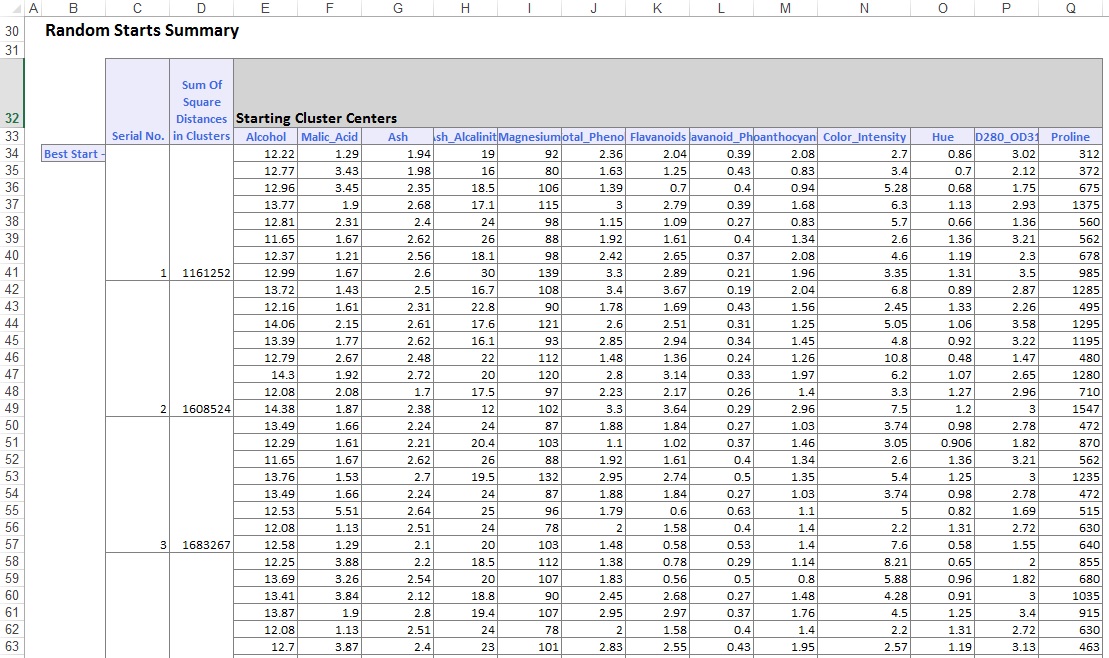
Dans la partie inférieure de la feuille de calcul de sortie, XLMiner a répertorié les centres de cluster (indiqués ci-dessous). La zone supérieure affiche les valeurs des variables au centre du cluster. Le groupe 8 a la teneur moyenne en alcool, en phénols totaux, en Flavanoïdes, en Proanthocyanines, en Intensité de couleur, en Teinte et en Proline la plus élevée. Comparez ce cluster au cluster 2, qui a la calinité d’ASH_ et les phénols nonflavanoïd_aux moyens les plus élevés.
La case inférieure indique la distance entre les centres du cluster. À partir des valeurs de ce tableau, il est déterminé que le cluster 3 est très différent du Cluster 8 en raison de la valeur de distance élevée de 1 176,59 et que le cluster 7 est proche du Cluster 3 avec une valeur de distance faible de 89,73.
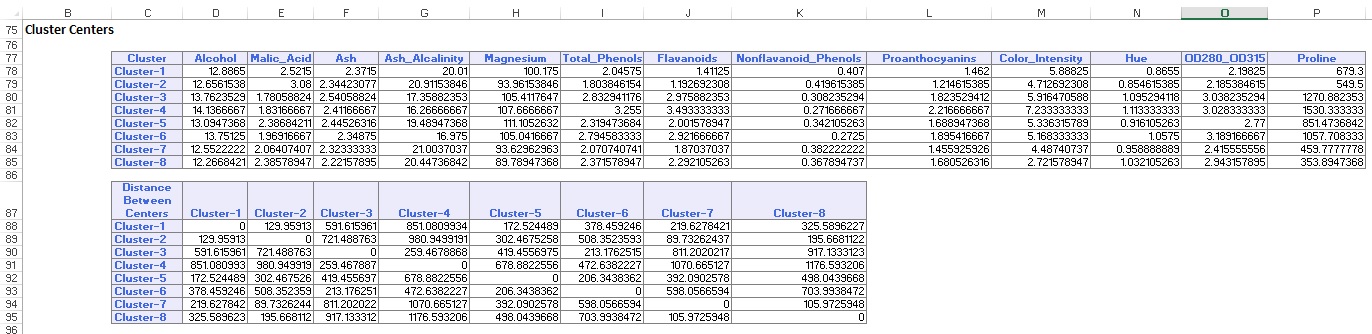
Le résumé des données (ci-dessous) affiche le nombre d’enregistrements (observations) inclus dans chaque cluster et la distance moyenne entre les membres du cluster et le centre de chaque cluster. Le groupe 6 a la distance moyenne la plus élevée de 42,79 et comprend 24 enregistrements. Comparez ce cluster au cluster 2, qui a la plus petite distance moyenne de 29,66, et comprend 26 membres.
Cliquez sur la feuille de calcul KM_Clusters1. Cette feuille de calcul affiche le cluster auquel chaque enregistrement est affecté et la distance par rapport à chacun des clusters. Pour le premier enregistrement, la distance au cluster 6 est la distance minimale de 23,205, ce premier enregistrement est donc affecté au cluster 6.