まず、二重形式の線形/リッジ回帰を見てから、それを”カーネル化”する方法を示します。 後者の説明では、カーネルが何であるか、そして”カーネルのトリック”が何であるかを見ていきます。
二重形式のリッジ回帰
線形回帰は、通常、列(特徴)の線形結合として一次形式で与えられます。 しかし、新しいデータ(推論を実行している)の内積と各トレーニングデータとの線形結合である2番目の二重形式が存在します。
リッジ回帰(L2正則化線形回帰)の場合を考え、基本的な線形回帰は\(\lambda=0\)の場合に対応することを覚えておいてください。 ここで、\(X\)と\(Y\)は\(n\times m\)のトレーニングデータを参照し、\(x^\prime,y^\prime\)は推定される新しいケースを参照します。:
\ \ \ \
ここで、\(\langle X_I,x^\prime\rangle\)は内積/内積なので、\(\langle X_I,x^\prime\rangle=X^T_I x^\prime=\sum_j^m X_{i,j}x^\prime_j\)です。
双対形式は、線形/リッジ回帰は、新しいケースの内積の加重和の推定値を各トレーニングケースで提供するものとしても理解できることを示しています。
これは、行よりも多くの列がある場合でも線形回帰を行うことができることを意味しますが、(i)L2正則化を使用してこれを行うことができるので、これは常に\(X^TX\)行列を可逆にし、(ii)\(XX^T\)行列は、反転の数値的安定性を確保するためにl2正則化を必要とすることが多いため、これの重要性は誇張することができます。 また、学習データ内の各追加データが新しいものをもたらす順次学習プロセスの多くとして線形回帰を表示することができます。
最も重要なのは、我々の目的のために、しかし、二重形式は興味深い特徴を持っています:特徴ベクトルは内積の内側の方程式でのみ発生します。 これは、\(XX^T\)が学習データ内の特徴ベクトルのすべてのペアの内積に対応する行列を生成するため、\(\alpha\)の定義においても当てはまります。\(XX^T\)は、\(XX^T\)の内積に対応する行列を生成します。\(XX^T\)は、\( 私達が進むと同時に私達はこれの重要性を見る。
余談:興味のある学生は、この記事の最後のダウンロードセクションにあるDerivation of Dual Form documentでdual Formがどのように派生したかを見ることができます。
非線形二重リッジ回帰
我々は、非線形特徴変換を使用する標準的な方法により、非線形モデルに私たちの二重形式のリッジ回帰を回すことができます\(\phi\):
\ \
カーネル関数
カーネル関数、\(K:\mathcal X\times\mathcal X\to\mathbb{R}\)は、対称である関数です–\(K(x_1、x_2)=K(x_2、x_1)\)–正定値(正式な定義については脇を参照してください)。 正定性は、カーネルの使用を正当化する数学で使用されます。 しかし、重要な数学的知識がなければ、その定義は直感的には明らかではありません。 したがって、正定性の定義からカーネルを理解しようとするのではなく、いくつかの例を挙げてそれらを紹介します。
これを行う前に、カーネルは二引数関数ですが、それらは最初の引数に位置し、第二の引数の関数であると考えるのが一般的です。 この解釈によれば、\(K_X(y)\)のような表記が表示され、これは\(K(x,y)\)と同等です。 特に、カーネルは、学習データのデータポイント(特徴ベクトル)に”位置する”単一の引数関数であると考えることがよくあります。 時々、あなたは私たちのデータポイントにカーネルを”落とす”ことを読むでしょう。 したがって、特徴ベクトル\(x_i\)がある場合、その上にカーネルをドロップし、\(X_i\)に位置し、\(K(x_i,x)\)に相当する関数\(K_{x_i}(x)\)につながります。
カーネルはパラメトリック族のメンバーとして指定されることが多いことにも注意してください。 そのようなカーネルファミリの例は次のとおりです:
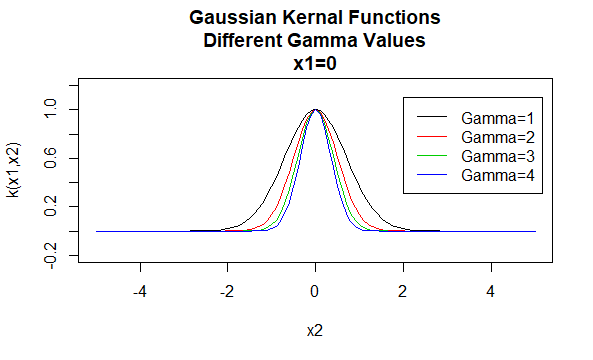
ガウス核
ガウス核は動径基底関数核の一例であり、動径基底核と呼ばれることもある。 放射状基底関数カーネルの値は、引数ベクトルの位置ではなく、引数ベクトル間の距離にのみ依存します。 このようなカーネルは、静止とも呼ばれます。Parameters K(X_1,x_2)=e^{-\gamma\|x_1-X_2}eとすると、Parameters k(x_1,x_2)=e^{-\gamma\|x_1–X_2}eとなります。\|^2}\)
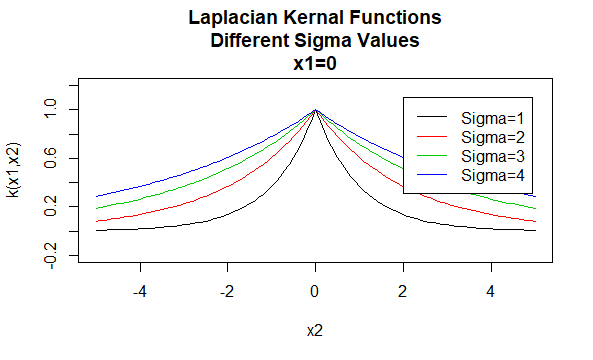
ラプラシアン核
ラプラシアン核は半径基底関数でもある。
パラメータ:\(\sigma\)
方程式形式: K K(X_1,X_2)=e^{-\frac{\|x_1-X_2\|}{\sigma}}\)
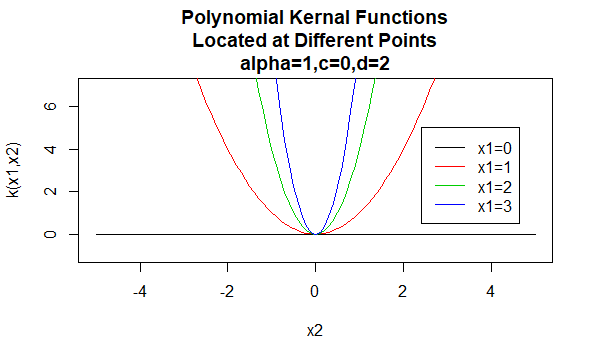
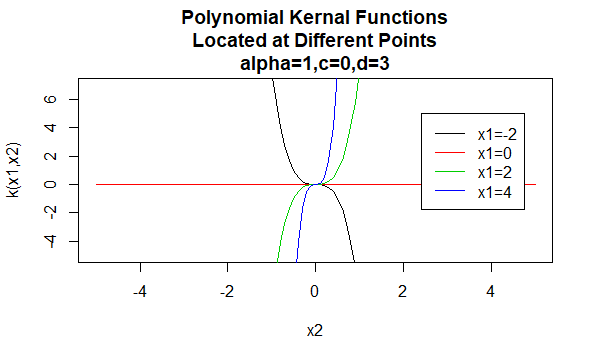
多項式カーネル
多項式カーネルは非定常カーネルの例です。 したがって、これらのカーネルは、それらの値に基づいて、同じ距離を共有する点のペアに異なる値を割り当てます。 これらのカーネルが正定値であることを保証するためには、パラメータ値は負でない必要があります。
パラメータ:\(\alpha,c,d\)
式形式:\(K(X_1,X_2)=(\alpha X_1^TX_2+c)^d\)
カーネルファミリのパラメータに特定の値を指定すると、カーネル関数が生成されます。 以下は、異なる点にある特定のパラメータ値を持つ上記のファミリのカーネル関数の例です(すなわち、プロットされたグラフは第二引数の関数であり、第一引数は特定の値に設定されています)。
余談ですが、: 興味のある学生は、この記事の最後にあるダウンロードセクションにあるKernels and Positive Definitenessドキュメントで、カーネルの肯定的な定義の定義を見ることができます。
カーネルのトリック
カーネル関数の重要性は非常に特別なプロパティから来ています: すべての正定値核\(K\)は数学的空間\(\mathcal{H}_K\)に関連しており(核の再現核ヒルベルト空間(Rkhs)として知られている)、\(K\)を2つの特徴ベクトル\(X_1,X_2\)に適用することは、これらの特徴ベクトルをある射影関数\(\phi\)によって\(\mathcal{H}_K\)に射影し、その内積をそこに取ることと等価である。:
\
カーネルに関連するRKHSsは、通常、高次元です。 ガウス族核のようないくつかの核については、それらは無限次元である。
上記は有名な”カーネルトリック”の基礎です:入力特徴量が内積の形でのみ統計モデルの方程式に関与している場合、方程式の内積をカーネル関数への呼び出しに置き換えることができ、結果は入力特徴量をより高い次元空間に投影したかのようになります(すなわち、多数の潜在的な変数特徴量につながる特徴変換を実行し)、その内積をそこに取り込んだかのようになります。 しかし、実際の投影を実行する必要はありません。
機械学習の用語では、カーネルに関連付けられたRKHは、入力空間ではなく、特徴空間として知られています。 カーネルトリックを介して、入力フィーチャをこのフィーチャ空間に暗黙的に投影し、その内積をそこに取ります。
カーネル回帰
これはカーネル回帰と呼ばれる手法につながります。 これは単にカーネルトリックをリッジ回帰の二重形式に適用したものである。 簡単にするために、\(K_{i,j}=k(X_I,X_J)\)となるようなカーネルまたはグラム行列\(K\)の考え方を紹介します。 次に、カーネル回帰の方程式を次のように書くことができます:
\ \
ここで、\(k\)はある正定値核関数である。
表現者の定理
何らかの形のモデルに対してL2正則化を実行するときに解こうとする最適化問題を考えてみましょう。\(f)\(f\)\(f\)\(f\)\(f\)\(f\)\(f\)\(f\)\(f\)\(f\)\(\):
\
カーネル回帰をカーネル\(k\)で実行するとき、正則化理論の重要な結果は、上の方程式の最小化器が次の形式になることです:
\
\(\alpha\)は上記のように計算されます。
これは正当にライオン化された表現者の定理です。 言い換えれば、特定のカーネルによって得られた陰的特徴空間における線形回帰の最適化問題の最小化器(したがって非線形カーネル回帰問題の最小化器)は、各特徴ベクトルに”位置する”カーネルの重み付けされた和によって与えられると述べている。
このトピックにはもっと言いたいことがあります。 どのようなグリーン関数(どのカーネルがサブセットであるか)が、L2正則化のような特定の正則化仕様を最小限に抑えるだけでなく、線形微分作用素に基づ カーネルとTikhonov正則化問題の最適解との間のこの関係は、機械学習におけるカーネルメソッドの重要性の原則的な理由です。 しかし、ここでの数学はこのコースを超えており、興味のある上級学生はHaykinのニューラルネットワークと学習機械の第七章に言及されています。
これは、そうすることが可能な場合にカーネル回帰を使用するための数学的正当性を与えます。 実際に使用する最適なカーネルを実際に計算することは通常不可能です–正則化ペナルティに使用する最適な線形微分演算子を知る必要があります。 特定の正則化ペナルティを最適化するために投影すべき関数が計算されており、例えば、薄板スプラインカーネルがL2正則化に最適であることが知 下側では、グラム行列を計算する必要があるため、カーネル回帰はうまくスケーリングされません。