começamos observando a regressão linear/ridge de forma dupla, antes de mostrar como ‘kernelizá-la’. Ao explicar este último, veremos o que são kernels e qual é o’ truque do kernel’.
regressão de crista de forma dupla
a regressão Linear é normalmente dada em sua forma primária como uma combinação linear de colunas (características). No entanto, existe uma segunda forma dupla, onde é uma combinação linear do produto interno de um novo dado (no qual estamos realizando inferência) com cada um dos dados de treinamento.
consideramos o caso da regressão ridge (regressão linear regularizada L2), lembrando que a regressão linear básica corresponde ao caso em que \(\lambda = 0\). Em seguida, as fórmulas para regressão ridge, onde \(X\) e \(Y\) se referem aos dados de treinamento \(n \times m\) E \(X^\prime,y^\prime\) um novo caso a ser estimado, são:
\ \ \ \
Onde \(\langle X_i,x^\prime \rangle\) é a interna/produto escalar, então \(\langle X_i,x^\prime \rangle = X^T_i x^\prime = \sum_j^m X_{i,j} x^\prime_j\).
A forma dupla mostra que a linear/ridge regressão também pode ser entendida como o fornecimento de uma estimativa de uma soma ponderada do produto interno de um novo caso com cada um dos casos de treinamento.
Isso significa que podemos fazer a regressão linear, mesmo quando há mais colunas do que linhas, embora a importância deste pode ser exagerada, pois (i) nós podemos fazer isso de qualquer forma através da utilização de L2 regularização uma vez que este sempre faz o \(X^TX\) matriz invertível; e (ii) a \(XX^T\) matriz muitas vezes pode exigir L2 regularização de qualquer forma, para garantir a estabilidade numérica para a inversão. Ele também nos permite ver a regressão linear como muito mais de um processo de aprendizagem sequencial, onde cada dado adicional nos dados de treinamento traz algo novo.
o mais importante para nossos propósitos, no entanto, a forma dupla tem a característica interessante: os vetores de características ocorrem nas equações apenas dentro de produtos internos. Isso é verdade mesmo na definição de \ (\alpha\), pois \(XX^T\) produz a matriz correspondente aos produtos internos de cada par de vetores de recursos nos dados de treinamento. Veremos a importância disso à medida que avançamos.
à parte: os alunos interessados podem ver como a forma dupla foi derivada na derivação do documento de forma Dupla disponível na seção downloads no final deste artigo.
Não-Linear de Dupla Ridge Regressão
podemos transformar a nossa forma dupla regressão ridge em um modelo não-linear pelo método padrão de utilização de um não-lineares apresentam transformações \(\phi\):
\ \
Funções de Kernel
Uma função de kernel, \(K: \mathcal X \times \mathcal X \to \mathbb{R}\), é uma função que é simétrica \(K(x_1,x_2)=K(x_2,x_1)\) e positiva definida (consulte o lado para uma definição formal). A definição positiva é usada na matemática que justifica o uso de kernels. Mas sem conhecimento matemático significativo, a definição não é intuitivamente esclarecedora. Então, em vez de tentar entender kernels a partir da definição de definição positiva, vamos apresentá-los com uma série de exemplos.
antes de fazer isso, notamos que, embora os kernels sejam funções de dois argumentos, é comum pensar neles como estando localizados em seu primeiro argumento e sendo uma função de seu segundo. De acordo com esta interpretação, você verá notação como \(K_x(y)\), que é equivalente a \(K(x, y)\) . Em particular, muitas vezes pensaremos que os kernels são funções de argumento único ‘localizadas’ em pontos de dados (vetores de recursos) em nossos dados de treinamento. Às vezes você vai ler de nós ‘soltando’ kernels em pontos de dados. Portanto, se tivermos um vetor de recurso \(x_i\), soltaríamos um kernel nele,levando à função \(K_{x_i}(x)\) localizada em \(x_i\) e equivalente a \(K(x_i, x)\).
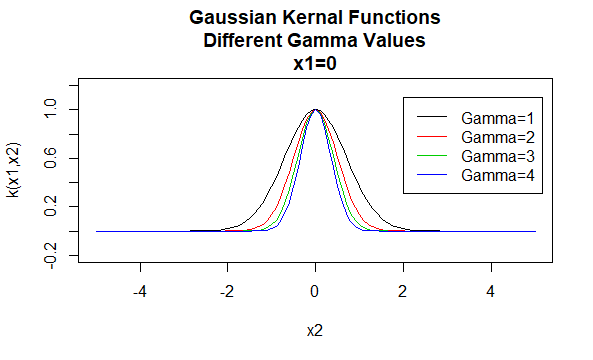
também notamos que os kernels são frequentemente especificados como membros de famílias paramétricas. Exemplos de tais famílias de kernel incluem:Os kernels Gaussianos são um exemplo de kernels de função de base radial e às vezes são chamados de kernels de base radial. O valor de um kernel de função de base radial depende apenas da distância entre os vetores de argumento, em vez de sua localização. Esses grãos também são denominados estacionários.
Parâmetros: \(\gamma\)
formato de Equação: \(K(X_1,X_2)=e^{-\gamma \| X_1 – X_2 \|^2}\)
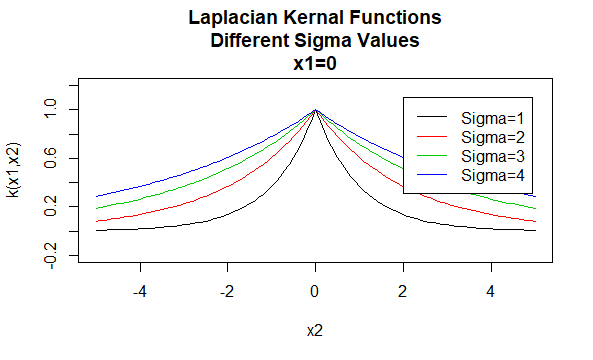
Laplaciano Kernels
Laplaciano kernels também são radial base em funções.
parâmetros:\(\sigma\)
forma da equação: \(K(X_1,X_2)=e^{-\frac{\| X_1 – X_2 \|}{\sigma}}\)
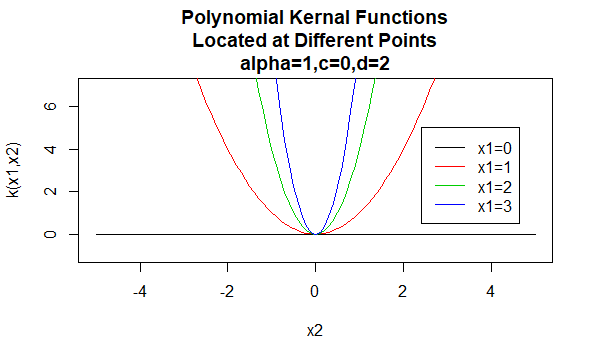
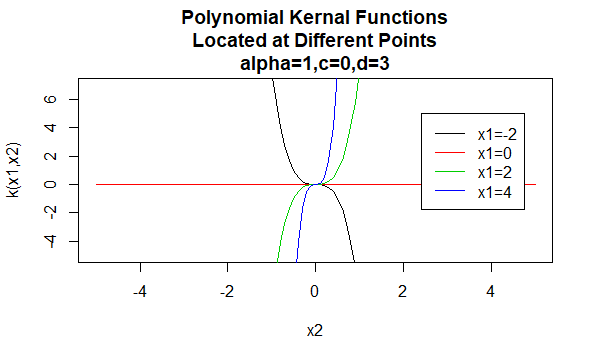
Kernels Polinomiais
kernels Polinomiais são um exemplo de não-estacionária kernels. Portanto, esses kernels atribuirão valores diferentes a pares de pontos que compartilham a mesma distância, com base em seus valores. Os valores dos parâmetros devem ser não negativos para garantir que esses kernels sejam definidos positivamente.
Parâmetros: \(\alpha , c , d\)
formato de Equação: \(K(X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
Especificar determinados valores para os parâmetros do kernel família resulta em uma função de kernel. Abaixo estão exemplos de funções de kernels das famílias acima com valores de parâmetro específicos localizados em pontos diferentes (ou seja, o gráfico plotado é uma função do segundo argumento, com o primeiro argumento definido como um valor específico).
Além: Os alunos interessados podem ver a definição de definição positiva para kernels nos Kernels e documento de definição positiva disponível na seção downloads no final deste artigo.
o truque do Kernel
a importância das funções do kernel vem de uma propriedade muito especial: Cada positiva-definida kernel, \(K\) está relacionada a uma matemática do espaço, \(\mathcal{H}_K\), (conhecido como o reproducing kernel espaço de Hilbert (RKHS) do kernel) tais que a aplicação de \(K\) para o recurso de dois vetores, \(X_1,X_2\) é equivalente a projetar estes apresentam vetores em \(\mathcal{H}_K\), por uma função de projeção, \(\phi\) e tomando o seu produto interno lá:
\
O RKHSs associados a grãos são normalmente de alto-dimensional. Para alguns grãos, como grãos da família Gaussiana, eles são infinitos dimensionais.
acima é a base para o famoso ‘kernel trick’: Se a entrada de recursos envolvidos na equação de um modelo estatístico apenas na forma de interiores e de produtos, em seguida, podemos substituir o interior-produtos na equação com chamadas para a função de kernel e o resultado é como se tivéssemos projetada a entrada de recursos em um maior espaço dimensional (i.e. realizaram um recurso de transformação, levando a um grande número de variável latente recursos) e tomado o seu interior-produto lá. Mas nunca precisamos realizar a projeção real.
na terminologia de aprendizado de máquina, o RKHS associado ao kernel é conhecido como espaço de recurso, em oposição ao espaço de entrada. Por meio do truque do kernel, projetamos implicitamente os recursos de entrada nesse espaço de recursos e levamos seu produto interno para lá.
regressão do Kernel
isso leva à técnica conhecida como regressão do kernel. É simplesmente uma aplicação do truque do kernel para a forma dupla de regressão do cume. Para facilitar, introduzimos a ideia do Kernel, ou Gram, matrix, \(K\), de tal forma que \(K_{i,j}=k(X_i,X_j)\). Então podemos escrever as equações para regressão do kernel como:
\ \
onde \(k\) é alguma função de kernel positiva definida.
O Representer Teorema
Considere o problema de otimização procuramos resolver quando da execução de L2 regularização de um modelo de alguma forma, \(f\):
\
Ao executar o kernel de regressão com o kernel \(k\), é um importante resultado da regularização teoria de que o minimizer da equação acima será da forma:
\
Com \(\alpha\) calculado conforme descrito acima.
este é o Teorema do repressor justamente lionizado. Em palavras, diz que o minimizador do problema de otimização para regressão linear no espaço de recurso implícito obtido por um kernel específico (e, portanto, o minimizador do problema de regressão do kernel não linear) será dado por uma soma ponderada de kernels ‘localizados’ em cada vetor de recurso.
há muito mais a dizer sobre este tópico. Podemos até descobrir qual função verde (da qual os kernels são um subconjunto) minimizará especificações particulares de regularização, como a regularização L2, mas também qualquer penalidade baseada em um operador diferencial linear. Essa relação entre kernels e soluções ideais para os problemas de regularização de Tikhonov é uma razão fundamental para a importância dos métodos do kernel no aprendizado de máquina. Mas a matemática aqui está além deste curso, e estudantes avançados interessados são referidos ao capítulo sete das redes neurais e máquinas de aprendizagem de Haykin.
isso nos dá uma justificativa matemática para o uso da regressão do kernel nos casos em que é possível fazê-lo. Na verdade, trabalhar o kernel ideal para usar normalmente não é possível – requer o conhecimento do operador diferencial linear ideal para usar para a penalidade de regularização. As funções que devemos projetar para otimizar penalidades de regularização específicas foram calculadas e sabemos, por exemplo, que o kernel de spline de placa fina é ideal para regularização L2. No lado negativo, como precisamos calcular a matriz Gram, a regressão do kernel não escala bem – para grandes conjuntos de dados que se voltam para redes neurais é uma ideia melhor.