we beginnen met het bekijken van dual-form linear / ridge regressie, voordat we laten zien hoe het te ‘kerneliseren’. Bij het uitleggen van dit laatste, zullen we zien wat kernels zijn, en wat de ‘kerneltruc’ is.
Dual-form Ridge regressie
lineaire regressie wordt meestal gegeven in de primaire vorm als een lineaire combinatie van kolommen (kenmerken). Er bestaat echter een tweede, dubbele vorm waarin het een lineaire combinatie is van het innerlijke product van een nieuw gegeven (waarop we de gevolgtrekking uitvoeren) met elk van de trainingsgegevens.
we beschouwen het geval van ridge regressie (L2 geregulariseerde lineaire regressie), waarbij we bedenken dat fundamentele lineaire regressie overeenkomt met het geval waarin \(\lambda = 0\). Dan zijn de formules voor ridge regressie, waarbij \(X\) en \(Y\) verwijzen naar de\ (n \ times m\) trainingsgegevens en \(x^ \ prime, y^ \ prime\) een nieuw te schatten geval,:
\ \ \ \
waar \(\langle X_i, x^ \ prime \ rangle\) het binnenste/puntproduct is, dus \(\langle X_i,x^\prime \rangle = X^T_i x^\prime = \sum_j^m X_{i,j} x^\prime_j\).
de duale vorm toont aan dat lineaire/ridge-regressie ook kan worden begrepen als een schatting van een gewogen som van het inwendige product van een nieuw geval bij elk van de opleidingsgevallen.
het betekent dat we lineaire regressie kunnen doen, zelfs als er meer kolommen dan rijen zijn, hoewel het belang hiervan kan worden overschat omdat (I) we dit toch kunnen doen via het gebruik van L2 regularisatie omdat dit altijd de \(x^TX\) matrix inverteerbaar maakt; en (ii) de \(XX^T\) matrix vaak toch L2 regularisatie nodig heeft om numerieke stabiliteit voor de inversie te garanderen. Het stelt ons ook in staat om lineaire regressie te zien als veel meer van een sequentieel leerproces, waarbij elk extra gegeven in de trainingsgegevens iets nieuws brengt.
het belangrijkste voor onze doeleinden is echter dat de duale vorm de interessante eigenschap heeft: featurevectoren komen alleen voor in de vergelijkingen binnen binnenproducten. Dit geldt zelfs in de definitie van \(\alpha\), omdat \(XX^T\) de matrix produceert die overeenkomt met de innerlijke producten van elk paar featurevectoren in de trainingsgegevens. We zullen het belang hiervan inzien naarmate we verder gaan.
even terzijde: geïnteresseerde studenten kunnen zien hoe de duale vorm werd afgeleid in de afleiding van duale vorm document beschikbaar in de downloads sectie aan het einde van dit artikel.
Non-Lineaire Dual-Ridge-Regressie
Wij onze dubbele vorm ridge-regressie in een niet-lineair model met de standaard methode van het gebruik van een niet-lineaire functie transformaties \(\phi\):
\ \
Kernel Functies
Een kernel functie, \(K: \mathcal X \times \mathcal X \in \mathbb{R}\), is een functie die symmetrisch – \(K) (x_1,x_2)=K(x_2,x_1)\) en positieve bepaald (zie het opzij voor een formele definitie). Positief-definiteness wordt gebruikt in de wiskunde die het gebruik van kernels rechtvaardigt. Maar zonder significante wiskundige kennis is de definitie niet intuïtief verhelderend. Dus in plaats van te proberen kernels te begrijpen uit de definitie van positieve-definiteness, zullen we ze introduceren met een aantal voorbeelden.
voordat we dit doen, merken we op dat hoewel kernels twee-argument functies zijn, het gebruikelijk is om te denken dat ze zich bevinden op hun eerste argument, en dat ze een functie van hun tweede zijn. Volgens deze interpretatie zul je notatie zien zoals \(K_x(y)\), die gelijk is aan \(K(x,y)\) . In het bijzonder zullen we vaak denken aan kernels zijn enkele argument functies ‘gelokaliseerd’ op datapunten (feature vectoren) in onze trainingsgegevens. Soms lees je dat we kernels ‘laten vallen’ op datapunten. Dus als we een feature vector \(x_i\) hebben, zouden we er een kernel op laten vallen,wat leidt tot de functie \(K_{x_i}(x)\) gelegen op \(x_i\) en equivalent aan \(K(X_i, x)\).
we merken ook op dat kernels vaak worden gespecificeerd als leden van parametrische families. Voorbeelden van dergelijke kernelfamilies zijn::
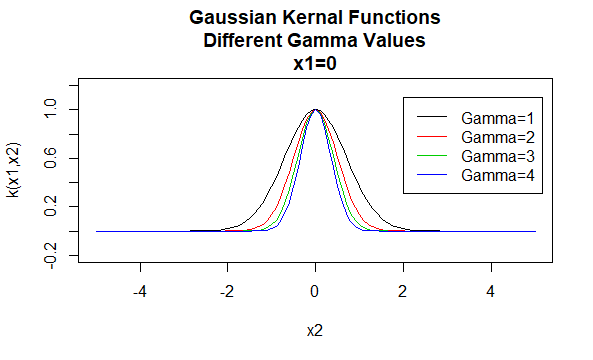
Gaussische Kernels
Gaussische kernels zijn een voorbeeld van radiale basisfunctie kernels en worden soms radiale basis kernels genoemd. De waarde van een kernel van de radiale basisfunctie hangt alleen af van de afstand tussen de argumentvectoren, in plaats van hun locatie. Dergelijke kernels worden ook stationaire genoemd.
Parameters: \(\gamma\)
Vergelijkingsvorm: \(K (X_1,X_2) = e^{- \gamma \ / X_1 – X_2 \|^2}\)
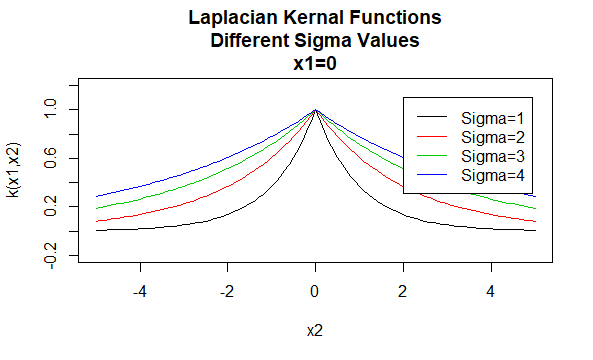
Laplaciaanse kernels
Laplaciaanse kernels zijn ook radiale basisfuncties.
Parameters: \(\sigma\)
Vergelijkingsvorm: \(K (X_1, X_2) = e^{-\frac{\| x_1 – X_2 \|}{\sigma}}\)
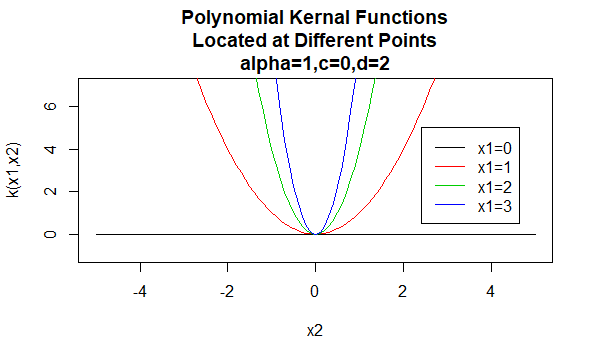
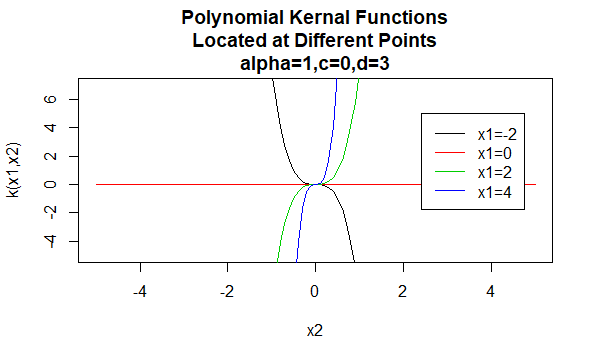
polynomiale Kernels
polynomiale kernels zijn een voorbeeld van niet-stationaire kernels. Dus deze kernels zullen verschillende waarden toewijzen aan paren van punten die dezelfde afstand Delen, gebaseerd op hun waarden. Parameterwaarden moeten niet-negatief zijn om er zeker van te zijn dat deze kernels positief bepaald zijn.
Parameters: \(\alpha , c , d\)
Vergelijkingsvorm:\(K (X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
het specificeren van bepaalde waarden voor de parameters van een kernelfamilie resulteert in een kernelfunctie. Hieronder zijn voorbeelden van kernels functies van de bovenstaande families met bepaalde parameterwaarden op verschillende punten (dat wil zeggen de geplot grafiek is een functie van het tweede argument, met het eerste argument ingesteld op een specifieke waarde).
Opzij: Geïnteresseerde studenten kunnen de definitie van positieve definiteness voor kernels zien in het Kernels en positieve Definiteness document beschikbaar in de downloads sectie aan het einde van dit artikel.
de Kerneltruc
het belang van kernelfuncties komt van een zeer speciale eigenschap: Elke positieve bepaalde kernel \K\) is in verband met een wiskundige ruimte, \(\mathcal{H}_K\), (bekend als het reproduceren van kernel Hilbert ruimte (RKHS) van de kernel), zodanig dat het toepassen van \K\) te voorzien van twee vectoren, \(X_1,X_2\) is gelijk aan het projecteren van deze feature vectoren in \(\mathcal{H}_K\) door een projectie functie \(\phi\) en het nemen van hun innerlijke product:
\
De RKHSs geassocieerd met kernels zijn meestal hoog-dimensionale. Voor sommige kernels, zoals Gaussiaanse familie kernels, zijn ze oneindig dimensionaal.
het bovenstaande is De basis voor de beroemde ‘kernel trick’: Als de input functies zijn betrokken in de vergelijking van een statistisch model alleen in de vorm van innerlijke producten dan kunnen we vervangen door de innerlijke-producten in de vergelijking met oproepen aan de kernel functie en het resultaat is als we hadden geprojecteerd de input functies in een hoger-dimensionale ruimte (d.w.z. uitgevoerd met een functie-transformatie leidt tot een groot aantal latente variabele kenmerken) en hun innerlijke-product. Maar we hoeven nooit de eigenlijke projectie uit te voeren.
in de terminologie van machine learning staat de rkhs die aan de kernel zijn gekoppeld bekend als de feature space, in tegenstelling tot de input space. Via de kerneltruc projecteren we impliciet De invoerfuncties in deze featureruimte en nemen hun innerlijke product daar mee naartoe.
Kernelregressie
dit leidt tot de techniek die bekend staat als kernelregressie. Het is gewoon een toepassing van de kernel truc om de dubbele vorm van ridge regressie. Voor het gemak introduceren we het idee van de Kernel, of Gram, matrix, \(K\), zodanig dat \(K_{i,j}=k(X_i,X_j)\). Dan kunnen we de vergelijkingen voor kernel regressie schrijven als:
\ \
waarin \(k\) een positieve kernelfunctie is.
De Representer Stelling
Overwegen de optimalisatie probleem dat we proberen op te lossen bij het uitvoeren van L2 regularisatie voor een model van een formulier, \(f\):
\
Bij het uitvoeren van de kernel regressie met de kernel \k\), is een belangrijk gevolg van de regularisatie theorie dat de minimizer van de bovenstaande vergelijking van de vorm:
\
Met \(\alpha\) berekend zoals hierboven beschreven.
Dit is de terechte vertoningsstelling. In woorden, het zegt dat de minimizer van de optimalisatie probleem voor lineaire regressie in de impliciete feature ruimte verkregen door een bepaalde kernel (en dus de minimizer van de niet-lineaire kernel regressie probleem) zal worden gegeven door een gewogen som van kernels ‘gelokaliseerd’ bij elke feature vector.
over dit onderwerp valt nog veel meer te zeggen. We kunnen zelfs uitzoeken welke groene functie (waarvan kernels een subset zijn) bepaalde regularisatiespecificaties minimaliseert, zoals L2 regularisatie maar ook elke straf gebaseerd op een lineaire differentiaaloperator. Deze relatie tussen kernels en optimale oplossingen voor Tikhonov regularisatieproblemen is een belangrijke reden voor het belang van kernelmethoden in machine learning. Maar de wiskunde hier is voorbij deze cursus, en geïnteresseerde gevorderde studenten worden verwezen naar hoofdstuk zeven van Haykin ‘ s neurale netwerken en Leermachines.
dit geeft ons een wiskundige rechtvaardiging voor het gebruik van kernelregressie in gevallen waar dit mogelijk is. Eigenlijk is het uitwerken van de optimale kernel om te gebruiken meestal niet mogelijk – het vereist het kennen van de optimale lineaire differentiële operator te gebruiken voor de regularisatie boete. De functies waarop we zouden moeten projecteren om bepaalde regularisatie sancties te optimaliseren zijn berekend, en we weten bijvoorbeeld dat dunne plaat spline kernel optimaal is voor L2 regularisatie. Aan de andere kant, omdat we de Grammatrix moeten berekenen, schaalt kernelregressie niet goed – voor grote datasets is het een beter idee om naar neurale netwerken te gaan.