この記事は、kafka topics architecture、kafka producer architecture、kafka consumer architecture、kafka ecosystem architectureを含むkafka architectureに関するシリーズからピックアップしています。
この記事は、ログ圧縮に関する設計に関するカフカのセクションに大きく触発されています。 あなたはそれをログ圧縮の周りのカフカのデザインについての崖のノートと考えることができます。
kafkaは、ログの時間やサイズに基づいて古いレコードを削除できます。 kafkaは、レコードキーの圧縮のためのログ圧縮もサポートしています。 ログ圧縮とは、kafkaが最新バージョンのレコードを保持し、ログ圧縮中に古いバージョンを削除することを意味します。
cloudurableは、kafkaトレーニング、kafkaコンサルティング、kafkaサポートを提供し、awsでkafkaクラスターを設定するのに役立ちます。
kafkaログ圧縮
ログ圧縮は、単一のトピックパーティションの各レコードキーの少なくとも最後の既知の値を保持します。 圧縮されたログは、クラッシュやシステム障害の後に状態を復元するのに役立ちます。
これらは、メモリ内サービス、永続的なデータストア、キャッシュのリロードなどに便利です。 データストリームの重要なユースケースは、データベーステーブルへのキー付き、変更可能なデータ変更への変更またはインメモリマイクロサービス内のオブジェクトへの変更をログに記録することです。
ログ圧縮は、各キーの最後の更新を保持する詳細な保持メカニズムです。 ログ圧縮されたトピックログには、最近変更されたキーだけでなく、すべてのレコードキーの最終的なレコード値の完全なスナップショッ
kafkaログ圧縮により、ダウンストリームコンシューマーはログ圧縮トピックから状態を復元できます。
カフカのログ圧縮構造
圧縮されたログでは、ログは頭と尾を持っています。 圧縮された丸太の頭部は従来のkafkaの丸太と同一である。 新しいレコードは、頭の最後に追加されます。
すべてのログ圧縮はログの末尾で機能します。 尾だけが圧縮されます。 ログの末尾にあるレコードは、圧縮クリーンアップで書き直された後に書き込まれたときに元のオフセットを保持します。
kafkaログ圧縮構造

kafkaログ圧縮の基本
すべての圧縮されたログオフセットは、コンシューマーが次に高いオフセットを取得するため、offsetのレコードが圧縮されていても有効なままです。
kafkaログ圧縮では、削除も可能です。 キーとヌルペイロードを持つメッセージは、そのキーの削除マーカーである墓石のように機能します。 墓石は、期間の後にクリアされます。 ログの圧縮は、ログセグメントを再コピーすることによって、バックグラウンドで定期的に実行されます。 圧縮は読み取りをブロックせず、プロデューサとコンシューマのi/oに影響を与えないように調整することができます。
kafkaログ圧縮プロセス
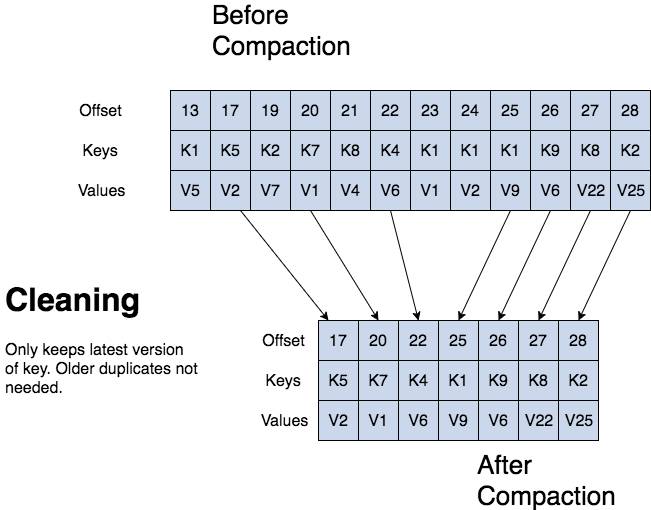
kafkaログ圧縮クリーニング
kafkaコンシューマーがログの先頭に追いついたままであれば、書き込まれたすべてのレコードが表示されます。
topic config min.compaction.lag.ms は、メッセージを圧縮する前に渡す必要がある最小期間を保証するために使用されます。 コンシューマーは、トピックconfig delete.retention.ms (デフォルトは24時間)よりも短い期間でコンシューマーがログの先頭に到達する限り、すべての墓石を表示します。 ログ圧縮は、メッセージの順序を変更することはありません。 メッセージのパーティションオフセットは変更されません。
ログの先頭から読み取るコンシューマは、書き込まれた順序ですべてのレコードの少なくとも最終状態を認識します。
kafkaログクリーナー
kafkaトピックにはログがあることを思い出してください。 ログはパーティションに分割され、パーティションはキーと値を持つレコードを含むセグメントに分割されます。
kafkaログクリーナーはログ圧縮を行います。 ログクリーナーには、バックグラウンドコンパクションスレッドのプールがあります。 これらのスレッドはログセグメントファイルを再コピーし、最近ログにキーが再表示された古いレコードを削除します。 各圧縮スレッドは、ログの先頭とログの末尾の比率が最も高いトピックログを選択します。 次に、圧縮スレッドは、ログの開始から終了までログを再コピーし、ログの後半でキーが発生するレコードを削除します。
log cleanerがログパーティションセグメントをクリーンアップすると、セグメントはすぐに古いセグメントを置き換えてログパーティションに交換されます。 この方法では、必要な追加のディスク領域が追加のログパーティションセグメントであるため、圧縮ではパーティション全体のスペースを倍にする必要はありません。
topic config for log compaction
トピックの圧縮を有効にするには、topic config log.cleanup.policy=compact を使用します。
レコードの書き込み後に圧縮を開始する遅延を設定するには、topic config log.cleaner.min.compaction.lag.ms を使用します。 レコードは、この期間の後まで圧縮されません。 この設定は、消費者にすべてのレコードを取得する時間を与えます。
ログ圧縮レビュー
kafkaがレコードを削除できる3つの方法は何ですか?
kafkaは、ログの時間やサイズに基づいて古いレコードを削除できます。 kafkaは、レコードキーの圧縮のためのログ圧縮もサポートしています。
ログ圧縮は何に適していますか?
ログ圧縮は最後の既知の値を保持するため、最新のレコードの完全なスナップショットであるため、インメモリサービス、永続的なデータストア、またはキャッ それは下流の消費者が彼らの状態を復元することを可能にします。
圧縮されたログの構造は何ですか? 構造を記述します。
圧縮された丸太では、丸太は頭と尾を持っています。 圧縮された丸太の頭部は従来のkafkaの丸太と同一である。 新しいレコードは、頭の最後に追加されます。 すべてのログ圧縮は、圧縮されたログの末尾で機能します。
圧縮後、ログレコードオフセットは変更されますか? いいえ。.
パーティションセグメントとは何ですか?
トピックにはログがあることを思い出してください。 トピックログはパーティションに分割され、パーティションはキーと値を持つレコードを含むセグメントファイルに分割されます。 セグメントファイルは、それが圧縮を記録することになると分割し、征服を可能にします。 セグメントファイルはパーティションの一部です。 log cleanerがログパーティションセグメントをクリーンアップすると、セグメントはすぐに古いセグメントファイルを置き換えてログパーティ この方法では、必要な追加のディスク領域が追加のログパーティションセグメントであるため、圧縮ではパーティション全体の2倍の領域を必要としません。
cloudurableは、kafkaトレーニング、kafkaコンサルティング、kafkaサポートを提供し、awsでkafkaクラスターを設定するのに役立ちます。