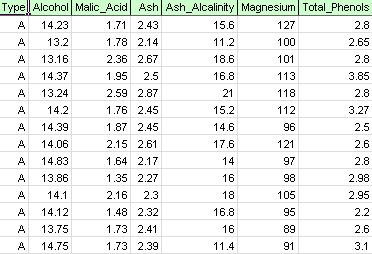
Sulla barra multifunzione XLMiner, dalla scheda Applicazione del modello, selezionare Help-Examples, quindi Forecasting/Data Mining Examples e aprire il file di esempio Wine.xlsx. Come mostrato nella figura seguente, ogni riga di questo set di dati di esempio rappresenta un campione di vino prelevato da una delle tre cantine (A, B o C). In questo esempio, la variabile di tipo che rappresenta la cantina viene ignorata e il clustering viene eseguito semplicemente sulla base delle proprietà dei campioni di vino (le variabili rimanenti).
Selezionare una cella all’interno del set di dati, quindi sulla barra multifunzione XLMiner, dalla scheda Analisi dati, selezionare XLMiner – Cluster – k-Means Clustering per aprire la finestra di dialogo k-Means Clustering Passo 1 di 3.
Dall’elenco Variabili, selezionare tutte le variabili tranne il tipo, quindi fare clic sul pulsante > per spostare le variabili selezionate nell’elenco Variabili selezionate.
Fare clic su Avanti per passare alla Fase 2 di 3 dialogo.
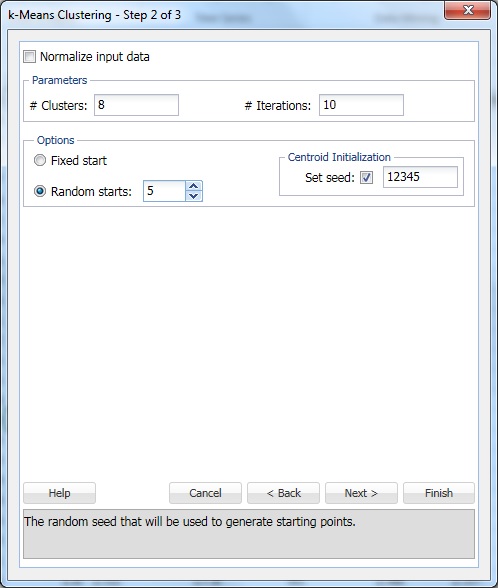
A # Cluster, immettere 8. Questo è il parametro k nell’algoritmo di clustering k-means. Il numero di cluster dovrebbe essere almeno 1 e al massimo il numero di osservazioni -1 nell’intervallo di dati. Impostare k su diversi valori diversi e valutare l’output da ciascuno.
Lascia # Iterazioni all’impostazione predefinita di 10. Il valore di questa opzione determina quante volte il programma inizierà con una partizione iniziale e completerà l’algoritmo di clustering. La configurazione dei cluster (e la separazione dei dati) può differire da una partizione iniziale all’altra. Il programma passerà attraverso il numero specificato di iterazioni, e selezionare la configurazione del cluster che riduce al minimo la misura della distanza.
Imposta Inizio casuale su 5. Quando questa opzione è selezionata, l’algoritmo inizia a costruire il modello da qualsiasi punto casuale. XLMiner genera cinque set di cluster e genera l’output in base al cluster migliore.
Set seed è selezionato per impostazione predefinita. Questa opzione inizializza il generatore di numeri casuali utilizzato per calcolare i centroidi cluster iniziali. L’impostazione del seme del numero casuale su un valore diverso da zero (default 12345) garantisce che la stessa sequenza di numeri casuali venga utilizzata ogni volta che vengono calcolati i centroidi del cluster iniziale. Quando il seme è zero, il generatore di numeri casuali viene inizializzato dall’orologio di sistema, quindi la sequenza di numeri casuali è diversa ogni volta che i centroidi vengono inizializzati. Impostare il seme per visualizzare le esecuzioni successive del metodo di clustering come comparabili.
Selezionare l’opzione Normalizza dati di input per normalizzare i dati. In questo esempio, i dati non verranno normalizzati. Selezionare Avanti per aprire la finestra di dialogo Passo 3 di 3.
Selezionare Mostra riepilogo dati (predefinito) e Mostra distanze da ogni centro cluster (predefinito), quindi fare clic su Fine.
Il metodo k-Means Clustering inizia con k cluster iniziali come specificato. Ad ogni iterazione, i record vengono assegnati al cluster con il centroide più vicino, o centro. Dopo ogni iterazione, viene calcolata la distanza da ciascun record al centro del cluster. Questi due passaggi vengono ripetuti (l’assegnazione del record e il calcolo della distanza) fino a quando la ridistribuzione di un record produce un valore di distanza aumentato.
Quando viene specificato un avvio casuale, l’algoritmo genera i centri del cluster k in modo casuale e si adatta ai punti dati in tali cluster. Questo processo viene ripetuto per tutti gli avvii casuali specificati. L’output si basa sui cluster che presentano la migliore vestibilità.
Il foglio di lavoro KM_Output1 viene inserito immediatamente a destra del foglio di lavoro dei dati. Nella sezione superiore del foglio di lavoro di output, vengono elencate le opzioni selezionate.
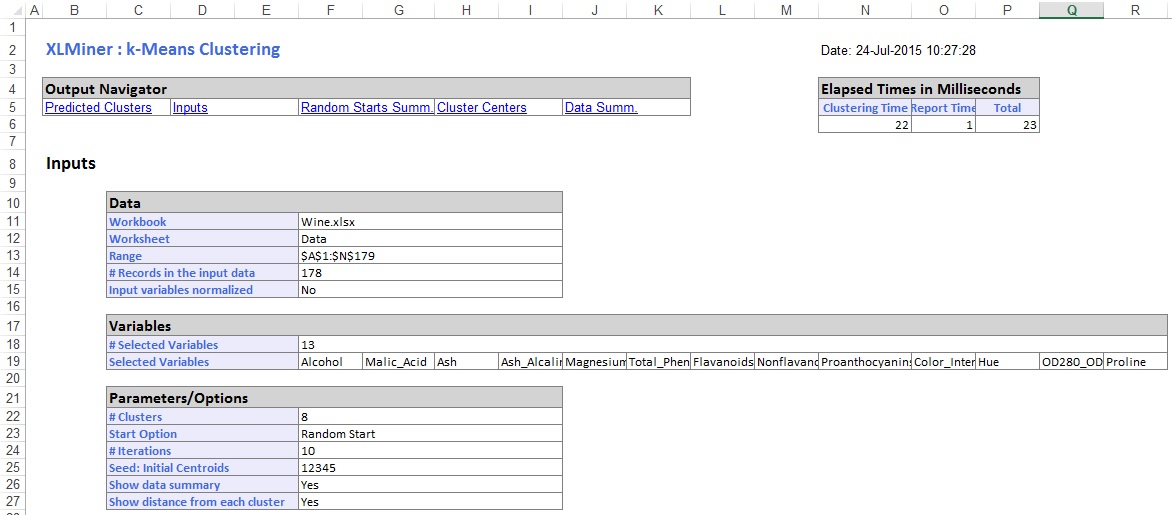
Nella sezione centrale del foglio di lavoro di output, XLMiner ha calcolato la somma delle distanze quadrate e determinato l’inizio con la somma più bassa della distanza quadrata come inizio migliore (#5). Dopo aver determinato il miglior inizio, XLMiner genera l’output rimanente utilizzando il miglior inizio come punto di partenza.
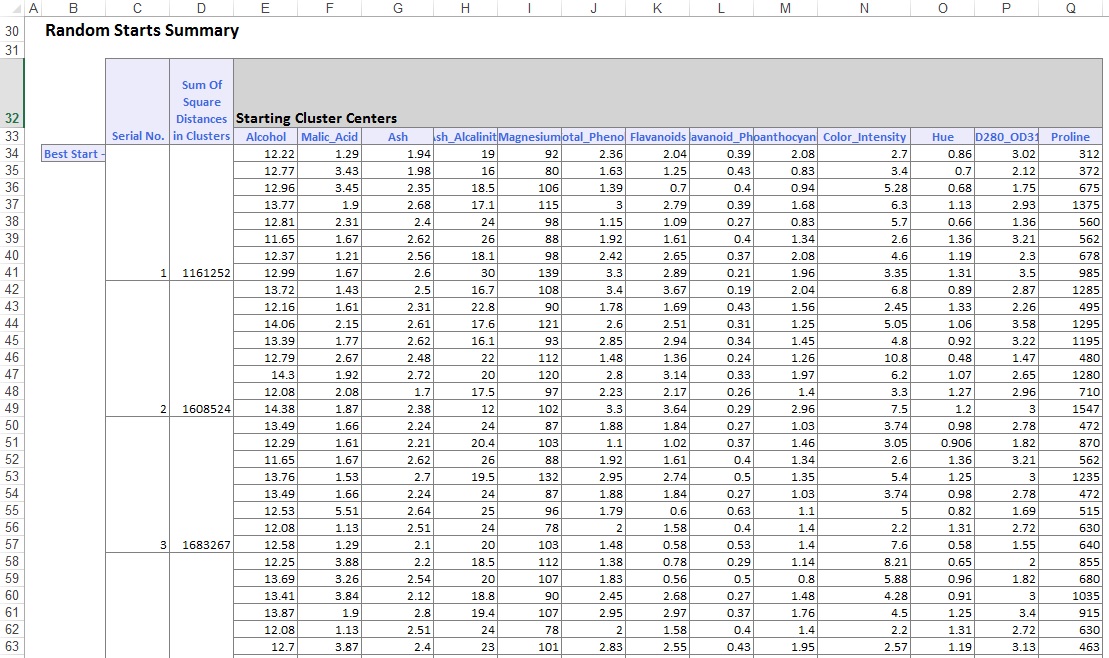
Nella parte inferiore del foglio di lavoro di output, XLMiner ha elencato i Centri Cluster (mostrati di seguito). La casella superiore mostra i valori delle variabili nei Centri del Cluster. Il cluster 8 ha il più alto contenuto medio di alcol, Total_Phenols, flavanoidi, proantociani, Color_Intensity, Hue e Prolina. Confronta questo cluster con il cluster 2, che ha la più alta Ash_Alcalinity media e Nonflavanoid_Phenols.
La casella inferiore mostra la distanza tra i Centri del Cluster. Dai valori in questa tabella, si determina che il Cluster 3 è molto diverso dal Cluster 8 a causa del valore di distanza elevata di 1,176.59 e il Cluster 7 è vicino al Cluster 3 con un valore di distanza bassa di 89.73.
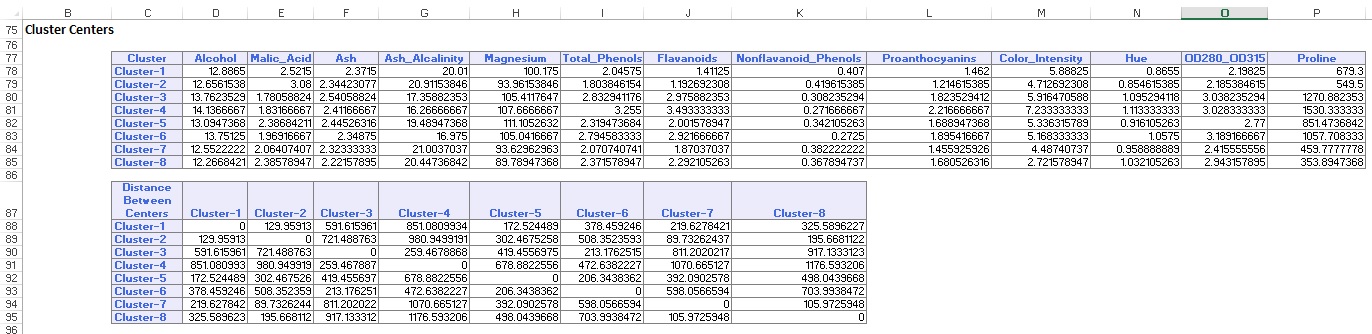
Il riepilogo dei dati (di seguito) visualizza il numero di record (osservazioni) inclusi in ciascun cluster e la distanza media tra i membri del cluster e il centro di ciascun cluster. Il cluster 6 ha la distanza media più alta di 42,79 e include 24 record. Confronta questo cluster con il cluster 2, che ha la distanza media minima di 29,66 e include 26 membri.
Fare clic sul foglio di lavoro KM_Clusters1. Questo foglio di lavoro visualizza il cluster a cui è assegnato ogni record e la distanza da ciascuno dei cluster. Per il primo record, la distanza dal Cluster 6 è la distanza minima di 23.205, quindi questo primo record viene assegnato al Cluster 6.