定常性とは、時系列の統計的性質、すなわち平均、分散、共分散が時間の経過とともに変化しないことを意味します。 多くの統計モデルでは、効果的かつ正確な予測を行うために、系列が静止している必要があります。
時系列の定常性をチェックするために2つの統計的検定が使用されます–拡張されたDickey Fuller(「ADF」)検定とKwiatkowski-Phillips-Schmidt-Shin(「KPSS」)検定。 また、非定常時系列を定常時系列に変換する方法も使用するものとする。
この最初のセルは標準パッケージをインポートし、プロットをインラインで表示するように設定します。
:
%matplotlib inlineimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport statsmodels.api as sm
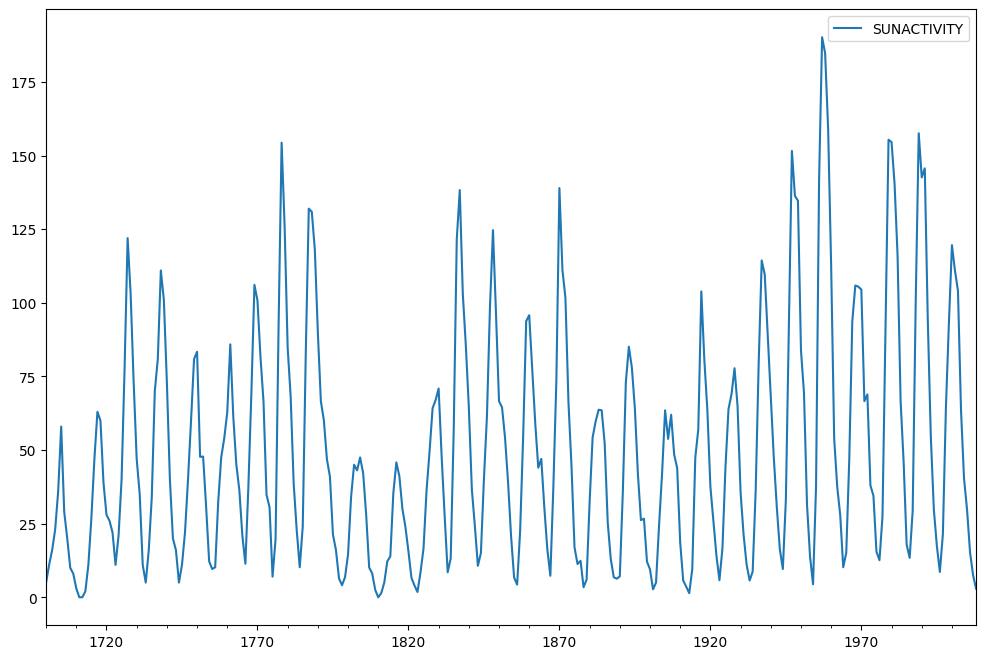
黒点データセットが使用されます。 国立地球物理学データセンターからの黒点に関する年間(1700年から2008年)のデータが含まれています。
:
sunspots = sm.datasets.sunspots.load_pandas().data
データに対していくつかの前処理が実行されます。 “年”列は、インデックスの作成に使用されます。
:
sunspots.index = pd.Index(sm.tsa.datetools.dates_from_range('1700', '2008'))del sunspots
これでデータがプロットされます。
:
sunspots.plot(figsize=(12,8))
:
<AxesSubplot:>
ADF検定†
ADF検定は、系列内の単位根の存在を判断するために使用されるため、系列が静止しているかどうかを理解するのに役立ちます。 この検定の帰無仮説と代替仮説は次のとおりです。
帰無仮説:系列には単位根があります。
代替仮説:系列には単位根がありません。
帰無仮説inが棄却されなかった場合、この検定は系列が非定常であるという証拠を提供する可能性があります。
時系列に対してADFテストを実行する関数が作成されます。
:
from statsmodels.tsa.stattools import adfullerdef adf_test(timeseries): print ('Results of Dickey-Fuller Test:') dftest = adfuller(timeseries, autolag='AIC') dfoutput = pd.Series(dftest, index=) for key,value in dftest.items(): dfoutput = value print (dfoutput)
KPSS検定∞
KPSSは、時系列の定常性をチェックするための別の検定です。 KPSS検定の帰無仮説と代替仮説は、ADF検定の帰無仮説とは反対です。
帰無仮説:プロセスはトレンド定常である。
別の仮説:系列は単位根を持つ(系列は静止していない)。
時系列に対してKPSSテストを実行する関数が作成されます。
:
from statsmodels.tsa.stattools import kpssdef kpss_test(timeseries): print ('Results of KPSS Test:') kpsstest = kpss(timeseries, regression='c', nlags="auto") kpss_output = pd.Series(kpsstest, index=) for key,value in kpsstest.items(): kpss_output = value print (kpss_output)
ADF検定では、検定統計量、p値、および1%、5%、および10%信頼区間における臨界値の結果が得られます。
ADFテストがデータに適用されました。
:
adf_test(sunspots)
Results of Dickey-Fuller Test:Test Statistic -2.837781p-value 0.053076#Lags Used 8.000000Number of Observations Used 300.000000Critical Value (1%) -3.452337Critical Value (5%) -2.871223Critical Value (10%) -2.571929dtype: float64
0.05の有意水準とADF検定のp値に基づいて、帰無仮説を棄却することはできません。 したがって、系列は非定常である。
KPSS検定では、検定統計量、p値、および1%、5%、および10%の信頼区間における臨界値が得られます。
KPSSテストがデータに適用されるようになりました。
:
kpss_test(sunspots)
Results of KPSS Test:Test Statistic 0.669866p-value 0.016285Lags Used 7.000000Critical Value (10%) 0.347000Critical Value (5%) 0.463000Critical Value (2.5%) 0.574000Critical Value (1%) 0.739000dtype: float64
0.05の有意水準とKPSS検定のp値に基づいて、帰無仮説を棄却して代替案を支持する証拠があります。 したがって、系列はKPSSテストに従って非定常です。
シリーズが本当に静止していることを保証できるように、両方のテストを適用する方が常に優れています。 これらの定常試験を適用することの可能な結果は次のとおりです:
ここで、ADF検定とKPSS検定の結果の違いにより、系列はトレンド定常であり、厳密な定常ではないと推論することができます。 シリーズは、差分またはモデルフィッティングによって低下させることができます。
差分によるデトレンド¶
これは、時系列をデトレンドする最も簡単な方法の一つです。 現在のタイムステップでの値が、元の観測値と前のタイムステップでの観測値の差として計算される新しい系列が構築されます。
差分がデータに適用され、結果がプロットされます。
:
sunspots = sunspots - sunspots.shift(1)sunspots.dropna().plot(figsize=(12,8))
:
<AxesSubplot:>
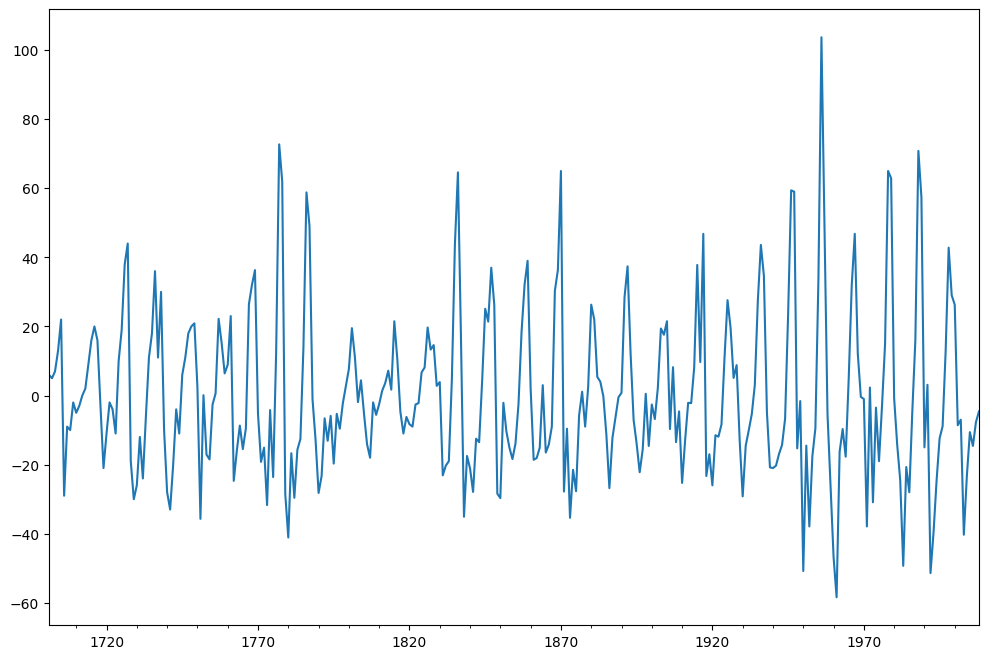
ADFテストは今これらのdetrended価値で適用され、定常性は点検される。
:
adf_test(sunspots.dropna())
Results of Dickey-Fuller Test:Test Statistic -1.486166e+01p-value 1.715552e-27#Lags Used 7.000000e+00Number of Observations Used 3.000000e+02Critical Value (1%) -3.452337e+00Critical Value (5%) -2.871223e+00Critical Value (10%) -2.571929e+00dtype: float64
ADF検定のp値に基づいて、帰無仮説を棄却して代替案を支持する証拠があります。 したがって、シリーズは厳密に固定されています。
kpssテストは現在、これらの低下した値に適用され、定常性がチェックされます。
:
kpss_test(sunspots.dropna())
Results of KPSS Test:Test Statistic 0.021193p-value 0.100000Lags Used 0.000000Critical Value (10%) 0.347000Critical Value (5%) 0.463000Critical Value (2.5%) 0.574000Critical Value (1%) 0.739000dtype: float64
/home/travis/build/statsmodels/statsmodels/statsmodels/tsa/stattools.py:1911: InterpolationWarning: The test statistic is outside of the range of p-values available in thelook-up table. The actual p-value is greater than the p-value returned. warn_msg.format(direction="greater"), InterpolationWarning
KPSS検定のp値に基づいて、帰無仮説を棄却することはできません。 したがって、シリーズは静止しています。
結論¶
時系列の定常性をチェックするための二つのテスト、すなわちADFテストとKPSSテストが使用されます。 デトレンドは、差分を使用して実行されます。 トレンド定常時系列は、厳密な定常時系列に変換されます。 必要な予測モデルを固定時系列データに適用できるようになりました。