începem prin a analiza regresia liniară/creastă cu formă dublă, înainte de a arăta cum să o ‘kernelize’. În explicarea acestuia din urmă, vom vedea ce sunt nucleele și care este trucul kernel-ului.
regresia creastei cu formă duală
regresia liniară este de obicei dată în ea formă primară ca o combinație liniară de coloane (caracteristici). Cu toate acestea, există o a doua formă duală în care este o combinație liniară a produsului interior al unui nou datum (pe care efectuăm inferența) cu fiecare dintre datele de antrenament.
considerăm cazul regresiei creastei (L2 regresie liniară regularizată), amintindu-ne că regresia liniară de bază corespunde cazului în care \(\lambda = 0\). Apoi formulele pentru regresia creastei, unde \(X\) și \(Y\) se referă la datele de antrenament \ (n \ times m\) și \(X^\prime,y^\prime\) un nou caz care trebuie estimat, sunt:
\ \ \ \
unde \ (\langle x_i, X^ \ prime \ rangle\) este produsul interior/punct, deci \(\langle X_i,x^\prime \rangle = X^T_i X^\prime = \sum_j^m x_{i,j} x^\prime_j\).
forma duală arată că regresia liniară/creastă poate fi înțeleasă și ca oferind o estimare a unei sume ponderate a produsului interior al unui caz nou cu fiecare dintre cazurile de antrenament.
înseamnă că putem face regresie liniară chiar și atunci când există mai multe coloane decât rânduri, deși importanța acestui lucru poate fi supraevaluată, deoarece (i) putem face acest lucru oricum prin utilizarea regularizării L2, deoarece aceasta face întotdeauna matricea \(X^TX\) inversabilă; și (ii) Matricea \(XX^T\) poate necesita adesea regularizarea L2 oricum pentru a asigura stabilitatea numerică pentru inversiune. De asemenea, ne permite să vedem regresia liniară ca fiind mult mai mult un proces de învățare secvențial, în care fiecare datum suplimentar din datele de antrenament aduce ceva nou.
cel mai important pentru scopurile noastre, totuși, forma duală are caracteristica interesantă: vectorii de caracteristici apar în ecuații numai în interiorul produselor interioare. Acest lucru este valabil chiar și în definiția \(\alpha\), deoarece \(XX^T\) produce matricea corespunzătoare produselor interioare ale fiecărei perechi de vectori de caracteristici din datele de antrenament. Vom vedea importanța acestui lucru pe măsură ce vom continua.
deoparte: studenții interesați pot vedea cum a fost derivată forma duală în derivarea documentului cu formă duală Disponibil în secțiunea Descărcări de la sfârșitul acestui articol.
non-Linear Dual Ridge regresie
putem transforma regresia noastră dublă formă creastă într-un model non-linear prin metoda standard de a folosi o caracteristică neliniară transformări \(\phi\):
\ \
funcții Kernel
o funcție kernel, \(K: \mathcal x \times \mathcal X \to \mathbb{R}\), este o funcție care este simetrică – \(K(x_1,x_2)=K(x_2,x_1)\) – și pozitiv definit (a se vedea deoparte pentru o definiție formală). Pozitiv-definitivitatea este folosită în matematică care justifică utilizarea nucleelor. Dar fără cunoștințe matematice semnificative, definiția nu este intuitivă. Deci, mai degrabă decât să încercăm să înțelegem nucleele din definiția definiției pozitive, le vom introduce cu o serie de exemple.
înainte de a face acest lucru, observăm că, deși nucleele sunt funcții cu două argumente, este obișnuit să ne gândim la ele ca fiind localizate la primul lor argument și fiind o funcție a celui de-al doilea. Conform acestei interpretări veți vedea notații precum \(K_x(y)\), care este echivalent cu \(K (x,y)\) . În special, ne vom gândi adesea că nucleele sunt funcții cu un singur argument ‘localizate’ la punctele de date (vectori de caracteristici) din datele noastre de antrenament. Uneori, veți citi de noi’ dropping ‘ kernel pe puncte de date. Deci, dacă avem un vector de caracteristică \(x_i\) , am arunca un kernel pe el, ducând la funcția \(k_{x_i} (x)\) situată la \(x_i\) și echivalentă cu \(K (x_i,x)\) .
de asemenea, observăm că nucleele sunt adesea specificate ca membri ai familiilor parametrice. Exemple de astfel de familii de kernel includ:
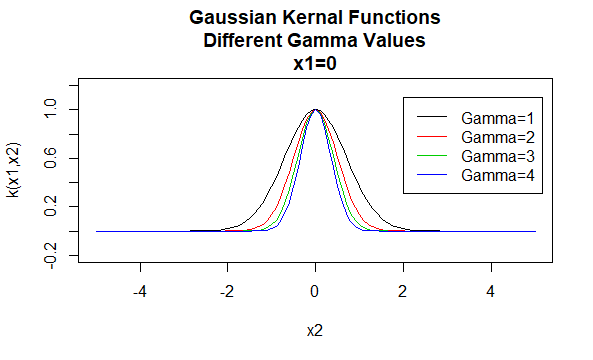
miezuri gaussiene
miezuri gaussiene sunt un exemplu de miezuri de funcții de bază radială și sunt uneori numite miezuri de bază radiale. Valoarea unui nucleu radial funcție de bază depinde numai de distanța dintre vectorii argument, mai degrabă decât locația lor. Astfel de sâmburi sunt, de asemenea, denumite staționare.
parametri: \(\gamma\)
forma ecuației: \(K (X_1, X_2) = e ^ {- \gamma | / X_1-X_2 \|^2}\)
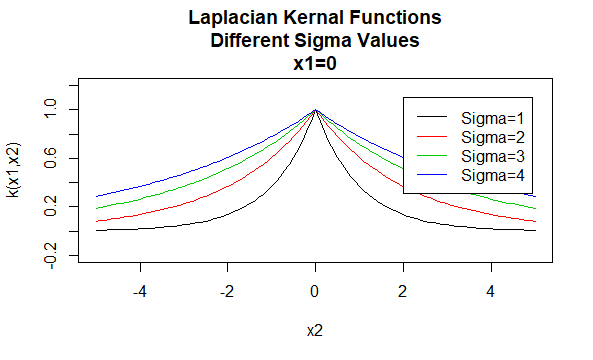
nucleele Laplaciene
nucleele Laplaciene sunt, de asemenea, funcții de bază radiale.
parametri:\(\sigma\)
forma ecuației: \(K (X_1, X_2) = e^{-\frac{\| X_1 – X_2 \|}{\sigma}}\)
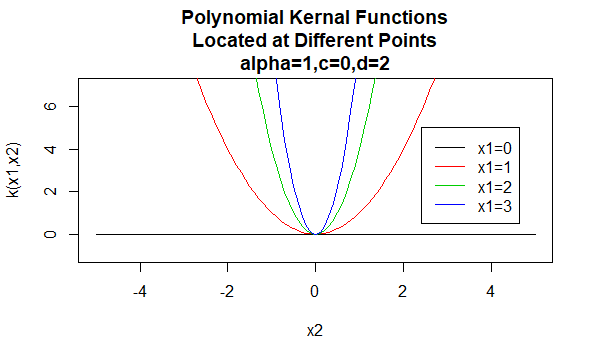
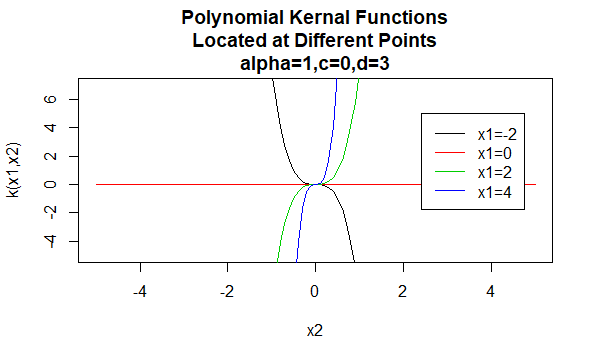
nucleele polinomiale
nucleele polinomiale sunt un exemplu de nucleele non-staționare. Deci, aceste nuclee vor atribui valori diferite perechilor de puncte care împărtășesc aceeași distanță, pe baza valorilor lor. Valorile parametrilor trebuie să fie non-negative pentru a se asigura că aceste nuclee sunt pozitive definite.
parametri: \(\alpha , C , d\)
forma ecuației: \(K(X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
specificarea unor valori particulare pentru parametrii unei familii de kernel are ca rezultat o funcție de kernel. Mai jos sunt exemple de funcții kernel din familiile de mai sus cu valori particulare ale parametrilor situate în diferite puncte (adică graficul grafic este o funcție a celui de-al doilea argument, cu primul argument setat la o valoare specifică).
Deoparte: Studenții interesați pot vedea definiția definiției pozitive pentru kernel-uri în documentul Kernels and Positive Definiteness Disponibil în secțiunea Descărcări de la sfârșitul acestui articol.
trucul Kernel-ului
importanța funcțiilor kernel-ului provine dintr-o proprietate foarte specială: Fiecare nucleu pozitiv definit, \(K\) este legat de un spațiu matematic, \(\mathcal{H}_K\), (cunoscut sub numele de spațiul Hilbert de reproducere a nucleului (RKHS) al nucleului) astfel încât aplicarea \(K\ ) la doi vectori de caracteristici, \(X_1, X_2\) este echivalentă cu proiectarea acestor vectori de caracteristici în \(\mathcal{H}_K\) de către o funcție de proiecție, \(\phi\):
\
RKHSs asociate cu nucleele sunt de obicei de înaltă Dimensiune. Pentru unele kerneluri, cum ar fi kernelurile familiei gaussiene, acestea sunt infinit dimensionale.
cele de mai sus stau la baza celebrului truc al nucleului: dacă elementele de intrare sunt implicate în ecuația unui model statistic doar sub formă de produse interioare, atunci putem înlocui produsele interioare din ecuație cu apeluri către funcția nucleului și rezultatul este ca și cum am fi proiectat caracteristicile de intrare într-un spațiu dimensional superior (adică am efectuat o transformare a caracteristicilor care duce la un număr mare de caracteristici variabile latente) și le-am luat produsul interior acolo. Dar niciodată nu trebuie să realizăm proiecția reală.
în terminologia de învățare automată, RKHS asociate cu nucleul este cunoscut sub numele de spațiu de caracteristici, spre deosebire de spațiul de intrare. Prin trucul kernel-ului proiectăm implicit caracteristicile de intrare în acest spațiu de caracteristici și le ducem produsul interior acolo.
regresia nucleului
aceasta duce la tehnica cunoscută sub numele de regresia nucleului. Este pur și simplu o aplicație a trucului kernel-ului la forma duală de regresie a creastei. Pentru ușurință introducem ideea de nucleu, sau Gram, matrice, \(K\), astfel încât \(k_{i,j}=k(X_i, X_j)\). Apoi putem scrie ecuațiile pentru regresia kernel-ului ca:
\ \
unde \(k\) este o funcție de kernel definită pozitiv.
Teorema Representer
luați în considerare problema de optimizare pe care încercăm să o rezolvăm atunci când efectuăm regularizarea L2 pentru un model de o anumită formă, \(f\):
\
la efectuarea regresiei kernel-ului cu kernel \(k\), este un rezultat important al teoriei regularizării că minimizatorul ecuației de mai sus va avea forma:
\
cu\ (\alpha\) calculat conform descrierii de mai sus.
aceasta este teorema Representatorului pe bună dreptate lionizată. În cuvinte, se spune că minimizatorul problemei de optimizare pentru regresia liniară în spațiul implicit al caracteristicilor obținut de un anumit kernel (și, prin urmare, minimizatorul problemei de regresie neliniară a kernel-ului) va fi dat de o sumă ponderată de kerneluri ‘localizate’ la fiecare vector de caracteristică.
mai sunt multe de spus despre acest subiect. Putem chiar să ne dăm seama ce funcție verde (din care nucleele sunt un subset) va minimiza anumite specificații de regularizare, cum ar fi regularizarea L2, dar și orice penalizare bazată pe un operator diferențial liniar. Această relație între kernel-uri și soluții optime la problemele de regularizare Tikhonov este un motiv principal pentru importanța metodelor kernel-ului în învățarea automată. Dar matematica de aici este dincolo de acest curs, iar studenții avansați interesați sunt menționați la capitolul șapte din rețelele neuronale și mașinile de învățare ale lui Haykin.
aceasta ne oferă o justificare matematică pentru utilizarea regresiei nucleului în cazurile în care este posibil să facem acest lucru. De fapt, elaborarea nucleului optim de utilizat nu este de obicei posibilă – necesită cunoașterea operatorului diferențial liniar optim de utilizat pentru pedeapsa de regularizare. Funcțiile pe care ar trebui să le proiectăm pentru a optimiza anumite sancțiuni de regularizare au fost calculate și știm, de exemplu, că kernelul spline cu placă subțire este optim pentru regularizarea L2. În partea de jos, deoarece trebuie să calculăm matricea Gram, regresia nucleului nu se scalează bine – pentru seturi de date mari, întoarcerea la rețelele neuronale este o idee mai bună.