Imagine ter uma ferramenta que pode detectar automaticamente JPA e Hibernate problemas de desempenho. Hypersistence Optimizer é essa ferramenta!
- Introdução
- Por Que E quando JDBC foi criado
- Por que e quando o Hibernate foi criado
- Por Que E quando o JPA foi criado?Aprendendo com o sucesso do projeto Hibernate, a plataforma Java EE decidiu padronizar a maneira como Hibernate e Oracle TopLink, e foi assim que JPA (Java Persistence API) nasceu.
- as vantagens e desvantagens de usar JPA e Hibernate
- a comunidade geral e as integrações populares
- alternativas JPA
- Oficinas On-line
- Conclusão
Introdução
se você está Se perguntando por que e quando você deve usar JPA ou Hibernate, então este artigo vai dar-lhe uma resposta para esta pergunta muito comum. Como vi essa pergunta feita com muita frequência no canal / R / Java Reddit, decidi que vale a pena escrever uma resposta aprofundada sobre os pontos fortes e fracos do JPA e do Hibernate.
embora o JPA tenha sido um padrão desde que foi lançado pela primeira vez em 2006, não é a única maneira de implementar uma camada de acesso a dados usando Java. Vamos discutir as vantagens e desvantagens de usar o JPA ou quaisquer outras alternativas populares.
Por Que E quando JDBC foi criado
em 1997, Java 1.1 introduziu a API JDBC (Java Database Connectivity), que foi muito revolucionária para a época, pois oferecia a possibilidade de escrever a camada de acesso a dados uma vez usando um conjunto de interfaces e executá-la em qualquer banco de dados relacional que implementa a API JDBC sem a necessidade de alterar o código do aplicativo.
a API JDBC ofereceu uma interface Connection para controlar os limites da transação e criar instruções SQL simples por meio da API Statement ou instruções preparadas que permitem vincular valores de parâmetro por meio da API PreparedStatement.
Assim, supondo que temos um post tabela de banco de dados e queremos inserir 100 linhas, veja como podemos atingir esse objetivo com JDBC:
int postCount = 100;int batchSize = 50;try (PreparedStatement postStatement = connection.prepareStatement(""" INSERT INTO post ( id, title ) VALUES ( ?, ? ) """)) { for (int i = 1; i <= postCount; i++) { if (i % batchSize == 0) { postStatement.executeBatch(); } int index = 0; postStatement.setLong( ++index, i ); postStatement.setString( ++index, String.format( "High-Performance Java Persistence, review no. %1$d", i ) ); postStatement.addBatch(); } postStatement.executeBatch();} catch (SQLException e) { fail(e.getMessage());}
Enquanto tiramos vantagem de ser multi-linha de Blocos de Texto e tentar-com-recursos de blocos para eliminar o PreparedStatement close chamada, a implementação ainda é muito detalhado. Observe que os parâmetros bind começam em 1, não 0, como você pode estar acostumado a outras APIs conhecidas.
para buscar as primeiras 10 linhas, poderíamos precisar executar uma consulta SQL por meio do PreparedStatement, que retornará um ResultSet representando o resultado da consulta baseada em tabela. No entanto, desde o uso de aplicativos de estruturas hierárquicas, como JSON ou DTOs para representar pai-filho associações, a maioria das aplicações necessárias para transformar o JDBC ResultSet para um formato diferente na camada de acesso a dados, como ilustrado pelo seguinte exemplo:
int maxResults = 10;List<Post> posts = new ArrayList<>();try (PreparedStatement preparedStatement = connection.prepareStatement(""" SELECT p.id AS id, p.title AS title FROM post p ORDER BY p.id LIMIT ? """)) { preparedStatement.setInt(1, maxResults); try (ResultSet resultSet = preparedStatement.executeQuery()) { while (resultSet.next()) { int index = 0; posts.add( new Post() .setId(resultSet.getLong(++index)) .setTitle(resultSet.getString(++index)) ); } }} catch (SQLException e) { fail(e.getMessage());}
Novamente, esse é o melhor jeito de escrever esta com JDBC como estamos usando Blocos de Texto, tentar-com-recursos, e um Fluente em estilo API para criar o Post objetos.
no entanto, a API JDBC ainda é muito detalhada e, mais importante, carece de muitos recursos necessários ao implementar uma camada moderna de acesso a dados, como:
- uma maneira de buscar objetos diretamente do conjunto de resultados da consulta. Como vimos no exemplo acima, precisamos iterar o
ReusltSete extrair os valores da coluna para definir as propriedades do objetoPost. - uma maneira transparente de instruções em lote sem ter que reescrever o código de acesso a dados ao alternar do modo padrão sem lotes para o uso de lotes.
- suporte para bloqueio otimista
- Uma paginação API que esconde o banco de dados subjacente-Superior específico-N e da Próxima consulta de N sintaxe
Por que e quando o Hibernate foi criado
Em 1999, a Sun lançou J2EE (Java Enterprise Edition), que oferecia uma alternativa para JDBC, chamado de Entity Beans.
no entanto, como os Beans de entidade eram notoriamente lentos, supercomplicados e complicados de usar, em 2001, Gavin King decidiu criar uma estrutura ORM que pudesse mapear tabelas de banco de dados para POJOs (objetos Java antigos simples), e foi assim que o Hibernate nasceu.
sendo mais leve do que Entity Beans e menos detalhado do que JDBC, o Hibernate cresceu cada vez mais popular, e logo se tornou o framework de persistência Java mais popular, conquistando JDO, iBatis, Oracle TopLink e Apache Cayenne.
Por Que E quando o JPA foi criado?Aprendendo com o sucesso do projeto Hibernate, a plataforma Java EE decidiu padronizar a maneira como Hibernate e Oracle TopLink, e foi assim que JPA (Java Persistence API) nasceu.
JPA é apenas uma especificação e não pode ser usado por conta própria, fornecendo apenas um conjunto de interfaces que definem a API de persistência padrão, que é implementada por um provedor JPA, como Hibernate, EclipseLink ou OpenJPA.
Quando utilizar o APP, você precisa definir o mapeamento entre uma tabela de banco de dados e os seus associados Java entidade objeto:
@Entity@Table(name = "post")public class Post { @Id private Long id; private String title; public Long getId() { return id; } public Post setId(Long id) { this.id = id; return this; } public String getTitle() { return title; } public Post setTitle(String title) { this.title = title; return this; }}
Depois, podemos reescrever o exemplo anterior que salvou 100 post registros parecido com este:
for (long i = 1; i <= postCount; i++) { entityManager.persist( new Post() .setId(i) .setTitle( String.format( "High-Performance Java Persistence, review no. %1$d", i ) ) );}
Para habilitar o JDBC lote insere, só temos para oferecer uma única propriedade de configuração:
<property name="hibernate.jdbc.batch_size" value="50"/>
uma vez que esta propriedade é fornecida, Hibernate pode alternar automaticamente de não-lotes para lotes sem a necessidade de qualquer alteração de código de acesso de dados.
e, para buscar as primeiras 10 post linhas, podemos executar a seguinte consulta JPQL:
int maxResults = 10;List<Post> posts = entityManager.createQuery(""" select p from post p order by p.id """, Post.class).setMaxResults(maxResults).getResultList();
se você comparar isso com a versão JDBC, verá que o JPA é muito mais fácil de usar.
as vantagens e desvantagens de usar JPA e Hibernate
JPA, em geral, e Hibernate, em particular, oferecem muitas vantagens.
- você pode buscar entidades ou DTOs. Você pode até buscar projeção Dto hierárquica pai-filho.
- você pode habilitar o processamento em lotes JDBC sem alterar o código de acesso a dados.
- você tem suporte para bloqueio otimista.
- você tem uma abstração de bloqueio pessimista que é independente da sintaxe específica do banco de dados subjacente para que você possa adquirir um bloqueio de leitura e gravação ou até mesmo um bloqueio de salto.
- você tem uma API de paginação independente de banco de dados.
- você pode fornecer um
Listde valores para uma cláusula in query, conforme explicado neste artigo. - você pode usar uma solução de cache fortemente consistente que permite descarregar o nó primário, que, para transações de rea-write, só pode ser chamado verticalmente.
- você tem suporte embutido para registro de Auditoria via Envers Hibernate.
- você tem suporte embutido para multitenancy.
- você pode gerar um script de esquema inicial a partir dos mapeamentos de entidade usando a ferramenta Hibernate hbm2ddl, que você pode fornecer a uma ferramenta de migração automática de esquema, como Flyway.
- não só que você tem a liberdade de executar qualquer consulta SQL nativa, mas você pode usar o SqlResultSetMapping para transformar o JDBC
ResultSetpara entidades JPA ou DTOs.
as desvantagens de usar JPA e Hibernate são as seguintes:
- embora começar com o JPA seja muito fácil, torne-se um especialista requer um investimento significativo de tempo porque, além de ler seu manual, você ainda precisa aprender como funcionam os sistemas de banco de dados, o padrão SQL e o sabor SQL específico usado pelo banco de dados de relacionamento do projeto.
- existem alguns comportamentos menos intuitivos que podem surpreender os iniciantes, como a ordem de operação flush.
- a API de critérios é bastante detalhada, então você precisa usar uma ferramenta como o Codota para escrever consultas dinâmicas com mais facilidade.
a comunidade geral e as integrações populares
JPA e Hibernate são extremamente populares. De acordo com o relatório do ecossistema Java de 2018 da Snyk, o Hibernate é usado por 54% de todos os desenvolvedores Java que interagem com um banco de dados relacional.
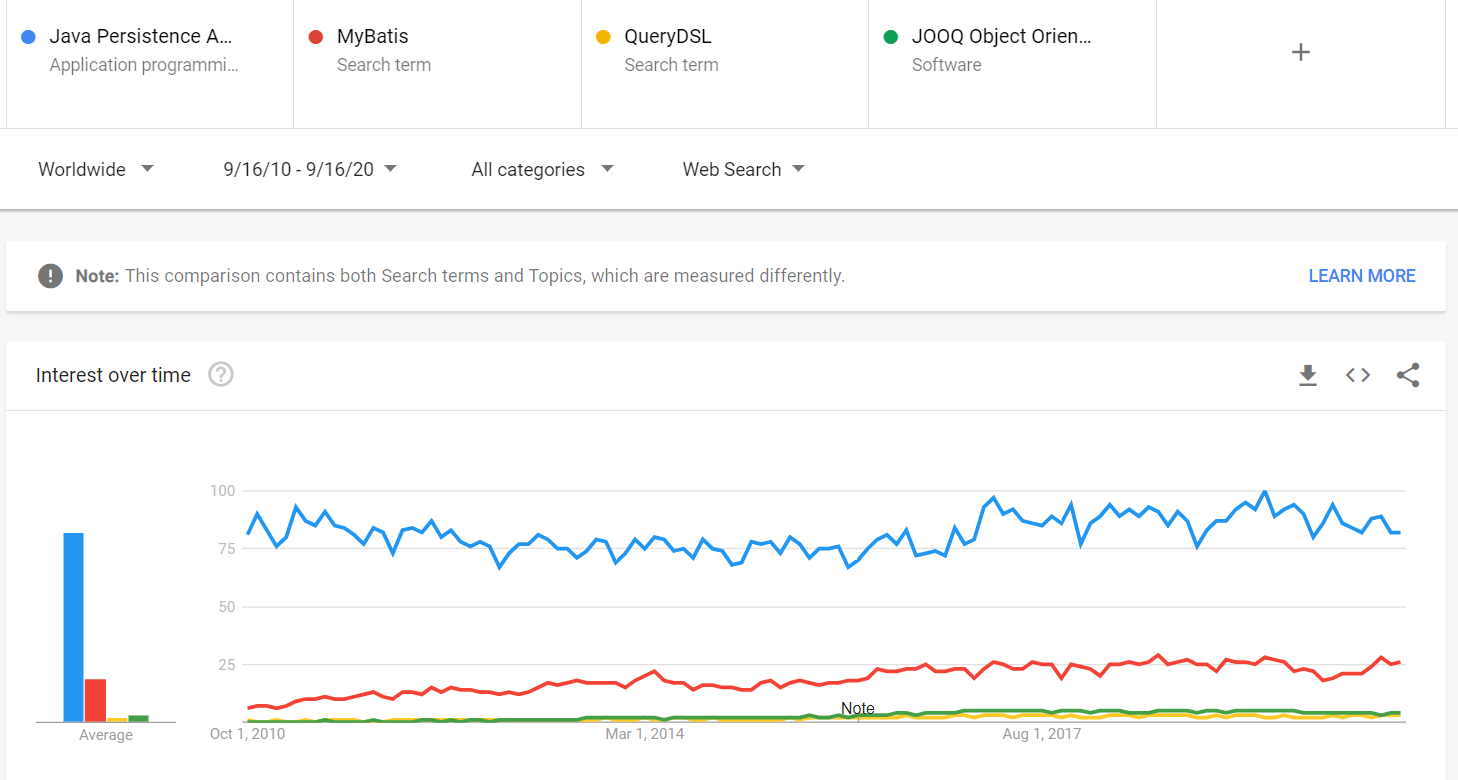
este resultado pode ser apoiado pelo Google Trends. Por exemplo, se compararmos o Google Tendências da JPA sobre os seus principais concorrentes (por exemplo, MyBatis, QueryDSL, e jOOQ), podemos ver que o JPA é muitas vezes mais popular e não mostra sinais de perder a sua posição de mercado dominante.

Ser tão popular traz muitos benefícios, como:
- O Spring Data JPA integração funciona como um encanto. Na verdade, uma das maiores razões pelas quais o JPA e o Hibernate são tão populares é porque o Spring Boot usa o Spring Data JPA, que, por sua vez, usa o Hibernate nos bastidores.
- se você tiver algum problema, há uma boa chance de que essas respostas stackoverflow relacionadas ao Hibernate de 30k e Respostas stackoverflow relacionadas ao JPA de 16K forneçam uma solução.
- existem tutoriais do Hibernate 73K disponíveis. Somente meu site oferece mais de 250 tutoriais JPA e Hibernate que ensinam como aproveitar ao máximo o JPA e o Hibernate.
- existem muitos cursos de vídeo que você também pode usar, como meu curso de vídeo Java Persistence de alto desempenho.
- existem mais de 300 livros sobre o Hibernate na Amazon, um dos quais é meu livro de persistência Java de alto desempenho também.
alternativas JPA
uma das maiores coisas sobre o ecossistema Java é a abundância de estruturas de alta qualidade. Se o JPA e o Hibernate não forem adequados para o seu caso de uso, você poderá usar qualquer uma das seguintes estruturas:
- MyBatis, que é um framework SQL query mapper muito leve.
- QueryDSL, que permite criar consultas SQL, JPA, Lucene e MongoDB dinamicamente.
- jOOQ, que fornece um metamodelo Java para as tabelas subjacentes, procedimentos armazenados e funções e permite que você construa uma consulta SQL dinamicamente usando um DSL muito intuitivo e de maneira segura.
portanto, use o que funcionar melhor para você.
Oficinas On-line
Se você gostou deste artigo, eu aposto que você vai amar o meu próximo de 4 dias x 4 horas de Alta Performance em Java Persistence Online Workshop

Conclusão
neste artigo, vimos por que JPA foi criada e quando você deve usá-lo. Embora o JPA traga muitas vantagens, você tem muitas outras alternativas de alta qualidade para usar se o JPA e o Hibernate não funcionarem melhor para os requisitos atuais do aplicativo.
e, às vezes, como expliquei nesta amostra grátis do meu livro de persistência Java de alto desempenho, você nem precisa escolher entre JPA ou outros frameworks. Você pode facilmente combinar JPA com uma estrutura como jOOQ para obter o melhor dos dois mundos.



