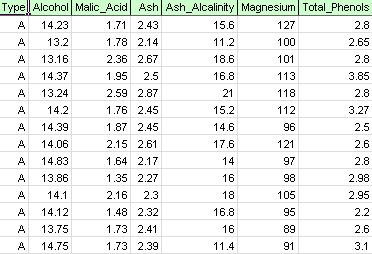
XLMinerリボンで、モデルの適用タブからヘルプ-例を選択し、予測/データマイニングの例を選択し、サンプルファイルWineを開きます。xlsx。 下の図に示すように、このサンプルデータセットの各行は、3つのワイナリー(A、B、またはC)のいずれかから採取したワインのサンプルを表します。 この例では、ワイナリーを表すType変数は無視され、クラスタリングはワインサンプルのプロパティ(残りの変数)に基づいて単純に実行されます。
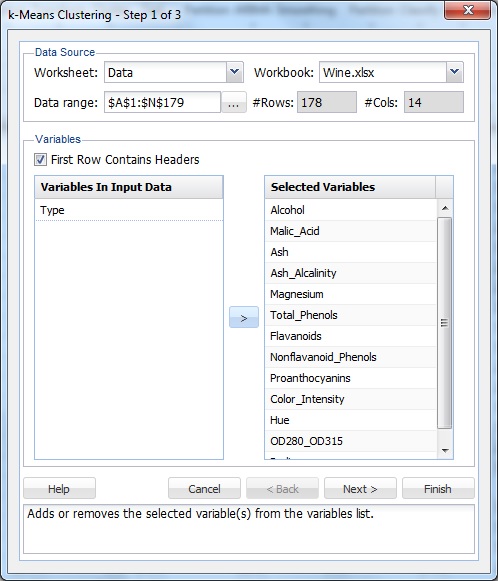
データセット内のセルを選択し、XLMinerリボンのデータ分析タブからXLMiner-Cluster-k-Means Clusteringを選択して、k-Means Clustering Step1of3ダイアログを開きます。
変数リストから、タイプ以外のすべての変数を選択し、>ボタンをクリックして、選択した変数を選択した変数リストに移動します。
次へをクリックして、Step2of3ダイアログに進みます。
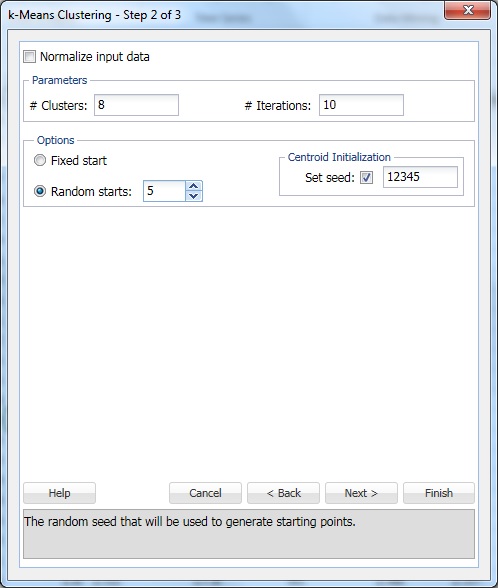
#Clustersで、8と入力します。 これは、k-meansクラスタリングアルゴリズムのパラメーター kです。 クラスターの数は少なくとも1であり、データ範囲内の観測値の数は最大で-1である必要があります。 Kを複数の異なる値に設定し、それぞれの出力を評価します。
#Iterationsをデフォルト設定の10のままにします。 このオプションの値は、プログラムが最初のパーティションから開始し、クラスタリングアルゴリズムを完了する回数を決定します。 クラスターの構成(およびデータの分離)は、開始パーティションごとに異なる場合があります。 プログラムは、指定された反復回数を通過し、距離測定を最小化するクラスタ構成を選択します。
ランダム開始を5に設定します。 このオプションを選択すると、アルゴリズムは任意のランダムな点からモデルの構築を開始します。 XLMinerは五つのクラスターセットを生成し、最適なクラスターに基づいて出力を生成します。
set seedはデフォルトで選択されています。 このオプションは、初期クラスターの重心を計算するために使用される乱数ジェネレータを初期化します。 乱数シードをゼロ以外の値(既定値は12345)に設定すると、最初のクラスター重心が計算されるたびに同じ乱数シーケンスが使用されます。 シードがゼロの場合、乱数発生器はシステムクロックから初期化されるため、乱数のシーケンスは重心が初期化されるたびに異なります。 Seedを設定して、クラスタリングメソッドの連続した実行をcomparableとして表示します。
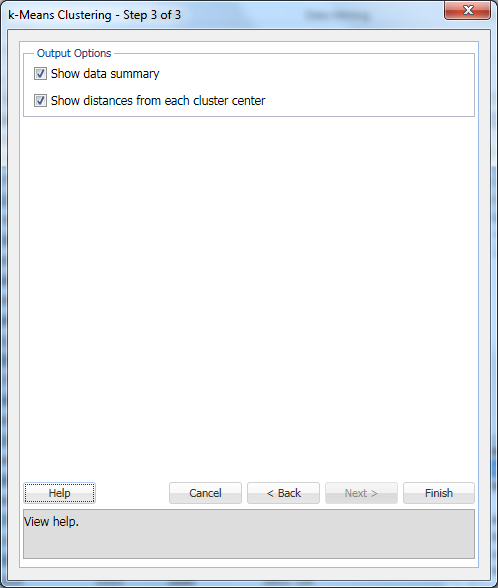
データを正規化するには、入力データの正規化オプションを選択します。 この例では、データは正規化されません。 [次へ]を選択して、[ステップ3of3]ダイアログを開きます。
“データの概要を表示”(デフォルト)と”各クラスタの中心からの距離を表示”(デフォルト)を選択し、”終了”をクリックします。
k-Meansクラスタリング方法は、指定されたk個の初期クラスターから始まります。 各反復で、レコードは最も近い重心または中心を持つクラスターに割り当てられます。 各反復の後、各レコードからクラスターの中心までの距離が計算されます。 これらの2つのステップは、レコードの再分配が距離値を増加させるまで繰り返されます(レコードの割り当てと距離の計算)。
ランダムな開始が指定された場合、アルゴリズムはkクラスターの中心をランダムに生成し、それらのクラスター内のデータポイントを適合させます。 このプロセスは、指定されたすべてのランダムな開始に対して繰り返されます。 出力は、最適な適合を示すクラスターに基づいています。
ワークシートKm_Output1がデータワークシートのすぐ右側に挿入されます。 出力ワークシートの一番上のセクションに、選択したオプションが表示されます。
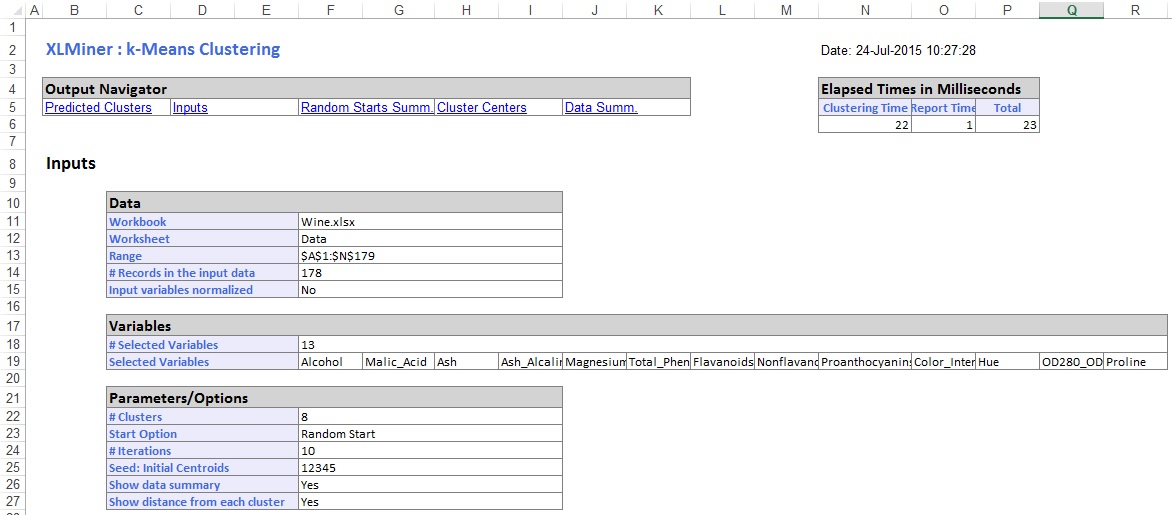
出力ワークシートの中央のセクションで、XLMinerは二乗距離の合計を計算し、二乗距離の最小合計で開始を最良の開始として決定しました(#5)。 最良の開始点が決定された後、XLMinerは、最良の開始点を開始点として使用して残りの出力を生成します。
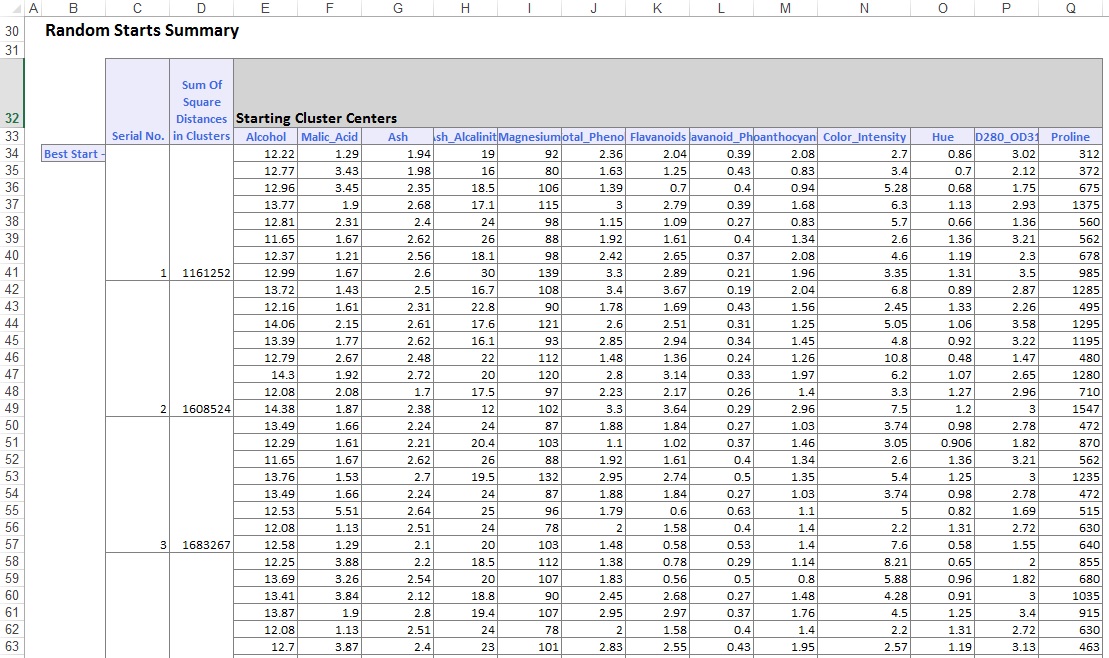
出力ワークシートの下部には、XLMinerがクラスタの中心を一覧表示しています(以下に示します)。 上のボックスには、クラスターの中心にある変数の値が表示されます。 クラスター8は、最高の平均アルコール、Total_フェノール、フラバノイド、プロアントシアニン、Color_Intensity、色相、およびプロリン含有量を持っています。 このクラスターを、平均Ash_AlcalinityとNonflavanoid_Phenolsが最も高いクラスター2と比較してください。
下のボックスは、クラスタの中心間の距離を示しています。 この表の値から、クラスター3は1,176.59の高い距離値のためにクラスター8とは大きく異なり、クラスター7は89.73の低い距離値でクラスター3に近いと判断されます。
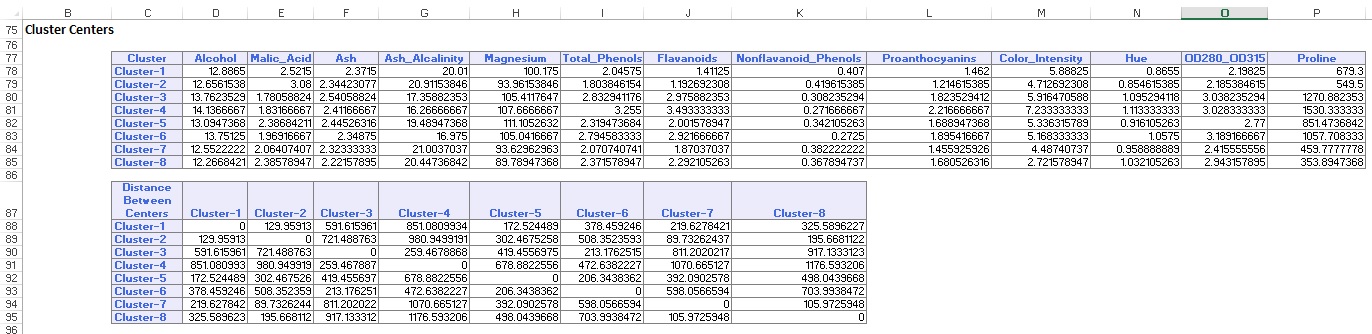
データの概要(以下)には、各クラスターに含まれるレコード(観測値)の数と、クラスターメンバーから各クラスターの中心までの平均距離が表示されます。 クラスター6の平均距離は42.79であり、24のレコードが含まれています。 このクラスターを、29.66の最小の平均距離を持ち、26のメンバーを含むクラスター2と比較します。
Km_Clusters1ワークシートをクリックします。 このワークシートには、各レコードが割り当てられているクラスターと、各クラスターまでの距離が表示されます。 最初のレコードの場合、クラスター6までの距離は23.205の最小距離であるため、この最初のレコードはクラスター6に割り当てられます。