Apache Spark is een data analytics tool die kan worden gebruikt om gegevens van HDFS, S3 of andere gegevensbronnen in het geheugen te verwerken. In deze post, zullen we Apache Spark installeren op een Ubuntu 17.10 machine.
Ubuntu versie
voor deze gids gebruiken we Ubuntu versie 17.10 (GNU/Linux 4.13.0-38-generic x86_64).
Apache Spark is een onderdeel van het Hadoop-ecosysteem voor Big Data. Probeer Apache Hadoop te installeren en maak er een voorbeeldtoepassing mee.
bestaande pakketten bijwerken
om de installatie voor Spark te starten, is het noodzakelijk dat we onze machine updaten met de nieuwste softwarepakketten die beschikbaar zijn. We kunnen dit doen met:
omdat Spark gebaseerd is op Java, moeten we het op onze machine installeren. We kunnen elke Java versie boven Java 6 gebruiken. Hier gebruiken we Java 8:
Spark-bestanden downloaden
alle benodigde pakketten bestaan nu op onze machine. We zijn klaar om de benodigde Spark tar bestanden te downloaden, zodat we kunnen beginnen met het opzetten van hen en voer een voorbeeld programma met Spark ook.
in deze handleiding installeren we Spark v2. 3. 0 Beschikbaar hier:

Spark download page
Download de bijbehorende bestanden met dit commando:
afhankelijk van de netwerksnelheid kan dit tot enkele minuten duren omdat het bestand groot is:
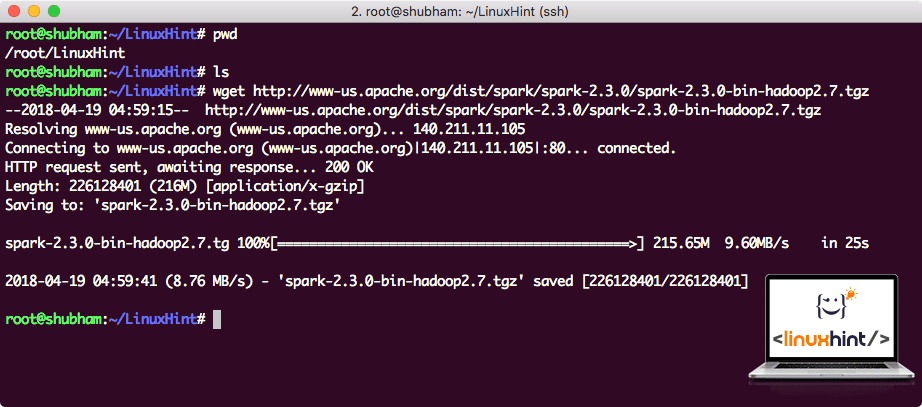
Downloaden Apache Spark
nu we het TAR-bestand hebben gedownload, kunnen we uitpakken in de huidige map:
dit duurt enkele seconden vanwege de grote bestandsgrootte van het archief:

niet-gearchiveerde bestanden in Spark
als het gaat om het upgraden van Apache Spark in de toekomst, kan het problemen veroorzaken als gevolg van Padupdates. Deze problemen kunnen worden vermeden door het creëren van een softlink naar Vonk. Voer dit commando uit om een softlink te maken:
Spark toevoegen aan Pad
om Spark scripts uit te voeren, zullen we het nu aan het pad toevoegen. Om dit te doen, open je het bashrc bestand:
voeg deze regels toe aan het einde van de .bashrc-bestand zodat het pad het pad van het Spark-uitvoerbare bestand kan bevatten:
export PATH = $SPARK_HOME / bin:$PATH
nu ziet het bestand eruit als:

Vonk toevoegen aan Pad
om deze wijzigingen te activeren, voer je het volgende commando uit voor het bashrc-bestand:
Launching Spark Shell
als we nu net buiten de spark directory staan, voer je het volgende commando uit om apark shell te openen:
we zullen zien dat Spark shell nu open is:

Launching Spark shell
we kunnen in de console zien dat Spark ook een Web Console heeft geopend op poort 404. Laten we het een bezoekje brengen.:

Apache Spark Web Console
hoewel we op de console zelf zullen werken, is de webomgeving een belangrijke plaats om naar te kijken wanneer u zware Spark-taken uitvoert, zodat u weet wat er gebeurt in elke Spark-taak die u uitvoert.
controleer de Spark shell-versie met een eenvoudig commando:
we krijgen iets als:
het maken van een sample Spark applicatie met Scala
nu zullen we een sample Word Counter applicatie maken met Apache Spark. Om dit te doen, laad eerst een tekstbestand in Spark Context op Spark shell:
Data: org.Apache.Vonk.rdd.RDD = /root/LinuxHint/spark / README.md MapPartitionsRDD at textFile at :24
scala>
nu, de tekst aanwezig in het bestand moet worden opgesplitst in tokens die vonk kan beheren:
tokens: org.Apache.Vonk.rdd.RDD = Kaartpartitiesrdd op flatMap op: 25
scala>
nu, initialiseer de telling voor elk woord naar 1:
tokens_1: org.Apache.Vonk.rdd.RDD = Kaartpartitiesrdd op kaart op: 25
scala>
tot slot, bereken de frequentie van elk woord van het bestand:
tijd om naar de uitvoer van het programma te kijken. Verzamel de tokens en hun respectieve tellingen:
res1: Array = Array((package,1), (For,3), (Programs,1), (processing.,1), (omdat, 1), (de, 1), (pagina](http://spark.apache.org/documentation.html)., 1), (cluster., 1), (its,1), ([run,1), (than,1), (API ‘ s,1), (have,1), (try,1), (computation,1), (through,1), (several,1), (This,2), (graph,1), (Hive,2), (storage,1), ([“Specificing,1), (To,2), (“yarn”,1), (Once,1), ([“usable,1), (prefer,1), (sparkpi,2), (engine,1), (version,1), (file,1), (documentation,,1), (processing,,1), (the,24), (are,1), (systems.,1), (params, 1), (NIET, 1), (verschillend, 1), (refereer, 2), (interactief, 2), (R,, 1), (gegeven.,1), (if, 4), (build, 4), (when, 1), (be, 2), (Tests, 1), (Apache, 1), (thread, 1), (programma ‘ s,, 1), (inclusief, 4), (./ bin / run-example, 2), (Spark., 1), (pakket.,1), (1000).count (), 1), (Versions, 1), (HDFS, 1), (D…
scala>
uitstekend! We waren in staat om een eenvoudig woord teller voorbeeld met behulp van Scala programmeertaal met een tekstbestand al aanwezig in het systeem.
conclusie
In deze les hebben we gekeken naar hoe we Apache Spark kunnen installeren en gebruiken op Ubuntu 17.10 machine en er ook een voorbeeldtoepassing op kunnen uitvoeren.
Lees hier meer op Ubuntu gebaseerde berichten.