először a kettős formájú lineáris/gerinc regressziót vizsgáljuk, mielőtt megmutatnánk, hogyan kell ‘kernelizálni’. Az utóbbi magyarázatánál látni fogjuk, hogy mik a kernelek, és mi a ‘kerneltrükk’.
kettős formájú gerinc regresszió
a lineáris regressziót általában elsődleges formában adják meg oszlopok (jellemzők) lineáris kombinációjaként. Létezik azonban egy második, kettős forma, ahol ez egy új nullapont belső termékének lineáris kombinációja (amelyre következtetést hajtunk végre) az egyes képzési adatokkal.
figyelembe vesszük a gerinc regresszió esetét (L2 regularizált lineáris regresszió), emlékezve arra, hogy az alapvető lineáris regresszió megfelel annak az esetnek, amikor \(\lambda = 0\). Ezután a gerinc regressziójának képletei, ahol \(X\) és \(Y\) A \(N \times m\) képzési adatokra és \(x^\prime,y^\prime\) egy új becslendő esetre vonatkoznak, a következők:
\ \ \ \
ahol \(\langle X_i, x^ \ prime \ rangle\) a belső/pont termék, tehát \(\langle X_i,x^\prime \rangle = X^T_i x^\prime = \sum_j^m X_{I,j} x^\prime_j\).
a kettős forma azt mutatja, hogy a lineáris/gerinc regresszió úgy is értelmezhető, hogy becslést ad egy új eset belső szorzatának súlyozott összegéről az egyes képzési eseteknél.
ez azt jelenti, hogy lineáris regressziót végezhetünk akkor is, ha több oszlop van, mint sor, bár ennek fontosságát túlbecsülhetjük, mivel (i) ezt egyébként is megtehetjük a L2 regularizáció mivel ez mindig invertálhatóvá teszi a \(X^TX\) mátrixot; és (ii) a \(XX^T\) mátrix gyakran megkövetelheti L2 regularizáció egyébként az inverzió numerikus stabilitásának biztosítása érdekében. Ez lehetővé teszi számunkra, hogy a lineáris regressziót sokkal inkább egy szekvenciális tanulási folyamatnak tekintsük, ahol a képzési adatok minden további nullapontja valami újat hoz.
a legfontosabb a mi céljainkra, bár, a kettős forma van az érdekes jellemző: jellemző Vektorok fordulnak elő az egyenletek csak belső termékek. Ez még a \(\alpha\) definíciójában is igaz, mivel a \(XX^T\) a képzési adatokban szereplő minden jellemzővektorpár belső termékének megfelelő mátrixot állítja elő. Látni fogjuk ennek fontosságát, ahogy haladunk.
félre: az érdeklődő diákok láthatják, hogy a kettős forma származik a levezetése kettős formában dokumentum elérhető a letöltések szakasz végén ezt a cikket.
nemlineáris kettős gerinc regresszió
a kettős formájú gerinc regressziónkat nemlineáris modellré alakíthatjuk a nemlineáris jellemző transzformációk \ (\phi\):
\ \
Kernel függvények
a kernel függvény, \(K: \mathcal X \times \mathcal X \to\ mathbb{R}\), egy olyan függvény,amely szimmetrikus – \ (K(x_1,x_2)=K(x_2, x_1)\) – és pozitív határozott (lásd a félre a formális definíciót). A pozitív meghatározást a matematikában használják, amely igazolja a magok használatát. De jelentős matematikai ismeretek nélkül a meghatározás nem intuitív módon megvilágító. Tehát ahelyett, hogy megpróbálnánk megérteni a kerneleket a pozitív definiteness definíciójából, számos példával mutatjuk be őket.
mielőtt ezt megtennénk, megjegyezzük, hogy bár a kernelek két argumentumfüggvények, gyakori, hogy úgy gondolják, hogy az első argumentumuknál helyezkednek el, és a második függvényük. Ezen értelmezés szerint olyan jelöléseket fog látni, mint \(K_x(y)\), amely egyenértékű \(K(x, y)\) . Különösen gyakran gondolunk arra, hogy a kernelek egyetlen argumentumfüggvények, amelyek az adatpontokban (jellemző Vektorok) helyezkednek el a képzési adatainkban. Néha azt fogja olvasni, hogy magokat dobunk az adatpontokra. Tehát , ha van egy \(x_i\) funkcióvektorunk , akkor egy kernelt dobunk rá, ami a \(x_i\) helyen található \(k_{x_i} (x)\) függvényhez vezet,amely egyenértékű a \(K(x_i, x)\) – vel .
azt is megjegyezzük, hogy a kerneleket gyakran paraméteres családok tagjaiként határozzák meg. Ilyen kernelcsaládok például:
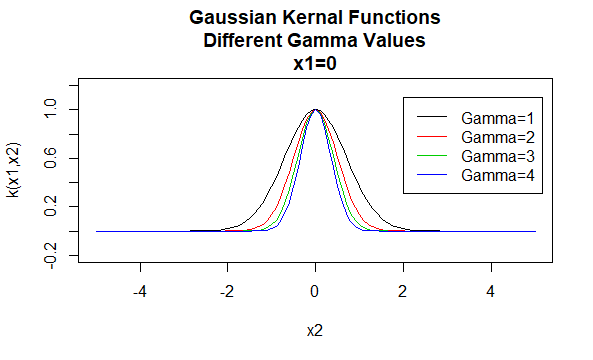
Gauss-kernelek
a Gauss-kernelek a radiális bázisfüggvény kernelek példái, amelyeket néha radiális bázis kerneleknek neveznek. A radiális bázisfüggvény kernel értéke csak az argumentumvektorok közötti távolságtól függ, nem pedig azok helyétől. Az ilyen magokat helyhez kötöttnek is nevezik.
paraméterek: \(\gamma\)
egyenlet formája: \(K (X_1, X_2)=e^{- \gamma \ / X_1-X_2 \|^2}\)
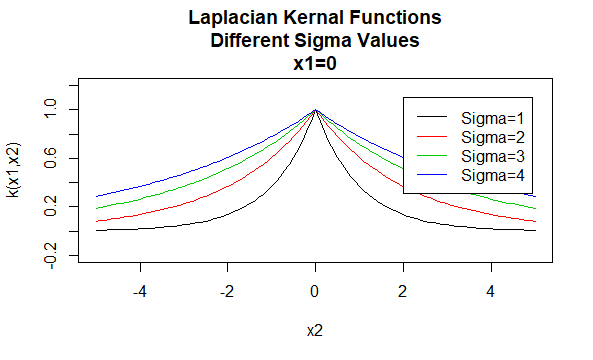
Laplacian magok
Laplacian magok is radiális bázisfüggvények.
paraméterek: \(\sigma\)
egyenlet forma: \(K (X_1, X_2) = e^{-\frac{\| X_1 – X_2 \|}{\sigma}}\)
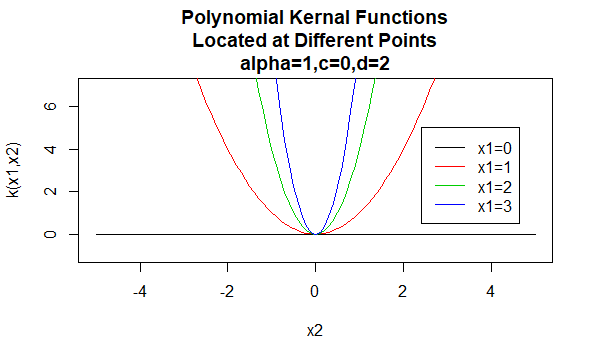
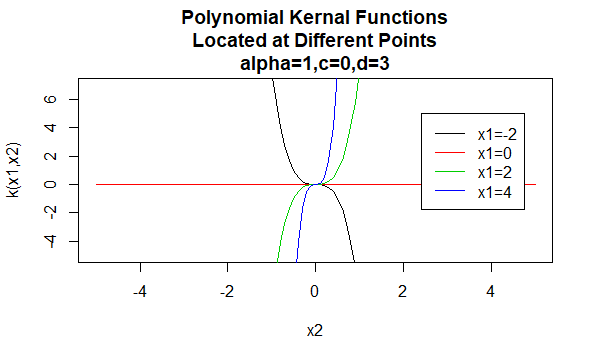
polinom magok
a polinom magok a nem stacionárius magok példái. Tehát ezek a kernelek értékeik alapján különböző értékeket rendelnek az azonos távolságú pontpárokhoz. A paraméterértékeknek nem negatívnak kell lenniük annak biztosítása érdekében, hogy ezek a magok pozitívak legyenek határozott.
paraméterek: \(\alpha , c , d\)
egyenlet forma: \(K(X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
a kernelcsalád paramétereinek meghatározott értékeinek megadása kernelfüggvényt eredményez. Az alábbiakban példákat mutatunk be a fenti családok magfüggvényeire, amelyek különböző pontokon elhelyezkedő paraméterértékekkel rendelkeznek (azaz a megrajzolt grafikon a második argumentum függvénye, az első argumentum meghatározott értékre állítva).
Félre: Az érdeklődő diákok láthatják a kernelek pozitív definíciójának meghatározását a Kernels and Positive Definiteness dokumentumban, amely a cikk végén található Letöltések részben érhető el.
a Kernel trükk
a kernel függvények fontossága egy nagyon különleges tulajdonságból származik: Minden pozitív-határozott kernel, \(k\) kapcsolódik egy matematikai térhez, \(\mathcal{H}_K\), (a kernel reprodukáló kernelének nevezik Hilbert-tér (RKHS)) oly módon, hogy \(K\) alkalmazása két jellemzővektorra, \(X_1, X_2\) egyenértékű azzal, hogy ezeket a funkcióvektorokat \(\mathcal{H}_K\) – ba vetítjük valamilyen vetítési funkcióval, \(\phi\) és a belső terméküket oda vesszük:
\
a kernelekhez társított RKHSs jellemzően nagy dimenziójú. Néhány mag esetében, mint például a Gauss-család magjai, végtelen dimenziósak.
a fentiek a híres ‘kerneltrükk’ alapját képezik: ha a bemeneti jellemzők csak belső termékek formájában vesznek részt egy statisztikai modell egyenletében, akkor az egyenletben lévő belső termékeket helyettesíthetjük a kernelfüggvény hívásaival, és az eredmény olyan, mintha a bemeneti jellemzőket egy magasabb dimenziós térbe vetítettük volna (azaz olyan tulajdonságátalakítást hajtottunk végre, amely nagyszámú látens változó jellemzőhöz vezetett), és a belső terméküket oda vettük volna. De soha nem kell végrehajtanunk a tényleges vetítést.
a gépi tanulás terminológiájában a kernelhez társított RKH-k feature space néven ismertek, szemben a bemeneti térrel. A kernel trükkjén keresztül implicit módon kivetítjük a bemeneti jellemzőket ebbe a funkciótérbe, és oda visszük a belső terméküket.
Kernel regresszió
ez a rendszermag regresszió néven ismert technikához vezet. Ez egyszerűen a kernel trükk alkalmazása a gerinc regresszió kettős formájára. A könnyebb bevezetjük az ötlet a Kernel, vagy Gram, mátrix, \(K\), oly módon,hogy \(k_{i, j}=k(X_i, X_j)\). Ezután írhatjuk a kernel regressziójának egyenleteit:
\ \
ahol \(k\) valamilyen pozitív-határozott kernelfüggvény.
a Representer tétel
fontolja meg az optimalizálási problémát, amelyet meg akarunk oldani, amikor valamilyen formájú modell L2 szabályozását végezzük, \(f\):
\
amikor kernel regressziót hajt végre kernel \(k\), a szabályozási elmélet fontos eredménye, hogy a fenti egyenlet minimalizálója a következő lesz:
\
\ (\alpha\) a fent leírtak szerint számítva.
ez az igazságosan lionizált Representer tétel. Szavakban azt mondja, hogy a lineáris regresszió optimalizálási problémájának minimalizálóját az adott kernel által kapott implicit jellemzőtérben (és így a nemlineáris kernel regressziós probléma minimalizálóját) az egyes jellemzővektorokban található magok súlyozott összege adja meg.
sokkal többet kell mondani ebben a témában. Még azt is kidolgozhatjuk, hogy a zöld függvény (amelynek magjai részhalmazai) minimalizálja az egyes szabályozási specifikációkat, például az L2 szabályozást, de a lineáris differenciál operátoron alapuló bármilyen büntetést is. Ez a kapcsolat a kernelek és a Tyihonov szabályozási problémák optimális megoldásai között alapvető oka a kernelmódszerek fontosságának a gépi tanulásban. De a matematika itt túl van ezen a kurzuson, és az érdeklődő haladó diákokat Haykin neurális hálózatai és tanulási gépei hetedik fejezetére utalják.
ez matematikai igazolást ad a kernel regresszió használatára azokban az esetekben, amikor ez lehetséges. Az optimális kernel tényleges kidolgozása általában nem lehetséges – ehhez ismerni kell az optimális lineáris differenciál operátort, amelyet a szabályozási büntetéshez kell használni. Kiszámítottuk azokat a függvényeket, amelyekre ki kell vetítenünk az egyes szabályozási büntetések optimalizálását, és tudjuk például, hogy a vékony lemez spline kernel optimális az L2 szabályozásához. Lefelé nézve, mivel ki kell számolnunk a Gram mátrixot, a kernel regressziója nem skálázódik jól – nagy adatkészletek esetén a neurális hálózatokra való áttérés jobb ötlet.