Iniziamo osservando la regressione lineare/ridge a forma doppia, prima di mostrare come “kernelizzarla”. Nello spiegare quest’ultimo, vedremo quali sono i kernel e qual è il “trucco del kernel”.
Regressione della cresta a doppia forma
La regressione lineare è tipicamente data in forma primaria come combinazione lineare di colonne (caratteristiche). Tuttavia, esiste una seconda forma duale in cui è una combinazione lineare del prodotto interno di un nuovo dato (su cui stiamo eseguendo l’inferenza) con ciascuno dei dati di allenamento.
Consideriamo il caso della regressione di cresta (regressione lineare regolarizzata L2), ricordando che la regressione lineare di base corrisponde al caso in cui \(\lambda = 0\). Quindi le formule per la regressione della cresta, dove \(X\) e \(Y\) si riferiscono ai dati di allenamento \(n \volte m\) e \(x^ \ prime, y ^ \ prime\) un nuovo caso da stimare, sono:
\ \ \ \
In questo caso,il prodotto interno/punto è \(\langle X_i, x^\prime \rangle\), quindi \(\langle X_i,x^\prime \rangle = X^T_i x^\prime = \sum_j^m X_{i, j} x^\prime_j\).
La forma duale mostra che la regressione lineare/cresta può anche essere intesa come una stima di una somma ponderata del prodotto interno di un nuovo caso con ciascuno dei casi di allenamento.
Significa che possiamo fare regressione lineare anche quando ci sono più colonne che righe, anche se l’importanza di questo può essere sopravvalutata poiché (i) possiamo farlo comunque tramite l’uso della regolarizzazione L2 poiché questo rende sempre invertibile la matrice \(X^TX\); e (ii) la matrice \(XX^T\) può spesso richiedere comunque la regolarizzazione L2 per garantire la stabilità numerica Ci consente anche di visualizzare la regressione lineare come molto più di un processo di apprendimento sequenziale, in cui ogni dato aggiuntivo nei dati di allenamento porta qualcosa di nuovo.
Soprattutto per i nostri scopi, tuttavia, la forma duale ha la caratteristica interessante: i vettori di caratteristiche si verificano nelle equazioni solo all’interno di prodotti interni. Questo è vero anche nella definizione di \ (\alpha\), poiché \(XX^T\) produce la matrice corrispondente ai prodotti interni di ogni coppia di vettori di funzionalità nei dati di allenamento. Vedremo l’importanza di questo mentre procediamo.
A parte: gli studenti interessati possono vedere come è stata derivata la forma duale nel documento di derivazione della forma duale disponibile nella sezione download alla fine di questo articolo.
Non Lineare Dual Ridge Regression
Possiamo trasformare il nostro duplice forma di regressione di ridge in un non-modello lineare con il metodo standard di uso di un non-lineare caratteristica trasformazioni di \(\phi\):
\ \
le Funzioni del Kernel
Un kernel in funzione di \(K): \mathcal X \times \mathcal X \to \mathbb{R}\), è una funzione simmetrica – \(K(x_1,x_2)=K(x_2,x_1)\) e definita positiva (vedi oltre per una definizione formale). La definizione positiva è usata nella matematica che giustifica l’uso dei kernel. Ma senza una conoscenza matematica significativa, la definizione non è intuitivamente illuminante. Quindi, piuttosto che tentare di capire i kernel dalla definizione di definiteness positivo, li introdurremo con una serie di esempi.
Prima di fare ciò, notiamo che sebbene i kernel siano funzioni a due argomenti, è comune pensare che si trovino al loro primo argomento e che siano una funzione del loro secondo. In base a questa interpretazione vedrai notazione come \(K_x (y)\), che è equivalente a \(K(x, y)\). In particolare, penseremo spesso che i kernel siano funzioni di argomento singolo “situate” nei punti dati (vettori di funzionalità) nei nostri dati di allenamento. A volte si legge di noi’ cadere ‘ kernel su punti di dati. Quindi se abbiamo un vettore di funzionalità \(x_i\), lasceremmo cadere un kernel su di esso,portando alla funzione \(K_{x_i}(x)\) situata in \(x_i\) ed equivalente a \(K(x_i, x)\) .
Notiamo anche che i kernel sono spesso specificati come membri di famiglie parametriche. Esempi di tali famiglie di kernel includono:
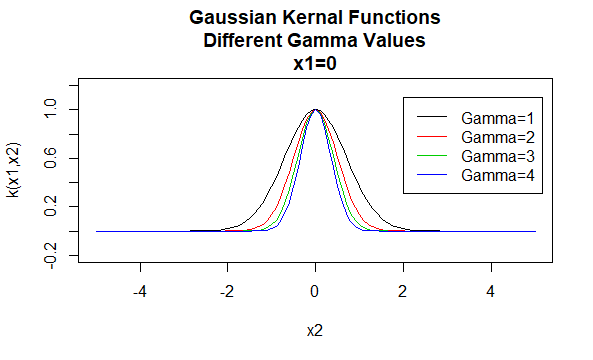
Kernel gaussiani
I kernel gaussiani sono un esempio di kernel a funzione di base radiale e sono talvolta chiamati kernel a base radiale. Il valore di un kernel funzione base radiale dipende solo dalla distanza tra i vettori argomento, piuttosto che la loro posizione. Tali kernel sono anche definiti stazionari.
Parametri: \ (\gamma\)
Forma dell’equazione: \(K (X_1,X_2)=e^{- \gamma \ / X_1-X_2 \|^2}\)
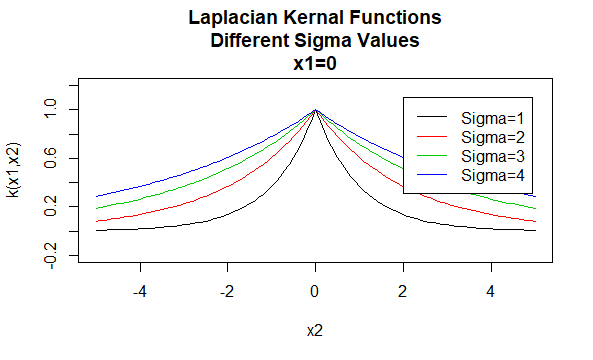
I kernel laplaciani
I kernel laplaciani sono anche funzioni di base radiale.
Parametri: \ (\sigma\)
Forma di equazione: \(K (X_1,X_2)=e^{-\frac{\| X_1 – X_2 \|}{\sigma}}\)
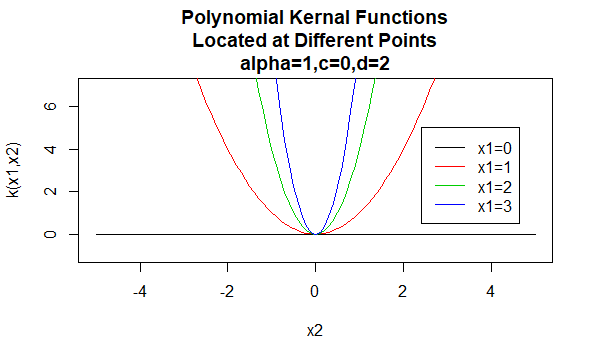
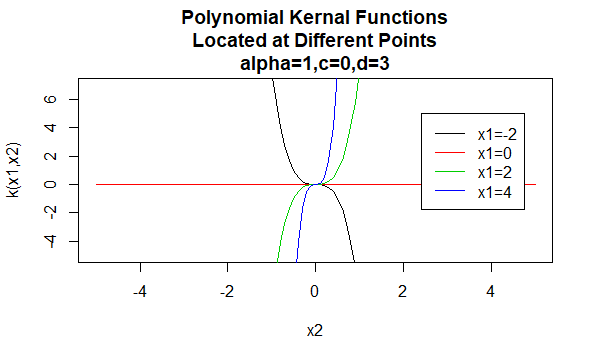
I kernel polinomiali
I kernel polinomiali sono un esempio di kernel non stazionari. Quindi questi kernel assegneranno valori diversi a coppie di punti che condividono la stessa distanza, in base ai loro valori. I valori dei parametri devono essere non negativi per garantire che questi kernel siano definiti positivi.
Parametri: \(\alpha , c , d\)
Forma dell’equazione: \(K(X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
Specificando valori particolari per i parametri di una famiglia di kernel si ottiene una funzione del kernel. Di seguito sono riportati esempi di funzioni dei kernel delle famiglie precedenti con particolari valori di parametro situati in punti diversi (cioè il grafico tracciato è una funzione del secondo argomento, con il primo argomento impostato su un valore specifico).
A parte: Gli studenti interessati possono vedere la definizione di definiteness positivo per kernel nel documento Kernel e Definiteness positivo disponibile nella sezione download alla fine di questo articolo.
Il trucco del kernel
L’importanza delle funzioni del kernel deriva da una proprietà molto speciale: Ogni positivo-precisa kernel, \(K\) è legato a uno spazio matematico, \(\mathcal{H}_K\), (conosciuto come il reproducing kernel spazio di Hilbert (RKHS) del kernel) in modo che l’applicazione di \(K\) di due vettori di feature, \(X_1,X_2\) è equivalente alla proiezione di questi vettori di feature in \(\mathcal{H}_K\) da parte di una funzione di proiezione, \(\phi\) e prendendo il loro prodotto interno c’:
\
Il RKHSs associati con i kernel sono in genere di dimensioni elevate. Per alcuni kernel, come i kernel della famiglia gaussiana, sono dimensionali infiniti.
di cui sopra è la base per il famoso ‘kernel trucco’: Se la funzionalità di input sono coinvolti nell’equazione di un modello statistico solo in forma di interni-prodotti, siamo in grado di sostituire l’interno-prodotti in equazione con chiamate alla funzione kernel e il risultato è come se ci fosse proiettata la funzionalità di input in uno spazio di dimensione superiore (cioè eseguita una funzione di trasformazione che conduce a un grande numero di variabili latenti) e preso il loro interiore-prodotto non. Ma non abbiamo mai bisogno di eseguire la proiezione reale.
Nella terminologia dell’apprendimento automatico, gli RKH associati al kernel sono noti come spazio di feature, in contrapposizione allo spazio di input. Tramite il trucco del kernel proiettiamo implicitamente le funzionalità di input in questo spazio di funzionalità e prendiamo il loro prodotto interno lì.
Regressione del kernel
Questo porta alla tecnica nota come regressione del kernel. È semplicemente un’applicazione del trucco del kernel alla doppia forma di regressione della cresta. Per facilità introduct l’idea del Kernel, o Gram, matrix, \(K\), tale che \(K_{i,j}=k (X_i,X_j)\). Quindi possiamo scrivere le equazioni per la regressione del kernel come:
\ \
Dove \(k\) è una funzione del kernel definita positiva.
Il Representer Teorema
si Consideri il problema di ottimizzazione cerchiamo di risolvere durante l’esecuzione di L2 di regolarizzazione per un modello di una qualche forma, \(f\):
\
Quando si esegue il kernel di regressione con il kernel di \(k\), si tratta di un importante risultato di regolarizzazione teoria che il miniatore di equazione di cui sopra sarà della forma:
\
Con \(\alpha\), calcolato come sopra descritto.
Questo è il teorema di Representer giustamente lionizzato. In parole, si dice che il minimizzatore del problema di ottimizzazione per la regressione lineare nello spazio di funzionalità implicito ottenuto da un particolare kernel (e quindi il minimizzatore del problema di regressione del kernel non lineare) sarà dato da una somma ponderata di kernel ‘situati’ in ogni vettore di funzionalità.
C’è molto altro da dire su questo argomento. Possiamo anche capire quale funzione Verde (di cui i kernel sono un sottoinsieme) ridurrà al minimo particolari specifiche di regolarizzazione, come la regolarizzazione L2 ma anche qualsiasi penalità basata su un operatore differenziale lineare. Questa relazione tra i kernel e le soluzioni ottimali ai problemi di regolarizzazione di Tikhonov è una ragione principale per l’importanza dei metodi del kernel nell’apprendimento automatico. Ma la matematica qui è al di là di questo corso, e gli studenti avanzati interessati si riferiscono al capitolo sette delle reti neurali e delle macchine di apprendimento di Haykin.
Questo ci dà una giustificazione matematica per usare la regressione del kernel nei casi in cui è possibile farlo. In realtà elaborare il kernel ottimale da utilizzare in genere non è possibile – richiede la conoscenza dell’operatore differenziale lineare ottimale da utilizzare per la penalità di regolarizzazione. Le funzioni su cui dovremmo proiettare per ottimizzare particolari penalità di regolarizzazione sono state calcolate e sappiamo, ad esempio, che il kernel spline a piastra sottile è ottimale per la regolarizzazione L2. Sul lato negativo, dal momento che abbiamo bisogno di calcolare la matrice di Gram, la regressione del kernel non scala bene – per grandi set di dati che si rivolgono a reti neurali è un’idea migliore.