képzelje el, hogy van olyan eszköze, amely automatikusan felismeri a JPA-t és hibernálja a teljesítményproblémákat. A Hypersistence Optimizer az az eszköz!
Bevezetés
ha kíváncsi arra, hogy miért és mikor kell használni a JPA-t vagy a hibernált állapotot, akkor ez a cikk választ fog adni erre a nagyon gyakori kérdésre. Mivel nagyon gyakran láttam ezt a kérdést a /R/java Reddit csatornán, úgy döntöttem, hogy érdemes mélyreható választ írni a JPA és a Hibernate erősségeiről és gyengeségeiről.
bár a JPA 2006-os megjelenése óta szabvány, nem ez az egyetlen módja az adatelérési réteg megvalósításának a Java használatával. Megvitatjuk a JPA vagy bármely más népszerű alternatíva használatának előnyeit és hátrányait.
miért és mikor jött létre a JDBC
1997-ben, Java 1.1 bevezette a JDBC (Java Database Connectivity) API-t, amely nagyon forradalmi volt a maga idejében, mivel lehetőséget kínált arra, hogy az adatelérési réteget egyszer egy interfészkészlet használatával írja le, és bármilyen relációs adatbázisban futtassa, amely megvalósítja a JDBC API-t anélkül, hogy módosítania kellene az alkalmazás kódját.
a JDBC API egy Connection interfészt kínált a tranzakciós határok vezérlésére és egyszerű SQL utasítások létrehozására a Statement API-n keresztül, vagy előkészített utasítások, amelyek lehetővé teszik a paraméterértékek PreparedStatement API-n keresztüli kötését.
tehát, feltételezve, hogy van egy post adatbázis tábla, és szeretnénk beszúrni 100 sorok, itt van, hogyan tudtuk elérni ezt a célt JDBC:
int postCount = 100;int batchSize = 50;try (PreparedStatement postStatement = connection.prepareStatement(""" INSERT INTO post ( id, title ) VALUES ( ?, ? ) """)) { for (int i = 1; i <= postCount; i++) { if (i % batchSize == 0) { postStatement.executeBatch(); } int index = 0; postStatement.setLong( ++index, i ); postStatement.setString( ++index, String.format( "High-Performance Java Persistence, review no. %1$d", i ) ); postStatement.addBatch(); } postStatement.executeBatch();} catch (SQLException e) { fail(e.getMessage());}
bár kihasználtuk a többsoros szövegblokkok és a try-with-resources blokkok előnyeit a PreparedStatement close hívás kiküszöbölésére, a megvalósítás még mindig nagyon részletes. Ne feledje, hogy a kötési paraméterek 1-tól kezdődnek, nem pedig 0 – tól, mint más jól ismert API-knál.
az első 10 sor letöltéséhez szükség lehet egy SQL lekérdezés futtatására a PreparedStatement-on keresztül, amely ResultSet értéket ad vissza, amely a tábla alapú lekérdezés eredményét képviseli. Mivel azonban az alkalmazások hierarchikus struktúrákat használnak, mint például a JSON vagy a Dto-k a szülő-gyermek társítások ábrázolására, a legtöbb alkalmazásnak a JDBC ResultSet átalakításához más formátumra volt szüksége az adatelérési rétegben, amint azt a következő példa szemlélteti:
int maxResults = 10;List<Post> posts = new ArrayList<>();try (PreparedStatement preparedStatement = connection.prepareStatement(""" SELECT p.id AS id, p.title AS title FROM post p ORDER BY p.id LIMIT ? """)) { preparedStatement.setInt(1, maxResults); try (ResultSet resultSet = preparedStatement.executeQuery()) { while (resultSet.next()) { int index = 0; posts.add( new Post() .setId(resultSet.getLong(++index)) .setTitle(resultSet.getString(++index)) ); } }} catch (SQLException e) { fail(e.getMessage());}
ismét ez a legszebb módja annak, hogy ezt írhassuk a JDBC – vel, mivel szövegblokkokat, try-with-resources-t és egy Fluent stílusú API-t használunk a Post objektumok felépítéséhez.
ennek ellenére a JDBC API még mindig nagyon bőbeszédű, és ami még fontosabb, hiányzik sok olyan funkció, amelyek szükségesek egy modern adatelérési réteg megvalósításához, mint például:
- egy módja annak, hogy hozza objektumok közvetlenül a lekérdezés eredményhalmaz. Amint azt a fenti példában láttuk, meg kell ismételnünk a
ReusltSetértéket, és ki kell bontanunk az oszlopértékeket aPostobjektum tulajdonságainak beállításához. - a kötegelt utasítások átlátható módja anélkül, hogy újra kellene írni az adathozzáférési kódot, amikor az alapértelmezett nem kötegelési módról a kötegelésre vált.
- optimista zárolás támogatása
- a lapozás API, amely elrejti az alapul szolgáló adatbázis-specifikus Top-N és Next-n lekérdezés szintaxisát
miért és mikor jött létre a Hibernate
1999-ben a Sun kiadta a J2EE-t (Java Enterprise Edition), amely alternatívát kínált a JDBC-hez, az Entity Beans nevet.
mivel azonban az Entity Beans közismerten lassú, túlbonyolított és nehézkes volt a használata, 2001-ben Gavin King úgy döntött, hogy létrehoz egy ORM keretrendszert, amely képes leképezni az adatbázis táblákat Pojo-kra (sima régi Java objektumok), és így született meg a Hibernate.
mivel könnyebb volt, mint az Entity Beans és kevésbé bőbeszédű, mint a JDBC, a Hibernate egyre népszerűbb lett, és hamarosan a legnépszerűbb Java perzisztencia keretrendszer lett, megnyerve a JDO, iBatis, Oracle TopLink és Apache Cayenne.
miért és mikor jött létre a JPA?
a Hibernate projekt sikeréből tanulva a Java EE platform úgy döntött, hogy szabványosítja a Hibernate és az Oracle TopLink módját, és így született meg a JPA (Java Persistence API).
a JPA csak egy specifikáció, és önmagában nem használható, csak olyan interfészkészletet biztosít, amely meghatározza a szabványos perzisztencia API-t, amelyet egy JPA-szolgáltató hajt végre, mint például a Hibernate, az EclipseLink vagy az OpenJPA.
JPA használatakor meg kell határozni az adatbázis tábla és a hozzá tartozó Java entitás objektum közötti leképezést:
@Entity@Table(name = "post")public class Post { @Id private Long id; private String title; public Long getId() { return id; } public Post setId(Long id) { this.id = id; return this; } public String getTitle() { return title; } public Post setTitle(String title) { this.title = title; return this; }}
ezután átírhatjuk az előző példát, amely 100 post rekordot mentett így néz ki:
for (long i = 1; i <= postCount; i++) { entityManager.persist( new Post() .setId(i) .setTitle( String.format( "High-Performance Java Persistence, review no. %1$d", i ) ) );}
a JDBC kötegelt Beszúrások engedélyezéséhez csak egyetlen konfigurációs tulajdonságot kell megadnunk:
<property name="hibernate.jdbc.batch_size" value="50"/>
miután ezt a tulajdonságot megadta, a Hibernate automatikusan átválthat a nem kötegelésről a kötegelésre anélkül, hogy bármilyen adathozzáférési kódot meg kellene változtatni.
az első 10 post sor letöltéséhez a következő JPQL lekérdezést hajthatjuk végre:
int maxResults = 10;List<Post> posts = entityManager.createQuery(""" select p from post p order by p.id """, Post.class).setMaxResults(maxResults).getResultList();
ha összehasonlítja ezt a JDBC verzióval, látni fogja, hogy a JPA sokkal könnyebben használható.
a JPA és a Hibernate
JPA használatának előnyei és hátrányai általában, és különösen a Hibernate használata számos előnyt kínál.
- entitásokat vagy Dto-kat lehet letölteni. Akkor is letölteni hierarchikus szülő-gyermek DTO vetítés.
- engedélyezheti a JDBC adagolását az adathozzáférési kód megváltoztatása nélkül.
- támogatja az optimista zárolást.
- pesszimista zárolási absztrakcióval rendelkezik, amely független az alapul szolgáló adatbázis-specifikus szintaxistól, így megszerezheti az olvasási és írási zárolást vagy akár az átugrási zárolást.
- van egy adatbázis-független lapozás API.
-
Listértéket adhat meg egy in query záradékhoz, amint azt a cikk ismerteti. - használhat egy erősen következetes gyorsítótárazási megoldást, amely lehetővé teszi az elsődleges csomópont tehermentesítését, amely rea-write tranzakciókhoz csak függőlegesen hívható meg.
- beépített támogatása van az ellenőrzési naplózásnak a Hibernate Envers segítségével.
- van beépített támogatása multitenancy.
- a Hibernate hbm2ddl eszköz segítségével létrehozhat egy kezdeti sémaszkriptet az entitásleképezésekből, amelyet egy automatikus sémamigrációs eszközhöz, például a Flyway-hez adhat meg.
- nem csak azt, hogy szabadon végrehajthat bármilyen natív SQL lekérdezést, hanem az SqlResultSetMapping segítségével átalakíthatja a JDBC
ResultSet– et JPA entitásokká vagy Dto-kká.
a JPA és a Hibernate használatának hátrányai a következők:
- bár a JPA használatának megkezdése nagyon egyszerű, a szakértővé válás jelentős időbefektetést igényel, mert a kézikönyv elolvasása mellett még meg kell tanulnia az adatbázis-rendszerek működését, az SQL szabványt, valamint a projekt relációs adatbázisa által használt speciális SQL ízt.
- van néhány kevésbé intuitív viselkedés, amely meglepheti a kezdőket, például az öblítési művelet sorrendje.
- a Criteria API meglehetősen bőbeszédű, ezért egy olyan eszközt kell használnia, mint a Codota, hogy könnyebben írjon dinamikus lekérdezéseket.
az általános közösségi és népszerű integrációk
a JPA és a Hibernate rendkívül népszerűek. A Snyk 2018-as Java ökoszisztéma-jelentése szerint a Hibernate-t minden olyan Java fejlesztő 54% – a használja, amely kapcsolatba lép egy relációs adatbázissal.
ezt az eredményt a Google Trends támogatja. Például, ha összehasonlítjuk a JPA Google trendjeit a fő versenytársaival (például a MyBatis, a QueryDSL és a jOOQ), láthatjuk, hogy a JPA sokszor népszerűbb, és nem mutatja a domináns piaci részesedésének elvesztésének jeleit.

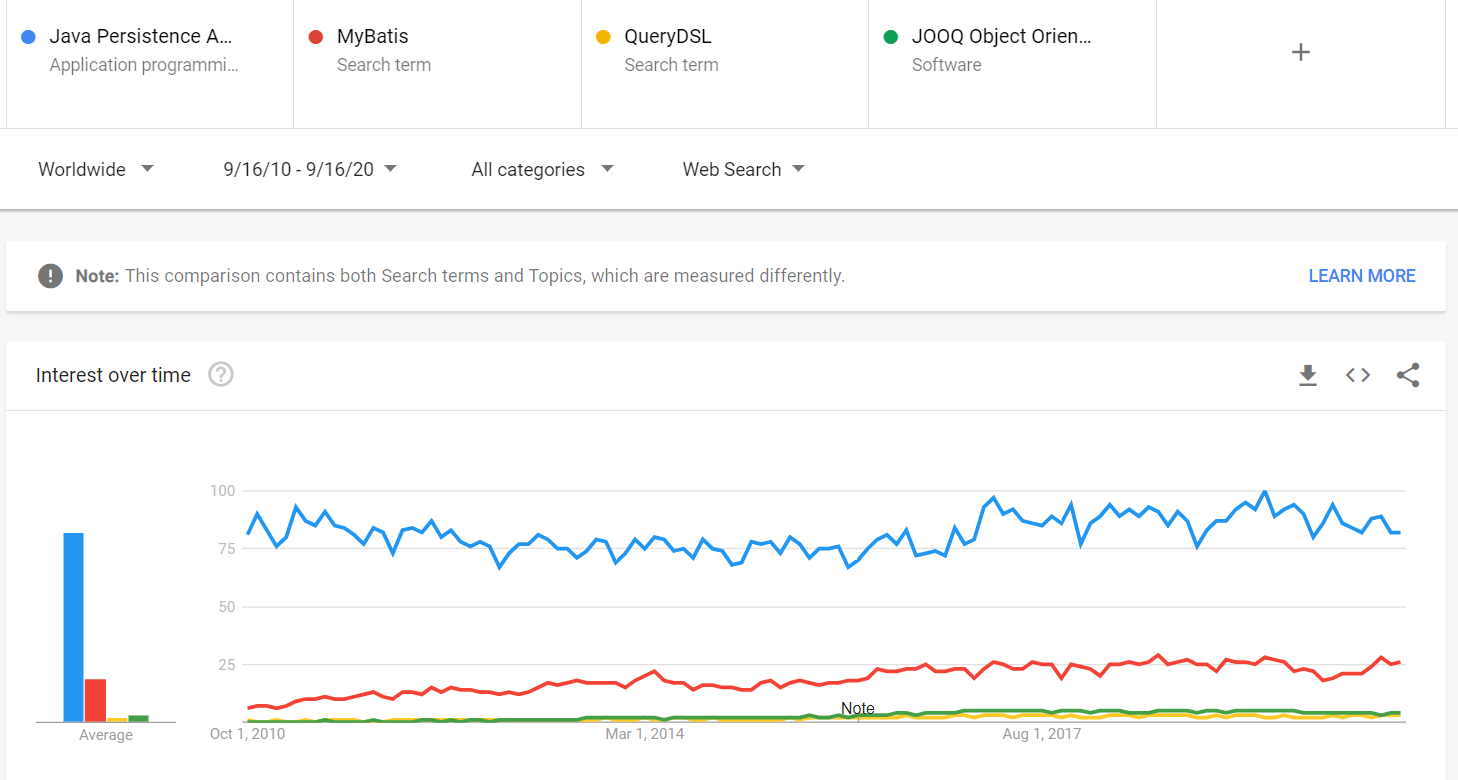
az ilyen népszerűségnek számos előnye van, például:
- a Spring Data JPA integráció varázslatként működik. Valójában az egyik legnagyobb oka annak, hogy a JPA és a Hibernate annyira népszerű, mert a Spring Boot a Spring Data JPA-t használja, amely viszont a Hibernate-t használja a színfalak mögött.
- ha bármilyen problémája van, jó esély van arra, hogy ezek a 30k Hibernate-hez kapcsolódó StackOverflow válaszok és a 16k JPA-hoz kapcsolódó StackOverflow válaszok megoldást nyújtanak Önnek.
- 73k hibernált oktatóanyagok állnak rendelkezésre. Csak a webhelyem kínál több mint 250 JPA és Hibernate oktatóanyagot, amelyek megtanítják, hogyan lehet a legtöbbet kihozni a JPA-ból és a hibernált állapotból.
- számos videó tanfolyam is használható, mint például a nagy teljesítményű Java Perzisztencia videó tanfolyamom.
- több mint 300 könyv található a Hibernate-ről az Amazonon, amelyek közül az egyik a nagy teljesítményű Java Perzisztencia könyvem is.
JPA alternatívák
a Java ökoszisztéma egyik legnagyobb dolga a kiváló minőségű keretrendszerek bősége. Ha a JPA és a Hibernate nem felel meg a használati esetnek, akkor az alábbi keretrendszerek bármelyikét használhatja:
- MyBatis, amely egy nagyon könnyű SQL query mapper keretrendszer.
- QueryDSL, amely lehetővé teszi az SQL, JPA, Lucene és MongoDB lekérdezések dinamikus felépítését.
- jOOQ, amely Java metamodellt biztosít az alapul szolgáló táblákhoz, tárolt eljárásokhoz és funkciókhoz, és lehetővé teszi az SQL lekérdezés dinamikus felépítését egy nagyon intuitív DSL használatával és típusbiztos módon.
tehát használja azt, ami a legjobban megfelel Önnek.
Online workshopok
ha tetszett ez a cikk, fogadok, hogy szeretni fogja a közelgő 4 napos x 4 órás nagy teljesítményű Java Perzisztencia online műhelyemet

következtetés
ebben a cikkben láttuk, miért jött létre a JPA, és mikor kell használni. Bár a JPA számos előnnyel jár, számos más kiváló minőségű alternatíva is használható, ha a JPA és a Hibernate nem működik a legjobban az aktuális alkalmazási követelményeknek.
és néha, amint azt a nagy teljesítményű Java Perzisztencia könyvem ingyenes mintájában kifejtettem, nem is kell választanod a JPA vagy más keretrendszerek között. Könnyedén kombinálhatja a JPA-t egy olyan keretrendszerrel, mint a jOOQ, hogy mindkét világból a legjobbat hozza ki.



