Immagina di avere uno strumento in grado di rilevare automaticamente JPA e ibernare i problemi di prestazioni. Hypersistence Optimizer è quello strumento!
Introduzione
Se ti stai chiedendo perché e quando dovresti usare JPA o Hibernate, allora questo articolo ti fornirà una risposta a questa domanda molto comune. Poiché ho visto questa domanda molto spesso sul canale / r / java Reddit, ho deciso che vale la pena scrivere una risposta approfondita sui punti di forza e di debolezza di JPA e Hibernate.
Sebbene JPA sia stato uno standard da quando è stato rilasciato per la prima volta nel 2006, non è l’unico modo per implementare un livello di accesso ai dati utilizzando Java. Discuteremo i vantaggi e gli svantaggi dell’utilizzo di JPA o di altre alternative popolari.
Perché e quando è stato creato JDBC
Nel 1997, Java 1.1 ha introdotto l’API JDBC (Java Database Connectivity), che è stata molto rivoluzionaria per il suo tempo poiché offriva la possibilità di scrivere il livello di accesso ai dati una volta utilizzando un set di interfacce ed eseguirlo su qualsiasi database relazionale che implementa l’API JDBC senza dover modificare il codice dell’applicazione.
L’API JDBC offriva un’interfaccia Connection per controllare i limiti delle transazioni e creare semplici istruzioni SQL tramite l’API Statement o istruzioni preparate che consentono di associare i valori dei parametri tramite l’API PreparedStatement.
Quindi, supponendo che abbiamo una tabella di database post e vogliamo inserire 100 righe, ecco come potremmo raggiungere questo obiettivo con JDBC:
int postCount = 100;int batchSize = 50;try (PreparedStatement postStatement = connection.prepareStatement(""" INSERT INTO post ( id, title ) VALUES ( ?, ? ) """)) { for (int i = 1; i <= postCount; i++) { if (i % batchSize == 0) { postStatement.executeBatch(); } int index = 0; postStatement.setLong( ++index, i ); postStatement.setString( ++index, String.format( "High-Performance Java Persistence, review no. %1$d", i ) ); postStatement.addBatch(); } postStatement.executeBatch();} catch (SQLException e) { fail(e.getMessage());}
Mentre abbiamo approfittato dei blocchi di testo multilinea e dei blocchi try-with-resources per eliminare la chiamata PreparedStatement close, l’implementazione è ancora molto dettagliata. Si noti che i parametri di bind iniziano da 1, non da 0 come si potrebbe essere abituati da altre API ben note.
Per recuperare le prime 10 righe, potremmo aver bisogno di eseguire una query SQL tramite PreparedStatement, che restituirà un ResultSet che rappresenta il risultato della query basata su tabella. Tuttavia, poiché l’utilizzo di applicazioni di strutture gerarchiche, come JSON o DTOs per rappresentare padre-figlio associazioni, la maggior parte delle applicazioni necessarie per trasformare l’JDBC ResultSet un formato diverso il livello di accesso ai dati, come illustrato dal seguente esempio:
int maxResults = 10;List<Post> posts = new ArrayList<>();try (PreparedStatement preparedStatement = connection.prepareStatement(""" SELECT p.id AS id, p.title AS title FROM post p ORDER BY p.id LIMIT ? """)) { preparedStatement.setInt(1, maxResults); try (ResultSet resultSet = preparedStatement.executeQuery()) { while (resultSet.next()) { int index = 0; posts.add( new Post() .setId(resultSet.getLong(++index)) .setTitle(resultSet.getString(++index)) ); } }} catch (SQLException e) { fail(e.getMessage());}
di Nuovo, questo è il modo più bello potremmo scrivere questo con JDBC come stiamo usando Blocchi di Testo, provare-con-le risorse, e un Fluente stile API per costruire il Post oggetti.
Tuttavia, l’API JDBC è ancora molto dettagliata e, cosa più importante, manca di molte funzionalità richieste quando si implementa un moderno livello di accesso ai dati, come:
- Un modo per recuperare gli oggetti direttamente dal set di risultati della query. Come abbiamo visto nell’esempio sopra, dobbiamo iterare
ReusltSeted estrarre i valori della colonna per impostare le proprietà dell’oggettoPost. - Un modo trasparente per istruzioni batch senza dover riscrivere il codice di accesso ai dati quando si passa dalla modalità di default non-batching all’utilizzo di batch.
- supporto per optimistic locking
- Un’API di impaginazione che nasconde la sintassi di query Top-N e Next-N specifica del database sottostante
Perché e quando è stato creato Hibernate
Nel 1999, Sun ha rilasciato J2EE (Java Enterprise Edition), che offriva un’alternativa a JDBC, chiamata Entity Bean.
Tuttavia, poiché i bean di entità erano notoriamente lenti, complicati e ingombranti da usare, nel 2001, Gavin King decise di creare un framework ORM in grado di mappare le tabelle del database a POJO (semplici vecchi oggetti Java), ed è così che è nato Hibernate.
Essendo più leggero di Entity Bean e meno prolisso di JDBC, Hibernate è diventato sempre più popolare e presto è diventato il framework di persistenza Java più popolare, conquistando JDO, iBatis, Oracle TopLink e Apache Cayenne.
Perché e quando è stata creata JPA?
Imparando dal successo del progetto Hibernate, la piattaforma Java EE ha deciso di standardizzare il modo in cui Hibernate e Oracle TopLink, ed è così che è nata JPA (Java Persistence API).
JPA è solo una specifica e non può essere utilizzata da sola, fornendo solo un insieme di interfacce che definiscono l’API di persistenza standard, implementata da un provider JPA, come Hibernate, EclipseLink o OpenJPA.
Quando si utilizza JPA, è necessario di definire il mapping tra una tabella di database e le sue associate Java entità oggetto:
@Entity@Table(name = "post")public class Post { @Id private Long id; private String title; public Long getId() { return id; } public Post setId(Long id) { this.id = id; return this; } public String getTitle() { return title; } public Post setTitle(String title) { this.title = title; return this; }}
in Seguito, è possibile riscrivere l’esempio precedente, che ha salvato 100 post record di simile a questo:
for (long i = 1; i <= postCount; i++) { entityManager.persist( new Post() .setId(i) .setTitle( String.format( "High-Performance Java Persistence, review no. %1$d", i ) ) );}
Per attivare JDBC batch inserti, dobbiamo solo fornire una singola proprietà di configurazione:
<property name="hibernate.jdbc.batch_size" value="50"/>
Una volta fornita questa proprietà, Hibernate può passare automaticamente dal non-batch al batch senza bisogno di alcuna modifica del codice di accesso ai dati.
E, per recuperare le prime 10 post righe, possiamo eseguire la seguente query JPQL:
int maxResults = 10;List<Post> posts = entityManager.createQuery(""" select p from post p order by p.id """, Post.class).setMaxResults(maxResults).getResultList();
Se si confronta questo con la versione JDBC, si vedrà che JPA è molto più facile da usare.
I vantaggi e gli svantaggi dell’utilizzo di JPA e Hibernate
JPA, in generale, e Hibernate, in particolare, offrono molti vantaggi.
- È possibile recuperare entità o DTO. È anche possibile recuperare la proiezione DTO padre-figlio gerarchica.
- È possibile abilitare il batch JDBC senza modificare il codice di accesso ai dati.
- Hai il supporto per il blocco ottimistico.
- Hai un’astrazione di blocco pessimistica indipendente dalla sintassi specifica del database sottostante in modo da poter acquisire un BLOCCO di LETTURA e SCRITTURA o anche un BLOCCO di SALTO.
- Hai un’API di impaginazione indipendente dal database.
- È possibile fornire un
Listdi valori a una clausola IN query, come spiegato in questo articolo. - È possibile utilizzare una soluzione di caching fortemente coerente che consente di scaricare il nodo primario, che, per le transazioni rea-write, può essere chiamato solo verticalmente.
- Hai il supporto integrato per la registrazione di controllo tramite Hibernate Envers.
- Hai il supporto integrato per il multitenancy.
- È possibile generare uno script di schema iniziale dai mapping delle entità utilizzando lo strumento Hibernate hbm2ddl, che è possibile fornire a uno strumento di migrazione automatica dello schema, come Flyway.
- Non solo hai la libertà di eseguire qualsiasi query SQL nativa, ma puoi utilizzare SqlResultSetMapping per trasformare JDBC
ResultSetin entità JPA o DTO.
Gli svantaggi dell’utilizzo di JPA e Hibernate sono i seguenti:
- Mentre iniziare con JPA è molto semplice, diventare un esperto richiede un investimento di tempo significativo perché, oltre a leggere il suo manuale, devi ancora imparare come funzionano i sistemi di database, lo standard SQL e lo specifico sapore SQL utilizzato dal database delle relazioni di progetto.
- Ci sono alcuni comportamenti meno intuitivi che potrebbero sorprendere i principianti, come l’ordine di operazione di flush.
- L’API dei criteri è piuttosto prolissa, quindi è necessario utilizzare uno strumento come Codota per scrivere query dinamiche più facilmente.
La comunità globale e le integrazioni popolari
JPA e Hibernate sono estremamente popolari. Secondo il 2018 Java ecosystem report di Snyk, Hibernate viene utilizzato da 54% di ogni sviluppatore Java che interagisce con un database relazionale.
Questo risultato può essere supportato da Google Trends. Ad esempio, se confrontiamo le tendenze di Google di JPA rispetto ai suoi principali concorrenti (ad esempio, MyBatis, QueryDSL e jOOQ), possiamo vedere che JPA è molte volte più popolare e non mostra segni di perdere la sua posizione dominante sul mercato.

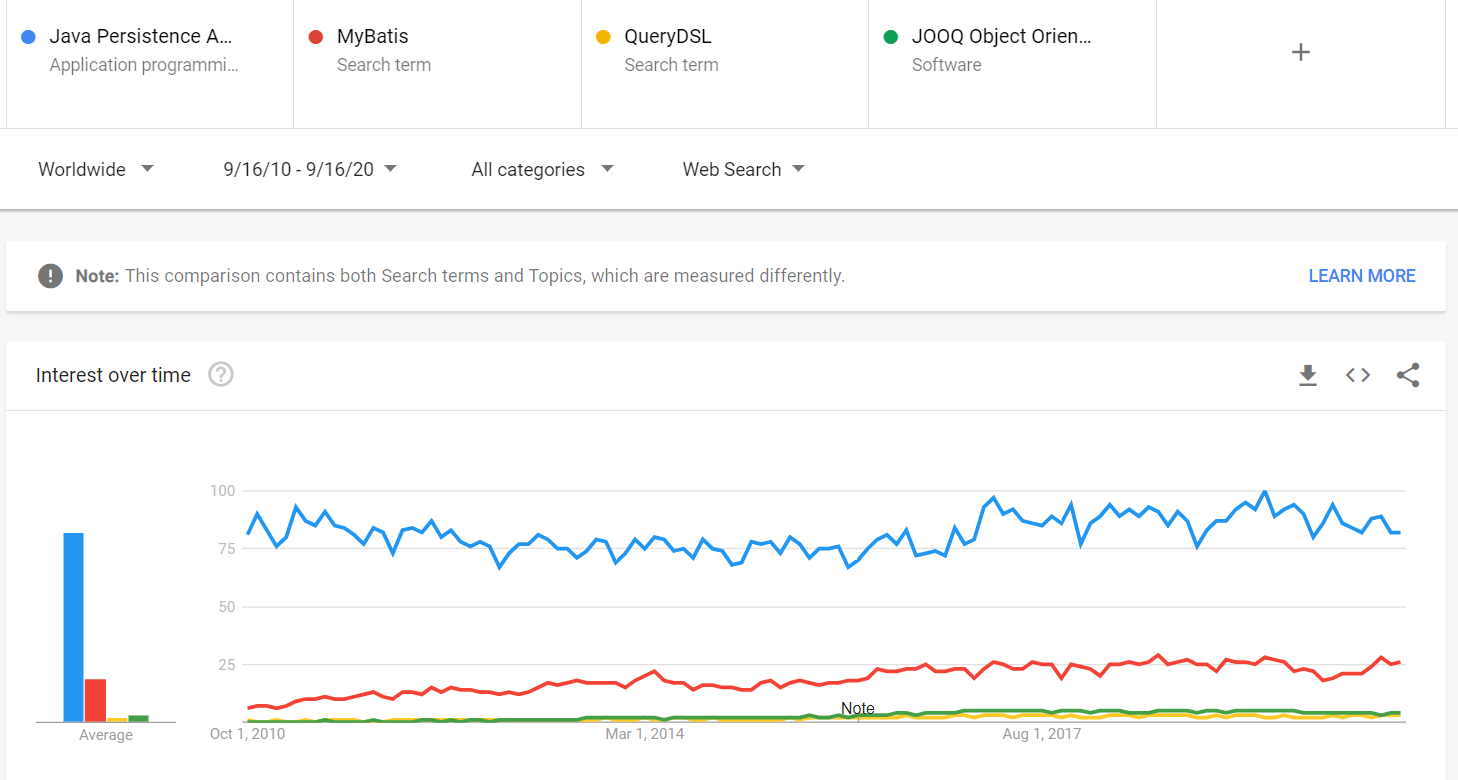
Essere così popolare porta molti vantaggi, come:
- L’integrazione JPA Spring Data funziona come un fascino. In effetti, uno dei motivi principali per cui JPA e Hibernate sono così popolari è perché Spring Boot utilizza Spring Data JPA, che a sua volta utilizza Hibernate dietro le quinte.
- Se hai qualche problema, c’è una buona probabilità che queste risposte StackOverflow relative a 30k Hibernate e le risposte StackOverflow relative a 16k JPA ti forniscano una soluzione.
- Ci sono 73k Hibernate tutorial disponibili. Solo il mio sito da solo offre oltre 250 tutorial JPA e Hibernate che ti insegnano come ottenere il massimo da JPA e Hibernate.
- Ci sono molti corsi video che puoi usare, come il mio corso video di persistenza Java ad alte prestazioni.
- Ci sono oltre 300 libri su Hibernate su Amazon, uno dei quali è anche il mio libro di persistenza Java ad alte prestazioni.
Alternative JPA
Una delle cose più grandi dell’ecosistema Java è l’abbondanza di framework di alta qualità. Se JPA e Hibernate non sono adatti al tuo caso d’uso, puoi utilizzare uno dei seguenti framework:
- MyBatis, che è un framework SQL query mapper molto leggero.
- QueryDSL, che consente di creare query SQL, JPA, Lucene e MongoDB in modo dinamico.
- jOOQ, che fornisce un metamodello Java per le tabelle sottostanti, le stored procedure e le funzioni e consente di creare una query SQL in modo dinamico utilizzando un DSL molto intuitivo e in modo sicuro.
Quindi, usa quello che funziona meglio per te.
Workshop Online
Se ti è piaciuto questo articolo, scommetto che si sta andando ad amare il mio prossimo 4 giorni x 4 ore ad Alte Prestazioni Java Persistence Online Officina

Conclusione
In questo articolo, abbiamo visto perché JPA è stato creato e quando si deve usare. Mentre JPA porta molti vantaggi, hai molte altre alternative di alta qualità da utilizzare se JPA e Hibernate non funzionano meglio per le tue attuali esigenze applicative.
E, a volte, come ho spiegato in questo esempio gratuito del mio libro di persistenza Java ad alte prestazioni, non è nemmeno necessario scegliere tra JPA o altri framework. Puoi facilmente combinare JPA con un framework come jOOQ per ottenere il meglio da entrambi i mondi.



