를 의미합니다.2018. 아래 그림과 같이 이 예제 데이터 세트의 각 행은 세 개의 와인 양조장(ㅏ,비,또는 씨)중 하나에서 가져온 와인 샘플을 나타냅니다. 이 예제에서는 와이너리를 나타내는 유형 변수가 무시되고 클러스터링은 와인 샘플의 속성(나머지 변수)을 기반으로 간단하게 수행됩니다.
데이터 집합 내의 셀을 선택한 다음 데이터 분석 탭에서 클러스터링을 선택하여 클러스터링 단계 1/3 대화 상자를 엽니다.
변수 목록에서 유형을 제외한 모든 변수를 선택한 다음>버튼을 클릭하여 선택한 변수를 선택한 변수 목록으로 이동합니다.
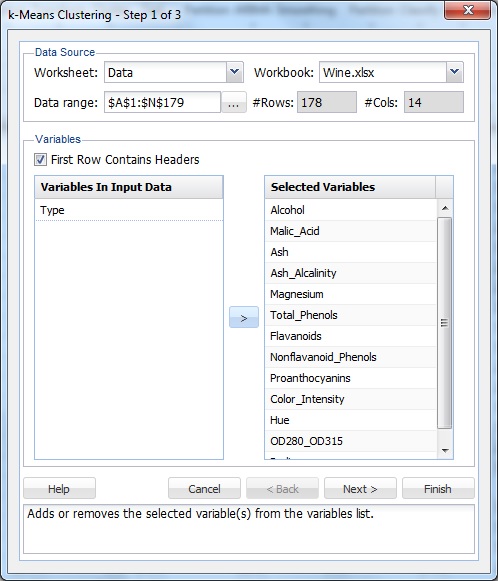
다음을 클릭하여 3 단계 중 2 단계 대화상자로 진행합니다.
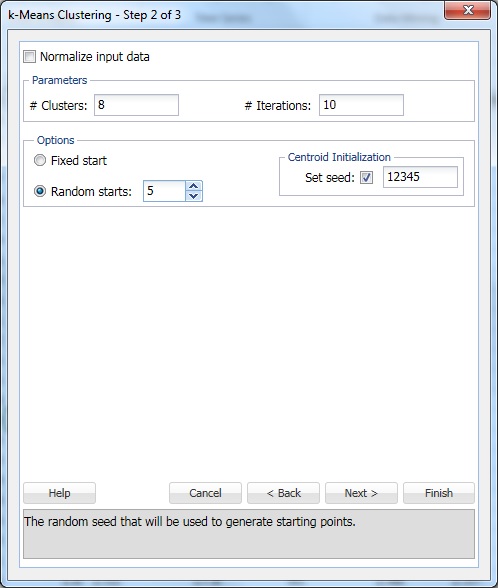
#클러스터에서 8 을 입력합니다. 이 매개 변수입니다 케이 에 케이-클러스터링 알고리즘을 의미합니다. 군집의 수는 최소 1 이상이어야 하며 최대 관측치 수는 데이터 범위에서-1 이어야 합니다. 설정 케이 여러 다른 값으로 각각 출력을 평가합니다.
#반복을 기본 설정인 10 으로 둡니다. 이 옵션의 값은 프로그램이 초기 파티션으로 시작하고 클러스터링 알고리즘을 완료하는 횟수를 결정합니다. 클러스터 구성(및 데이터 분리)은 시작 파티션마다 다를 수 있습니다. 이 프로그램은 반복의 지정된 번호를 통해 이동하고,거리 측정을 최소화하는 클러스터 구성을 선택합니다.
무작위 시작을 5 로 설정합니다. 이 옵션을 선택하면 알고리즘이 임의의 지점에서 모델 작성을 시작합니다. 5 개의 클러스터 세트를 생성하고 최상의 클러스터를 기반으로 출력을 생성합니다.
시드 설정은 기본적으로 선택되어 있습니다. 이 옵션은 초기 군집 중심점을 계산하는 데 사용되는 난수 생성기를 초기화합니다. 난수 시드를 0 이 아닌 값(기본값 12345)으로 설정하면 초기 클러스터 중심이 계산될 때마다 동일한 난수 시퀀스가 사용됩니다. 초기값이 0 이면 난수 생성기는 시스템 클럭에서 초기화되므로 중심값이 초기화될 때마다 난수 시퀀스가 다릅니다. 클러스터링 메서드의 연속 실행을 비교할 수 있도록 초기값을 설정합니다.
입력 데이터 정규화 옵션을 선택하여 데이터를 정규화합니다. 이 예제에서는 데이터가 정규화되지 않습니다. 다음을 선택하여 3 단계 중 3 단계 대화 상자를 엽니다.
데이터 요약 표시(기본값)및 각 군집 중심으로부터의 거리 표시(기본값)를 선택한 다음 마침을 클릭합니다.
케이-클러스터링 방법은 지정된 대로 케이 초기 클러스터로 시작합니다. 각 반복에서 레코드는 가장 가까운 중심 또는 중심을 가진 클러스터에 할당됩니다. 각 반복 후에 각 레코드에서 클러스터 중앙까지의 거리가 계산됩니다. 레코드의 재배포로 인해 거리 값이 증가할 때까지 이러한 두 단계(레코드 할당 및 거리 계산)가 반복됩니다.
무작위 시작이 지정되면 알고리즘은 무작위로 클러스터 센터를 생성하고 해당 클러스터의 데이터 포인트를 맞 춥니 다. 이 프로세스는 지정된 모든 임의 시작에 대해 반복됩니다. 출력은 가장 적합한 클러스터를 기반으로 합니다.
워크시트는 데이터 워크시트의 오른쪽에 바로 삽입됩니다. 출력 워크시트의 맨 위 섹션에 선택한 옵션이 나열됩니다.
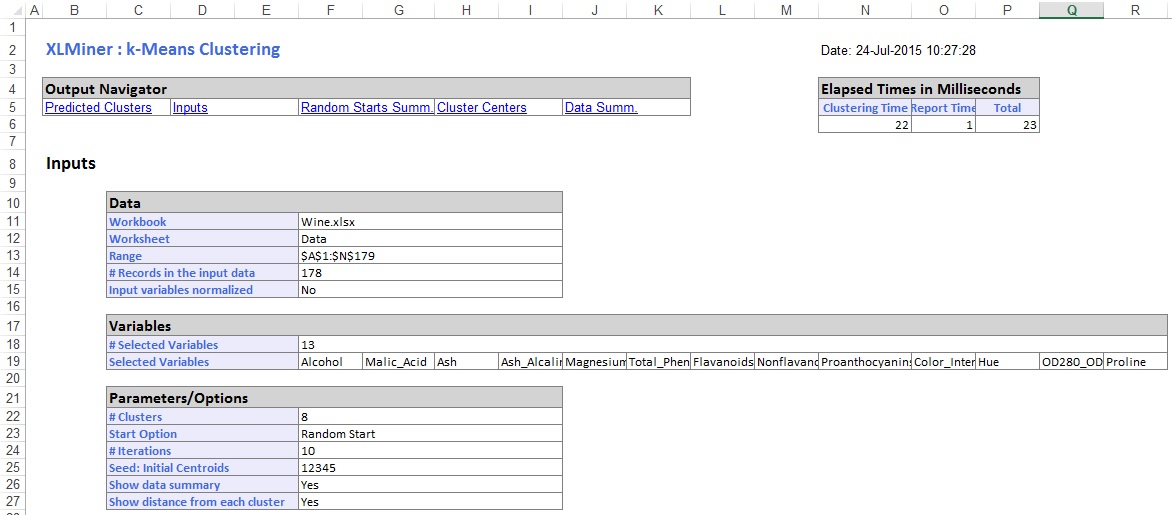
출력 워크시트의 중간 부분에서,엑스엘마이너는 제곱 거리의 합을 계산하고 가장 낮은 제곱 거리의 합을 가장 좋은 시작(#5)으로 시작을 결정했다. 최상의 시작이 결정되면 최상의 시작을 시작점으로 사용하여 나머지 출력을 생성합니다.
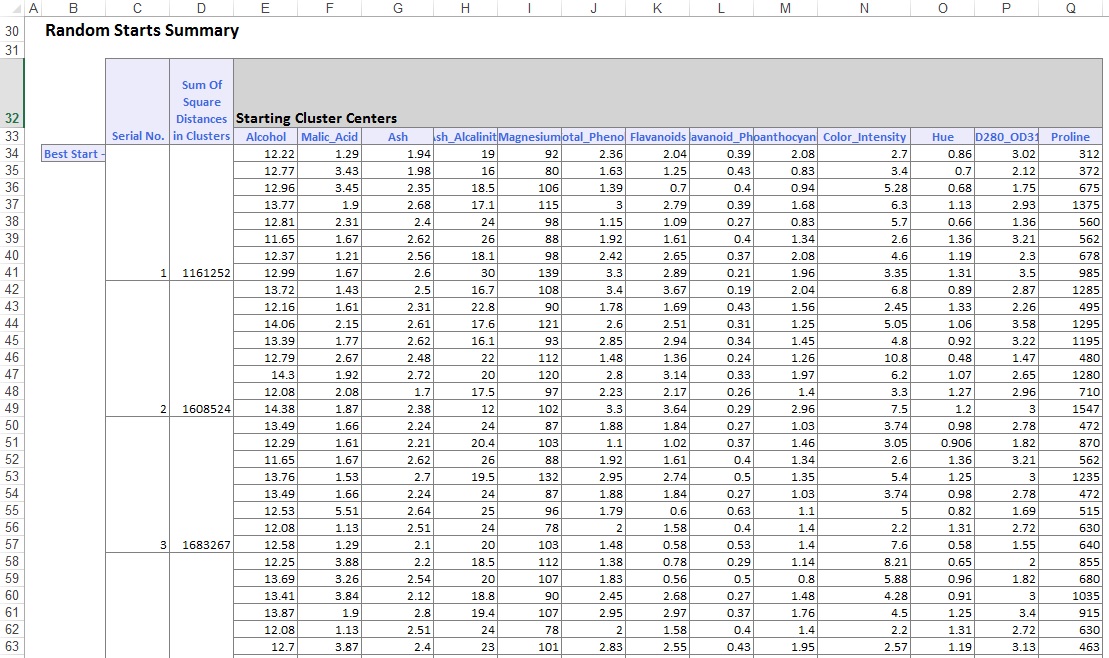
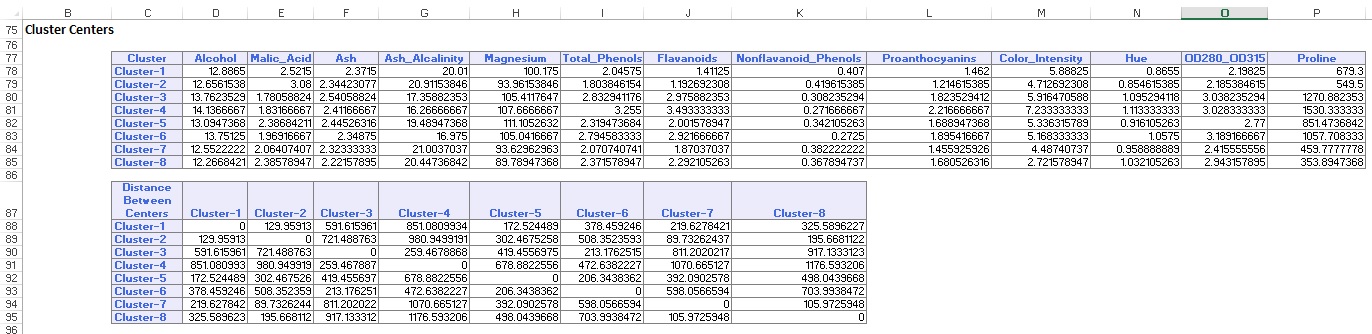
출력 워크시트의 아래 부분에 클러스터 센터가 나열되어 있습니다(아래 그림 참조). 위쪽 상자에는 클러스터 센터의 변수 값이 표시됩니다. 클러스터 8 은 평균 알코올,총 페놀,플라 바 노이드,프로 안토시아닌,색상 강도,색조 및 프롤린 함량이 가장 높습니다. 이 클러스터를 클러스터 2 와 비교하면 평균 재칼륨 및 비플라바노이드 페놀이 가장 높습니다.
아래쪽 상자는 군집 중심 사이의 거리를 나타냅니다. 이 표의 값으로부터,클러스터 3 은 1,176.59 의 높은 거리 값으로 인해 클러스터 8 과 매우 다르며,클러스터 7 은 낮은 거리 값이 89.73 인 클러스터 3 에 가깝다고 판단된다.
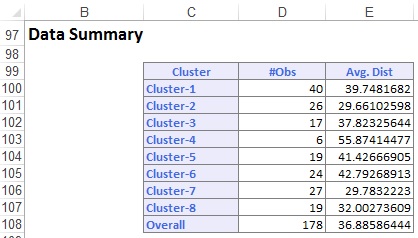
데이터 요약(아래)은 각 클러스터에 포함된 레코드(관측치)의 수와 클러스터 멤버에서 각 클러스터의 중심까지의 평균 거리를 표시합니다. 클러스터 6 의 평균 거리는 42.79 이며 24 개의 레코드를 포함합니다. 이 클러스터를 가장 작은 평균 거리가 29.66 이고 26 개의 멤버를 포함하는 클러스터 2 와 비교하십시오.
워크시트를 클릭합니다. 이 워크시트에는 각 레코드가 할당된 클러스터와 각 클러스터까지의 거리가 표시됩니다. 첫 번째 레코드의 경우 클러스터 6 까지의 거리는 최소 거리 23.205 이므로 이 첫 번째 레코드는 클러스터 6 에 할당됩니다.