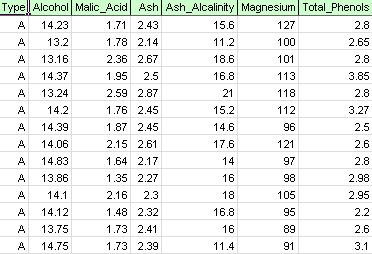
az XLMiner menüszalagon a A modell alkalmazása lapon válassza a Súgó – példák, majd előrejelzés/adatbányászati példák, majd nyissa meg a példa fájlt bor.xlsx. Amint az az alábbi ábrán látható, a példa adatkészletének minden sora a három pincészet (A, B vagy C) egyikéből vett bormintát képviseli. Ebben a példában a borászatot reprezentáló Type változót figyelmen kívül hagyjuk, a csoportosítást pedig egyszerűen a borminták tulajdonságai (a fennmaradó változók) alapján hajtjuk végre.
Jelöljön ki egy cellát az adatkészleten belül, majd az Xlminer menüszalagon Az adatelemzés lapon válassza az XLMiner – Cluster – k-Means fürtözés lehetőséget a k-Means fürtözés 1/3 lépés párbeszédpanel megnyitásához.
a változók listából válassza ki az összes változót, kivéve a típust, majd kattintson a > gombra a kiválasztott változók listájába való áthelyezéséhez.
kattintson a Tovább gombra, hogy továbblépjen a 2. lépés a 3 párbeszédablak.
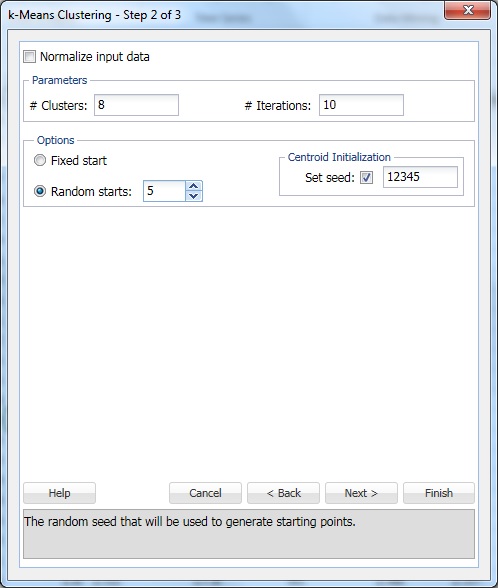
a # klaszterek, írja 8. Ez a K paraméter a k-azt jelenti, klaszterezési algoritmus. A klaszterek számának legalább 1-nek, legfeljebb a megfigyelések számának -1-nek kell lennie az adattartományban. Állítsa be a k értéket több különböző értékre, és értékelje az egyes kimeneteket.
hagyja a #iterációkat az alapértelmezett 10-es beállításnál. Ennek az opciónak az értéke határozza meg, hogy a program hányszor indul el egy kezdeti partícióval, és befejezi a fürtözési algoritmust. A klaszterek konfigurációja (és az adatok elválasztása) kiindulási partíciónként eltérő lehet. A program a megadott számú iteráción megy keresztül, és kiválasztja a fürtkonfigurációt, amely minimalizálja a távolságmérést.
állítsa véletlen kezd 5. Ha ezt az opciót választja, az algoritmus bármilyen véletlenszerű pontból elkezdi építeni a modellt. XLMiner generál öt klaszter készletek és generálja a kimenetet alapján a legjobb klaszter.
alapértelmezés szerint a Set seed van kiválasztva. Ez az opció inicializálja a véletlenszám-generátort, amelyet a kezdeti klaszter-centroidok kiszámításához használnak. Ha a véletlenszám-magot nem nulla értékre állítja (alapértelmezett 12345), biztosítja, hogy a véletlen számok ugyanazt a sorozatát használják minden alkalommal, amikor a kezdeti klaszter-centroidokat kiszámítják. Amikor a mag nulla, a véletlenszám-generátort a rendszer órájából inicializálják, így a véletlen számok sorrendje minden egyes centroid inicializálásakor eltérő. Állítsa be a vetőmagot úgy, hogy a fürtözési módszer egymást követő futtatásait összehasonlíthatónak tekintse.
az adatok normalizálásához válassza a bemeneti adatok normalizálása lehetőséget. Ebben a példában az adatok nem lesznek normalizálva. Válassza a Tovább lehetőséget a 3 / 3 lépés párbeszédpanel megnyitásához.
válassza az adatösszegzés megjelenítése (Alapértelmezett) lehetőséget, majd az egyes fürtközpontok távolságának megjelenítése (Alapértelmezett) lehetőséget, majd kattintson a Befejezés gombra.
a k-azt jelenti, klaszterezés módszer kezdődik K kezdeti klaszterek megadott. Minden iterációnál a rekordok a legközelebbi centroiddal vagy középponttal rendelkező fürthöz vannak hozzárendelve. Minden iteráció után kiszámítják az egyes rekordoktól a fürt középpontjáig terjedő távolságot. Ezt a két lépést addig ismételjük (a rekord hozzárendelése és a távolság kiszámítása), amíg a rekord újraelosztása megnövelt távolságértéket nem eredményez.
véletlenszerű indítás esetén az algoritmus véletlenszerűen generálja a K klaszterközpontokat, és illeszkedik a klaszterek adatpontjaihoz. Ez a folyamat megismétlődik az összes megadott véletlenszerű indításkor. A kimenet azon klasztereken alapul, amelyek a legjobban illeszkednek.
a km_output1 munkalap közvetlenül az adat munkalap jobb oldalára kerül beillesztésre. A kimeneti munkalap felső részében a kiválasztott beállítások szerepelnek.
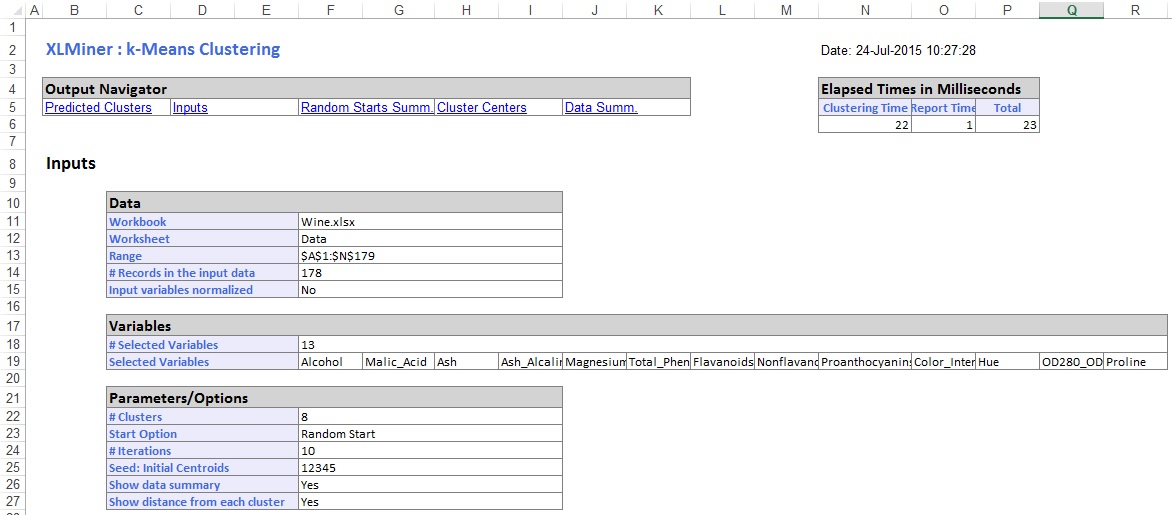
a kimeneti munkalap középső szakaszában az XLMiner kiszámította a négyzet távolságok összegét, és meghatározta a kezdetet a négyzet távolságának legalacsonyabb összegével, mint a legjobb kezdéssel (#5). A legjobb indítás meghatározása után az XLMiner a fennmaradó kimenetet a legjobb indítás alapján állítja elő kiindulási pontként.
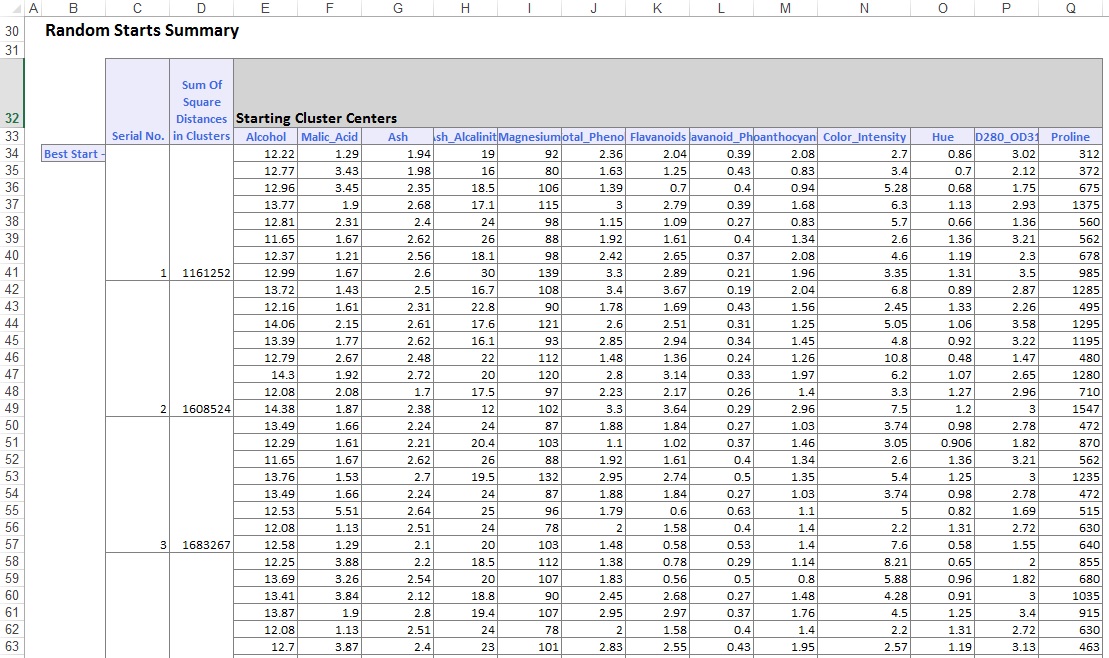
a kimeneti munkalap alsó részében az XLMiner felsorolta a Klaszterközpontokat (alább látható). A felső mező a Fürtközpontok változó értékeit mutatja. Cluster 8 a legmagasabb átlagos alkohol, Total_Phenols, Flavanoids, Proanthocyanins, Color_Intensity, Hue, és prolin tartalom. Hasonlítsa össze ezt a klasztert a 2. Klaszterrel,amely a legmagasabb átlagos Ash_Alcalinity és Nonflavanoid_Phenols.
az alsó mező a Klaszterközpontok közötti távolságot mutatja. Az ebben a táblázatban szereplő értékekből megállapítható, hogy a 3.klaszter nagyon különbözik a 8.Klasztertől az 1176,59 nagy távolságérték miatt, a 7. klaszter pedig közel van a 3. klaszterhez, kis távolságértéke 89,73.
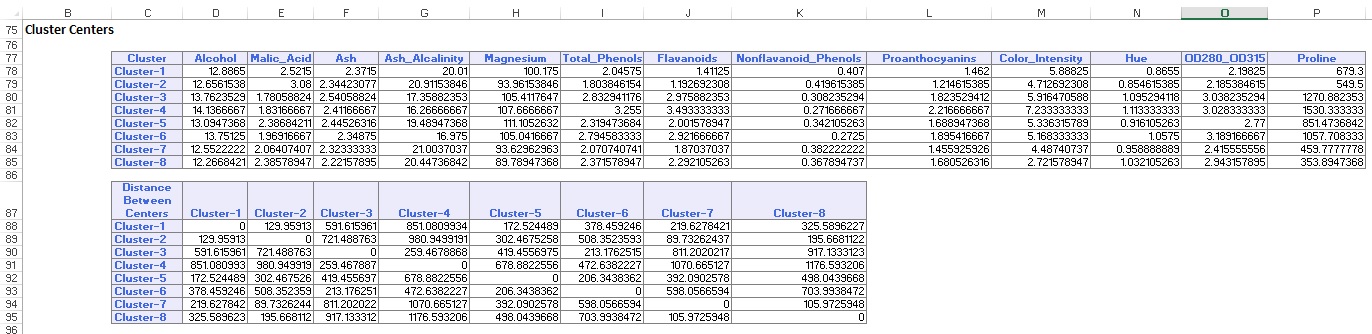
az Adatösszefoglaló (alább) megjeleníti az egyes fürtökben szereplő rekordok (megfigyelések) számát, valamint a fürttagoktól az egyes klaszterek középpontjáig terjedő átlagos távolságot. A 6-os klaszter legnagyobb átlagos távolsága 42,79, és 24 rekordot tartalmaz. Hasonlítsa össze ezt a klasztert a 2. Klaszterrel, amelynek legkisebb átlagos távolsága 29,66, és 26 tagot tartalmaz.
kattintson a KM_Clusters1 munkalapra. Ez a munkalap megjeleníti azt a fürtöt, amelyhez az egyes rekordok hozzá vannak rendelve, valamint az egyes klaszterek távolságát. Az első rekord esetében a 6. fürt távolsága a minimális távolság 23,205, tehát ez az első rekord a 6.fürthöz van rendelve.