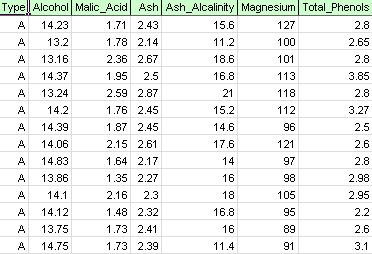
op het xlminer-lint, selecteer Help-Examples, dan Forecasting / Data Mining Examples, en open het voorbeeldbestand Wine.xlsx. Zoals in onderstaande figuur is aangegeven, vertegenwoordigt elke rij in deze voorbeeldgegevensreeks een wijnmonster dat is genomen uit een van de drie wijnmakerijen (A, B of C). In dit voorbeeld wordt de typevariabele die de wijnmakerij vertegenwoordigt genegeerd en wordt de clustering gewoon uitgevoerd op basis van de eigenschappen van de wijnmonsters (de resterende variabelen).
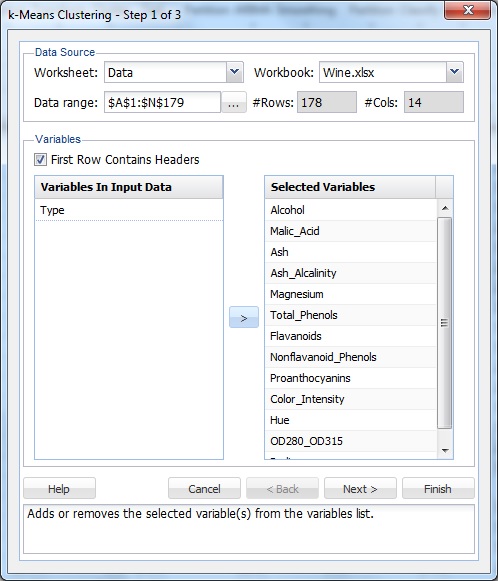
selecteer een cel binnen de gegevensset en selecteer vervolgens op het xlminer – lint op het tabblad Data – analyse XLMiner-Cluster-k-Means Clustering om het dialoogvenster k-Means Clustering Stap 1 van 3 te openen.
Selecteer alle variabelen behalve Type en klik vervolgens op de knop > om de geselecteerde variabelen naar de lijst met geselecteerde variabelen te verplaatsen.
klik op Volgende om verder te gaan naar het dialoogvenster Stap 2 van 3.
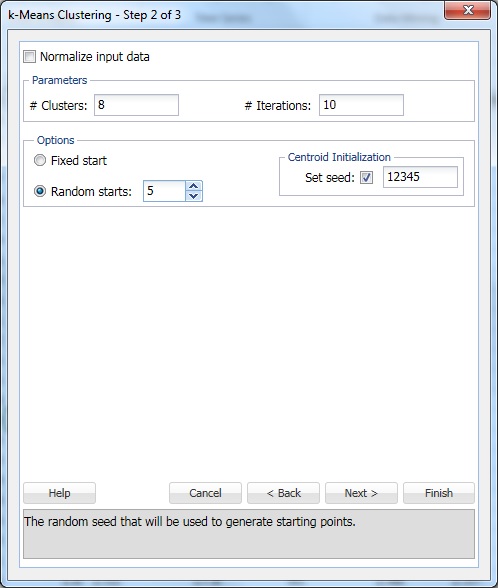
bij # Clusters, vul 8 in. Dit is de parameter k in het k-means clustering algoritme. Het aantal clusters moet ten minste 1 zijn en ten hoogste het aantal waarnemingen -1 in het gegevensbereik. Stel k in op verschillende waarden en evalueer de uitvoer van elk.
laat #iteraties staan op de standaardinstelling van 10. De waarde voor deze optie bepaalt hoe vaak het programma begint met een initiële partitie en het clustering algoritme voltooit. De configuratie van clusters (en data scheiding) kan verschillen van de ene beginpartitie naar de andere. Het programma zal het opgegeven aantal iteraties doorlopen en de clusterconfiguratie selecteren die de afstandsmeting minimaliseert.
stel willekeurige start in op 5. Wanneer deze optie is geselecteerd, begint het algoritme het model te bouwen vanaf elk willekeurig punt. XLMiner genereert vijf clustersets en genereert de output die op de beste cluster wordt gebaseerd.
set seed is standaard geselecteerd. Deze optie initialiseert de generator voor willekeurige getallen die wordt gebruikt om de initiële clustercentroids te berekenen. Het instellen van het begingetal op een niet-nulwaarde (standaard 12345) zorgt ervoor dat dezelfde volgorde van willekeurige getallen wordt gebruikt telkens wanneer de initiële clustercentroïden worden berekend. Wanneer het zaad nul is, wordt de random number generator geïnitialiseerd vanaf de systeemklok, dus de volgorde van willekeurige getallen is verschillend elke keer dat de centroids worden geïnitialiseerd. Stel het zaad in om opeenvolgende runs van de clustering methode als vergelijkbaar te zien.
Selecteer de optie invoergegevens normaliseren om de gegevens te normaliseren. In dit voorbeeld worden de gegevens niet genormaliseerd. Selecteer Volgende om het dialoogvenster Stap 3 van 3 te openen.
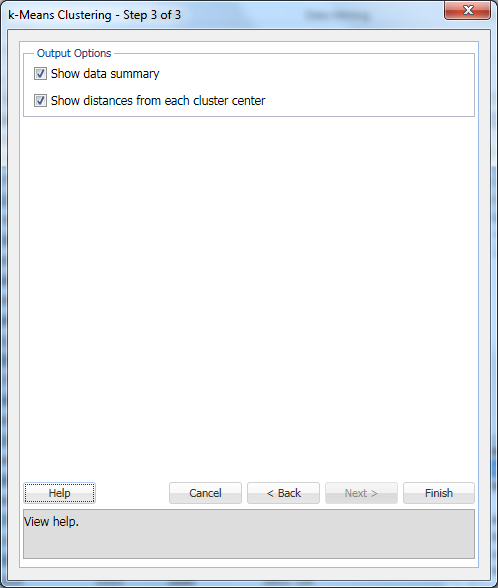
Selecteer gegevensoverzicht weergeven (standaard) en afstanden weergeven vanaf elk clustercentrum (standaard) en klik vervolgens op Voltooien.
de k-Means Clustering methode begint met K initiële clusters zoals gespecificeerd. Bij elke iteratie worden de records toegewezen aan het cluster met het dichtstbijzijnde centroid of centrum. Na elke iteratie wordt de afstand van elk record tot het centrum van de cluster berekend. Deze twee stappen worden herhaald (de record toewijzing en afstand berekening) totdat de herverdeling van een record resulteert in een verhoogde afstand waarde.
wanneer een willekeurige start is opgegeven, genereert het algoritme de k-clustercenters willekeurig en past het bij de gegevenspunten in die clusters. Dit proces wordt herhaald voor alle opgegeven willekeurige start. De output is gebaseerd op de clusters die de beste pasvorm vertonen.
het werkblad KM_Output1 wordt onmiddellijk rechts van het Gegevenswerkblad ingevoegd. In het bovenste gedeelte van het werkblad uitvoer worden de geselecteerde opties weergegeven.
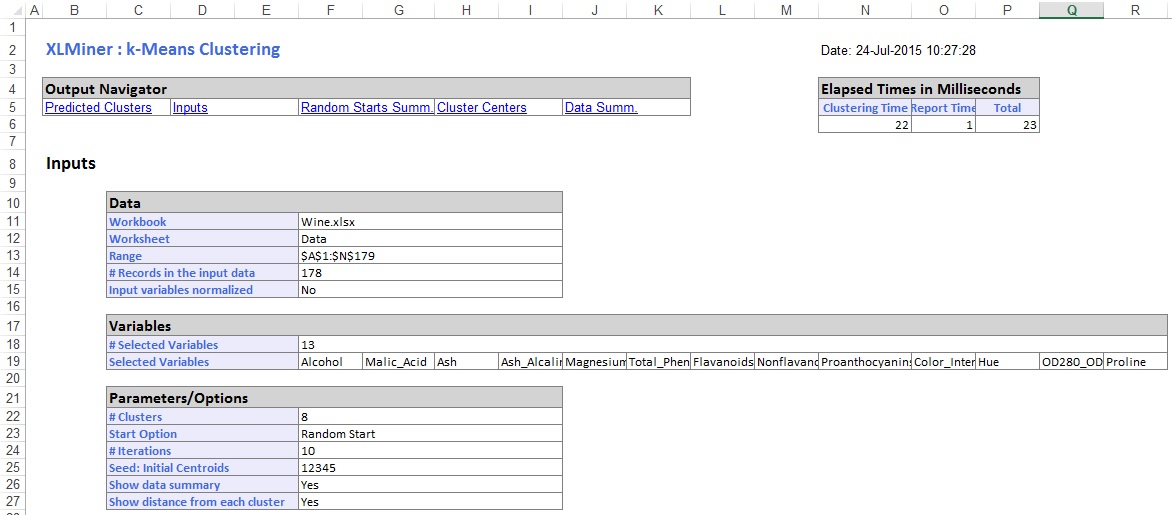
in het middelste gedeelte van het werkblad heeft XLMiner de som van de kwadraatafstanden berekend en het begin bepaald met de laagste som van de Kwadraatafstand als de beste Start (#5). Nadat de beste Start is bepaald, genereert XLMiner de resterende output met behulp van de beste Start als uitgangspunt.
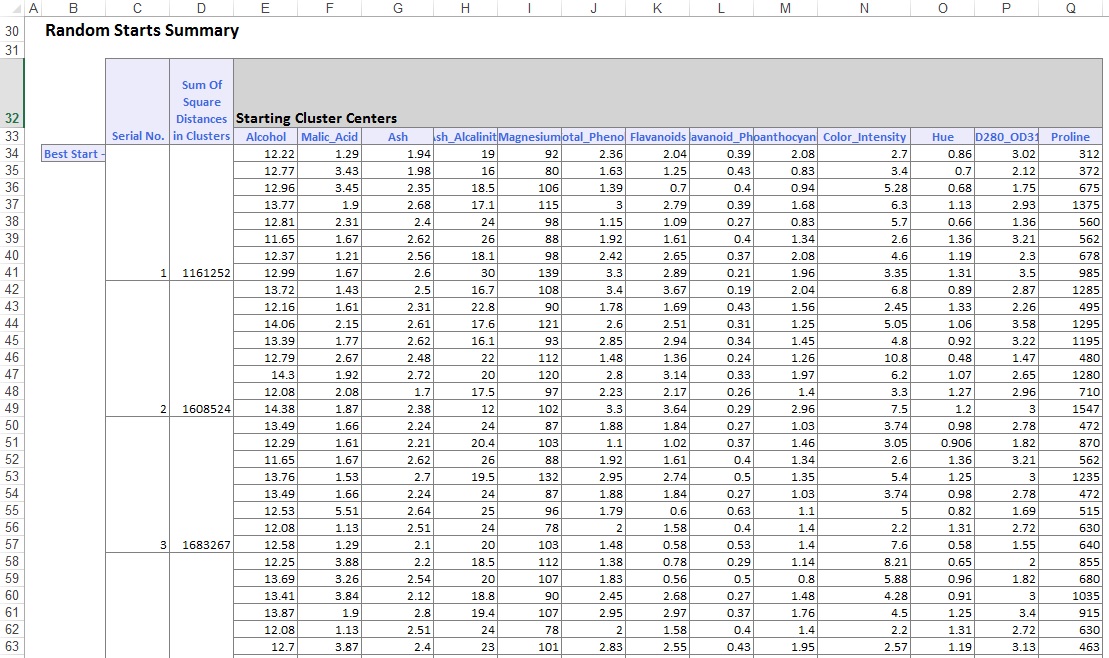
in het onderste gedeelte van het uitvoerwerkblad heeft XLMiner de Clustercentra vermeld (zie hieronder). In het bovenste vak worden de variabele waarden in de Clustercentra weergegeven. Cluster 8 heeft de hoogste gemiddelde Alcohol, Total_Phenols, Flavanoids, Proanthocyanins, Color_Intensity, tint, en Proline inhoud. Vergelijk dit cluster met Cluster 2, dat de hoogste gemiddelde Ash_Alcalinity en Nonflavanoid_Phenols heeft.
het onderste kader toont de afstand tussen de Clustercentra. Uit de waarden in deze tabel wordt bepaald dat Cluster 3 sterk verschilt van Cluster 8 vanwege de hoge afstandswaarde van 1,176.59, en Cluster 7 dicht bij Cluster 3 ligt met een lage afstandswaarde van 89,73.
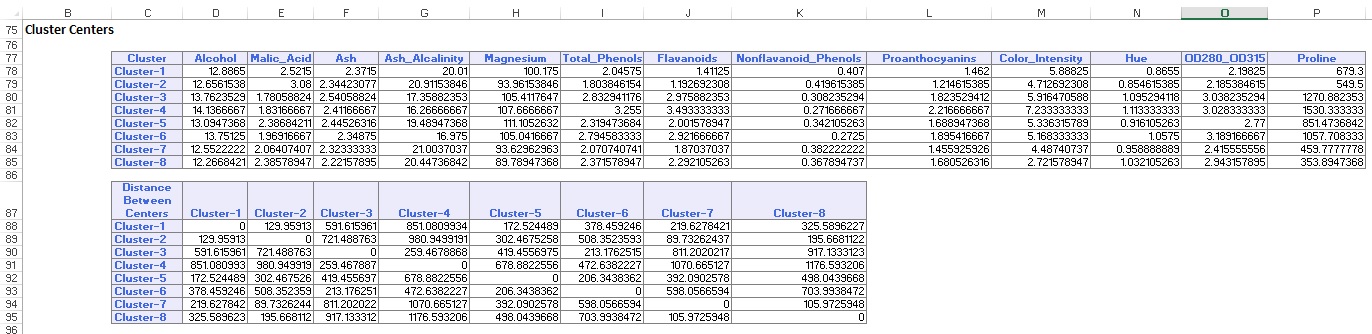
de gegevenssamenvatting (hieronder) geeft het aantal records (waarnemingen) weer dat in elk cluster is opgenomen en de gemiddelde afstand tussen clusterleden en het centrum van elk cluster. Cluster 6 heeft de hoogste gemiddelde afstand van 42,79, en bevat 24 records. Vergelijk dit cluster met Cluster 2, dat de kleinste gemiddelde afstand van 29.66 heeft en 26 leden omvat.
klik op het km_clusters1-werkblad. Dit werkblad toont het cluster waaraan elke record is toegewezen en de afstand tot elk van de clusters. Voor het eerste record is de afstand tot Cluster 6 de minimumafstand van 23.205, dus dit eerste record wordt toegewezen aan Cluster 6.