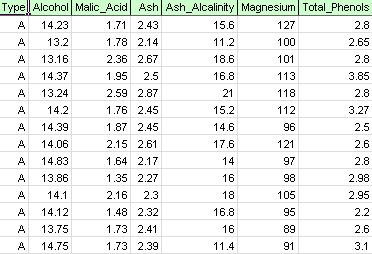
na faixa de Opções XLMiner, na guia aplicando seu modelo, selecione Help-Examples, depois exemplos de previsão / mineração de dados e abra o arquivo de exemplo Wine.xlsx. Conforme mostrado na figura abaixo, cada linha neste conjunto de dados de exemplo representa uma amostra de vinho retirada de uma das três vinícolas (A, B ou C). Neste exemplo, a variável de tipo que representa a vinícola é ignorada e o agrupamento é realizado simplesmente com base nas propriedades das amostras de vinho (as variáveis restantes).
Selecione uma célula dentro do conjunto de dados e, em seguida, no XLMiner faixa de opções, a partir da Análise de Dados guia, selecione XLMiner – Cluster k-means Clustering para abrir o k-means Clustering Passo 1 de 3 de diálogo.
na lista de variáveis, Selecione Todas as variáveis, exceto o tipo, e clique no botão > para mover as variáveis selecionadas para a lista de variáveis selecionadas.
clique em Avançar para a Etapa 2 de 3 diálogo.
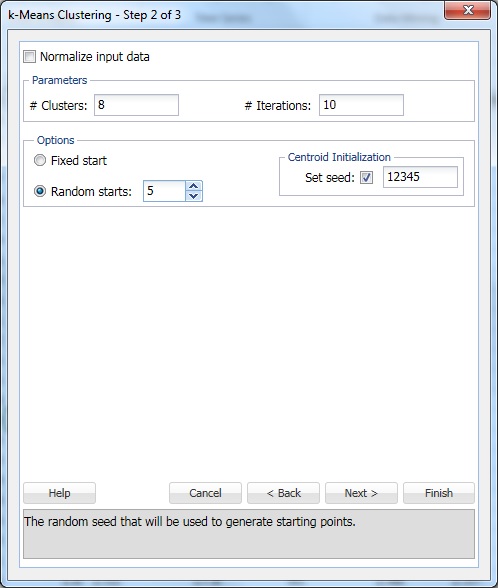
em # Clusters, digite 8. Este é o parâmetro k no algoritmo de agrupamento k-means. O número de clusters deve ser pelo menos 1 e, no máximo, o número de observações -1 no intervalo de dados. Defina k para vários valores diferentes e avalie a saída de cada um.
deixe # iterações na configuração padrão de 10. O valor para esta opção determina quantas vezes o programa começará com uma partição inicial e completará o algoritmo de agrupamento. A configuração de clusters (e separação de dados) pode diferir de uma partição inicial para outra. O programa passará pelo número especificado de iterações e selecionará a configuração do cluster que minimiza a medida de distância.
definir Aleatório começa a 5. Quando esta opção é selecionada, o algoritmo começa a construir o modelo a partir de qualquer ponto aleatório. XLMiner gera cinco conjuntos de cluster e gera a saída com base no melhor cluster.
set seed é selecionado por padrão. Esta opção inicializa o gerador de números aleatórios que é usado para calcular OS centróides iniciais do cluster. Definir a semente de número aleatório para um valor diferente de zero (padrão 12345) garante que a mesma sequência de números aleatórios seja usada cada vez que os centróides iniciais do cluster são calculados. Quando a semente é zero, o gerador de números aleatórios é inicializado a partir do relógio do sistema, de modo que a sequência de números aleatórios é diferente cada vez que os centróides são inicializados. Defina a semente para ver as execuções sucessivas do método de agrupamento como comparáveis.
selecione a opção normalizar dados de entrada para normalizar os dados. Neste exemplo, os dados não serão normalizados. Selecione ao lado para abrir a caixa de diálogo Etapa 3 de 3.
selecione Mostrar resumo de dados (padrão) e mostrar distâncias de cada centro de cluster (padrão) e clique em Concluir.
o método de Clustering k-Means começa com K clusters iniciais conforme especificado. Em cada iteração, os registros são atribuídos ao cluster com o centroid mais próximo, ou centro. Após cada iteração, a distância de cada registro para o centro do cluster é calculada. Essas duas etapas são repetidas (a atribuição do registro e o cálculo da distância) até que a redistribuição de um registro resulte em um valor de distância aumentado.
quando um início aleatório é especificado, o algoritmo gera os centros de cluster K aleatoriamente e se encaixa nos pontos de dados nesses clusters. Este processo é repetido para todos os começos aleatórios especificados. A saída é baseada nos clusters que exibem o melhor ajuste.
a planilha KM_Output1 é inserida imediatamente à direita da planilha de dados. Na seção superior da planilha de saída, as opções selecionadas são listadas.
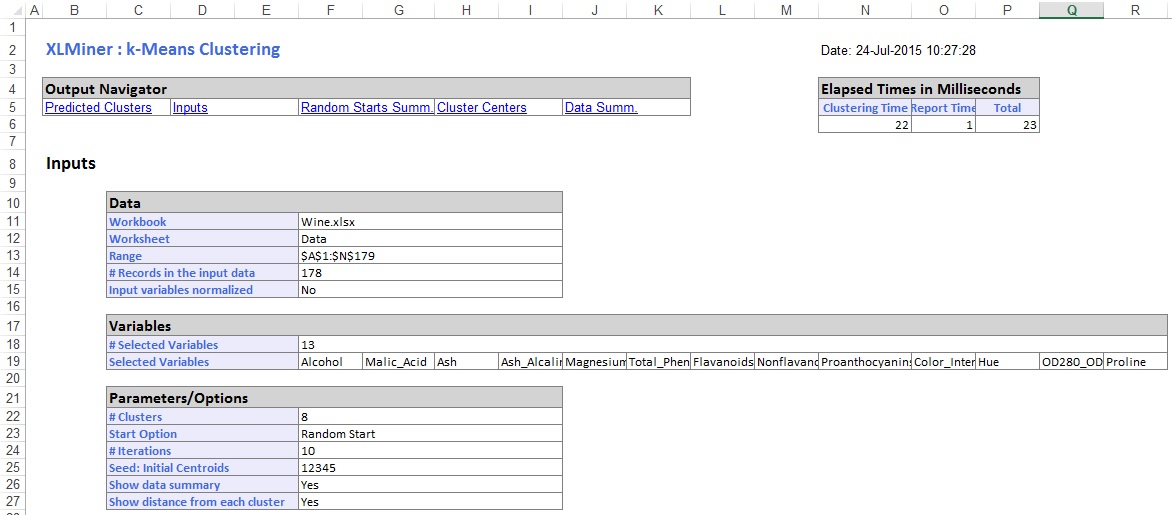
na seção intermediária da planilha de saída, XLMiner calculou a soma das distâncias quadradas e determinou o início com a menor soma de distância quadrada como o melhor Início (#5). Depois que o melhor começo é determinado, XLMiner gera a saída restante usando o melhor começo como o ponto de partida.
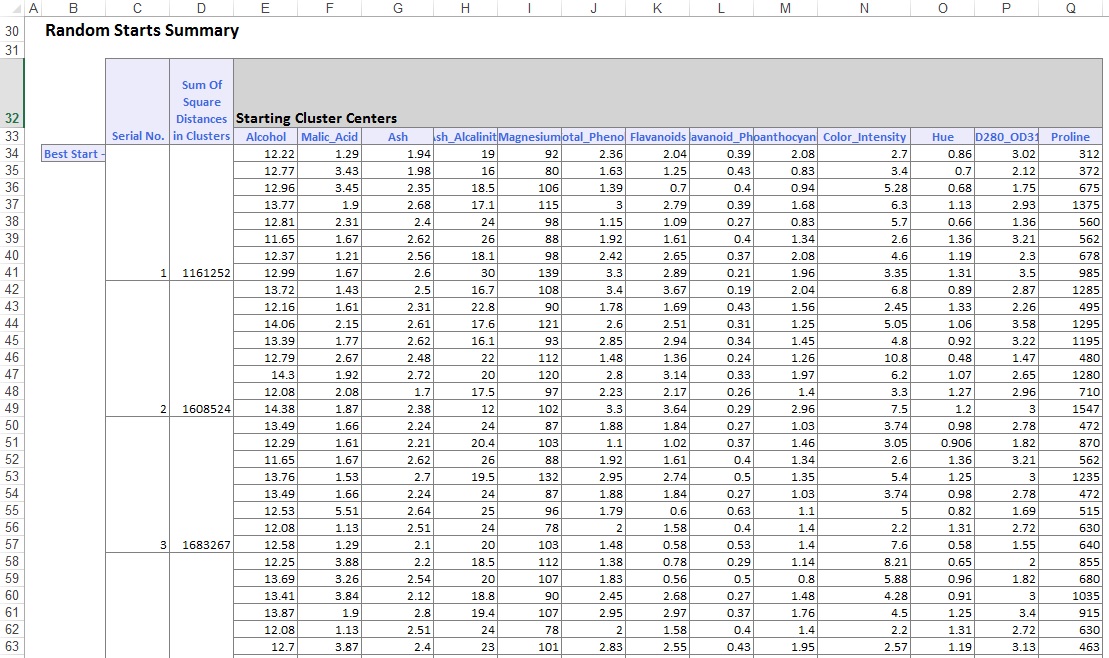
na parte inferior da planilha de saída, XLMiner listou os Centros de Cluster (mostrados abaixo). A caixa superior mostra os valores variáveis nos centros de Cluster. O Cluster 8 tem o maior teor médio de álcool, Total_fenóis, Flavanóides, Proantocianinas, Color_Intensity, Hue e prolina. Compare este cluster com o Cluster 2, que tem a maior média de Ash_Alcalinity e Nonflavanoid_Phenols.
a caixa inferior mostra a distância entre os Centros de Cluster. A partir dos valores desta tabela, é determinado que o Cluster 3 é muito diferente do Cluster 8 devido ao valor de alta distância de 1.176, 59, e o Cluster 7 está próximo do Cluster 3 com um valor de baixa distância de 89,73.
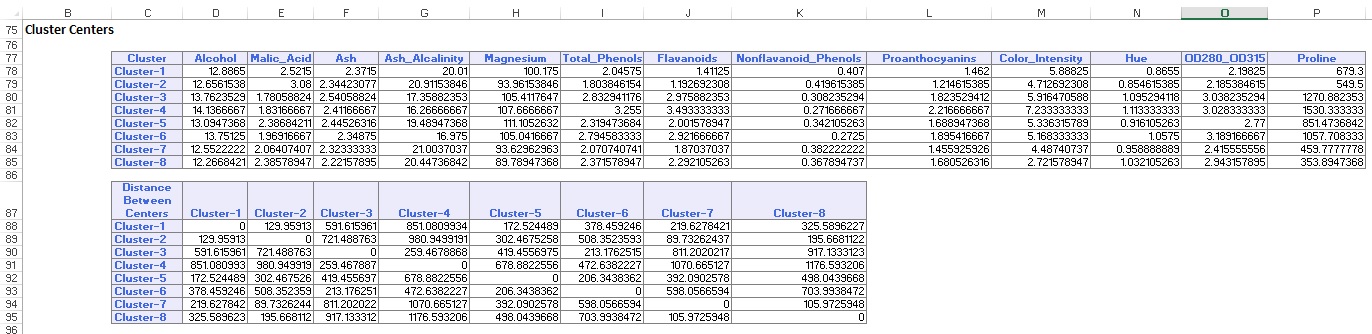
o resumo de dados (abaixo) exibe o número de registros (observações) incluídos em cada cluster e a distância média dos membros do cluster ao centro de cada cluster. O Cluster 6 tem a maior distância média de 42,79 e inclui 24 registros. Compare este cluster com o Cluster 2, que tem a menor distância média de 29,66 e inclui 26 membros.
clique na planilha KM_Clusters1. Esta planilha exibe o cluster ao qual cada registro é atribuído e a distância para cada um dos clusters. Para o primeiro registro, a distância para o Cluster 6 é a distância mínima de 23.205, portanto, esse primeiro registro é atribuído ao Cluster 6.