dit bericht is echt een selectie uit onze serie over kafka architecture die kafka topics architectuur , kafka producer architecture , Kafka consumer architecture en kafka ecosystem architecture omvat .
dit artikel is sterk geïnspireerd door de Kafka-sectie over het ontwerp rond het verdichten van logboeken . je kunt het zien als de klif notities over kafka ontwerp rond log verdichting .
kafka kan oudere records verwijderen op basis van de tijd of grootte van een log. kafka ondersteunt ook log verdichting voor record key verdichting. log verdichting betekent dat kafka de laatste versie van een record zal bijhouden en de oudere versies zal verwijderen tijdens een log verdichting.
jean-paul azar werkt bij cloudurable . cloudurable biedt kafka training, Kafka consulting, Kafka ondersteuning en helpt bij het opzetten van Kafka clusters in aws .
- kafka log-verdichting
- Kafka log verdichtingsstructuur
- kafka log verdichting structuur
- Kafka log verdichting basis
- kafka log verdichtingsproces
- Kafka log verdichtingsproces
- kafka log cleaner
- topic config voor log-verdichting
- log compaction review
- wat zijn drie manieren waarop kafka records kan verwijderen?
- waarvoor is logverdichting goed?
- Wat is de structuur van een verdicht log? beschrijf de structuur.
- Wat is een partitiesegment?
kafka log-verdichting
log-verdichting behoudt ten minste de laatst bekende waarde voor elke recordsleutel voor een enkele topic-partitie. gecomprimeerde logs zijn nuttig voor het herstellen van de toestand na een crash of systeemstoring.
ze zijn nuttig voor in-memory services, permanente dataopslag, het opnieuw laden van een cache, enz. een belangrijk gebruik van datastromen is het loggen van wijzigingen in gecodeerde gegevens, veranderbare gegevenswijzigingen in een databasetabel of wijzigingen in objecten in in-memory microservice.
log verdichting is een granulair retentiemechanisme dat de laatste update voor elke sleutel behoudt. een log gecomprimeerd topic log bevat een volledige momentopname van de definitieve recordwaarden voor elke record sleutel niet alleen de onlangs gewijzigde sleutels.
kafka log compaction stelt downstream consumenten in staat om hun status te herstellen van een log compacted topic.
Kafka log verdichtingsstructuur
bij een verdicht log heeft het log kop en staart. de kop van de verdichte log is identiek aan een traditionele Kafka log. nieuwe records worden toegevoegd aan het einde van het hoofd.
alle verdichtingswerkzaamheden aan de achterkant van het logboek. alleen de staart wordt verdicht. records in de staart van het logboek behouden hun oorspronkelijke offset wanneer ze zijn geschreven nadat ze zijn herschreven met verdichting opschonen .
kafka log verdichting structuur

Kafka log verdichting basis
alle gecomprimeerde log offsets blijven geldig, zelfs als record bij offsetafstand is gecomprimeerd als een consument krijgt de volgende hoogste offsetafstand.
kafka log verdichting maakt het ook mogelijk om te verwijderen. een bericht met een sleutel en een null payload werkt als een grafsteen, een delete marker voor die sleutel. grafstenen worden na een periode gewist. log verdichting wordt periodiek uitgevoerd op de achtergrond door het opnieuw kopiëren van log segmenten. verdichting blokkeert lezen niet en kan worden beperkt om te voorkomen dat i/o van producenten en consumenten wordt beïnvloed.
kafka log verdichtingsproces
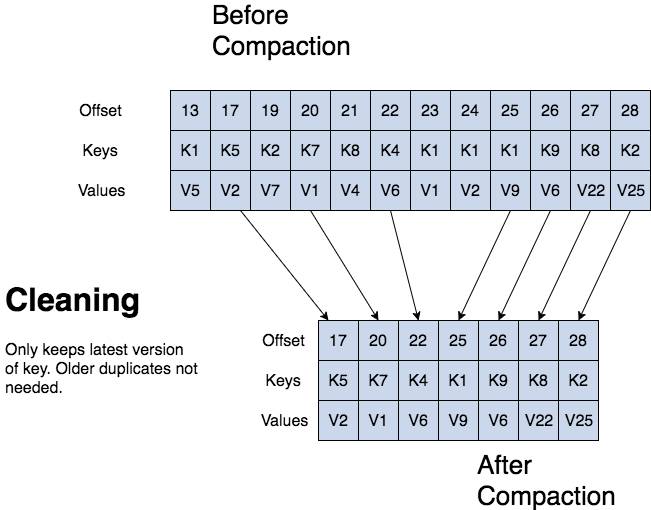
Kafka log verdichtingsproces
als een Kafka-consument gevangen blijft tot het hoofd van de log, ziet hij elk record dat geschreven is.
topic config min.compaction.lag.ms wordt gebruikt om een minimale periode te garanderen die moet verstrijken voordat een bericht kan worden gecomprimeerd. de consument ziet alle grafstenen zolang de consument de kop van een log bereikt in een periode korter dan de topic config delete.retention.ms (de standaard is 24 uur). log verdichting zal nooit opnieuw te bestellen berichten, gewoon verwijderen sommige. partitieverschuiving voor een bericht verandert nooit.
elke lezing door de consument vanaf het begin van het logboek ziet ten minste de definitieve status van alle records in de volgorde waarin ze zijn geschreven.
kafka log cleaner
herinneren dat een Kafka topic een log heeft. een log wordt opgesplitst in partities en partities worden verdeeld in segmenten die records bevatten die sleutels en waarden hebben.
de Kafka log cleaner comprimeert logbestanden. de Log cleaner heeft een pool van achtergrond verdichting threads. deze threads herkopiëren logsegmentbestanden en verwijderen oudere records waarvan de sleutel onlangs opnieuw in het logboek verschijnt. elke verdichting thread kiest topic log dat de hoogste verhouding van log head tot log tail heeft. dan de verdichting thread herkopieert het logboek van begin tot eind verwijderen van records waarvan de sleutels later in het logboek.
naarmate de log cleaner de log partitiesegmenten opschoont, worden de segmenten verwisseld in de log partitie die onmiddellijk de oudere segmenten vervangt. op deze manier compactie vereist niet het dubbele van de ruimte van de gehele partitie als extra benodigde schijfruimte is slechts een extra log partitie segment – verdeel en heers.
topic config voor log-verdichting
gebruik topic config log.cleanup.policy=compact om verdichting voor een onderwerp in te schakelen .
om een vertraging in te stellen om records te comprimeren nadat ze zijn geschreven, gebruikt u topic config log.cleaner.min.compaction.lag.ms . records worden pas na deze periode gecomprimeerd. de instelling geeft consumenten tijd om elk record te krijgen.
log compaction review
wat zijn drie manieren waarop kafka records kan verwijderen?
kafka kan oudere records verwijderen op basis van de tijd of grootte van een log. kafka ondersteunt ook log verdichting voor record key verdichting.
waarvoor is logverdichting goed?
aangezien log compaction de laatst bekende waarde behoudt, is het een volledige snapshot van de laatste records.het is nuttig om de toestand te herstellen na een crash of systeemstoring voor een in-memory service, een permanente dataopslag of het opnieuw laden van een cache. het stelt downstream consumenten in staat om hun staat te herstellen.
Wat is de structuur van een verdicht log? beschrijf de structuur.
met een verdicht log, heeft het log kop en staart. de kop van de verdichte log is identiek aan een traditionele Kafka log. nieuwe records worden toegevoegd aan het einde van het hoofd. alle log verdichting werkt aan de staart van de verdichte log.
veranderen de offsets van logrecords na verdichting? geen.
Wat is een partitiesegment?
herinneren dat een onderwerp een log heeft. een topic log is opgedeeld in partities en partities zijn verdeeld in segmentbestanden die records bevatten die sleutels en waarden hebben. segmentbestanden zorgen voor verdeel en heers als het gaat om log verdichting. een segmentbestand maakt deel uit van de partitie. als de log cleaner reinigt log partitie segmenten, de segmenten worden geruild in de log partitie onmiddellijk vervangen van de oudere segment bestanden. op deze manier compactie vereist niet het dubbele van de ruimte van de gehele partitie als extra benodigde schijfruimte is slechts een extra log partitie segment.
jean-paul azar werkt bij cloudurable . cloudurable biedt kafka training, Kafka consulting, Kafka ondersteuning en helpt bij het opzetten van Kafka clusters in aws .