în panglica XLMiner, din fila aplicarea modelului, selectați Help – Examples, apoi Forecasting/Data Mining Examples și deschideți fișierul exemplu Wine.XlX. După cum se arată în figura de mai jos, fiecare rând din acest exemplu de set de date reprezintă un eșantion de vin prelevat de la una dintre cele trei fabrici de vin (A, B sau C). În acest exemplu, variabila de tip reprezentând Vinăria este ignorată, iar gruparea se realizează pur și simplu pe baza proprietăților probelor de vin (variabilele rămase).
Selectați o celulă din setul de date, apoi pe panglica XLMiner, din fila Analiză date, selectați Xlminer – Cluster – k-Means Clustering pentru a deschide dialogul K-Means Clustering Step 1 of 3.
din lista variabile, Selectați toate variabilele, cu excepția tipului, apoi faceți clic pe butonul > pentru a muta variabilele selectate în lista variabile selectate.
Faceți clic pe Următorul pentru a avansa la Pasul 2 din 3 dialog.
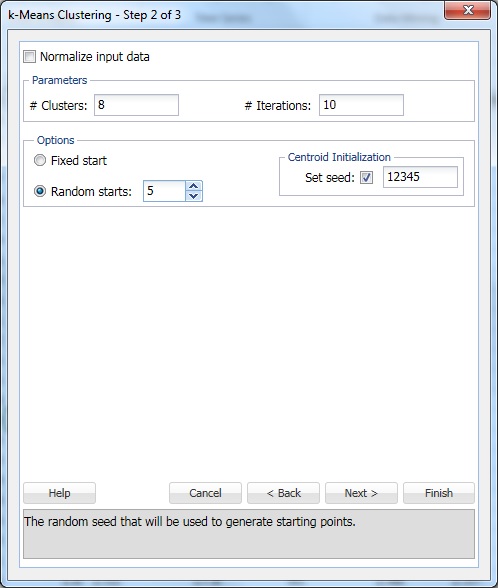
la # clustere, introduceți 8. Acesta este parametrul k din algoritmul de clustering k-means. Numărul de clustere ar trebui să fie de cel puțin 1 și cel mult numărul de observații -1 în intervalul de date. Setați k la mai multe valori diferite și evaluați ieșirea din fiecare.
lăsați #iterații la setarea implicită de 10. Valoarea pentru această opțiune determină de câte ori programul va începe cu o partiție inițială și va completa algoritmul de grupare. Configurația clusterelor (și separarea datelor) poate diferi de la o partiție de pornire la alta. Programul va trece prin numărul specificat de iterații și va selecta configurația clusterului care minimizează măsura distanței.
Set aleatoare începe la 5. Când este selectată această opțiune, algoritmul începe să construiască modelul din orice punct aleatoriu. XLMiner generează cinci seturi de cluster și generează ieșirea bazată pe cel mai bun cluster.
Set seed este selectat în mod implicit. Această opțiune inițializează generatorul de numere aleatorii care este utilizat pentru a calcula centroizii inițiali ai Clusterului. Setarea semințelor de numere aleatorii la o valoare diferită de zero (implicit 12345) asigură utilizarea aceleiași secvențe de numere aleatorii de fiecare dată când se calculează centroizii inițiali ai Clusterului. Când sămânța este zero, generatorul de numere aleatorii este inițializat din ceasul sistemului, astfel încât secvența numerelor aleatorii este diferită de fiecare dată când centroizii sunt inițializați. Setați sămânța pentru a vizualiza rulările succesive ale metodei de grupare ca fiind comparabile.
selectați opțiunea normalizare date de intrare pentru a normaliza datele. În acest exemplu, datele nu vor fi normalizate. Selectați Următorul pentru a deschide dialogul Pasul 3 din 3.
selectați Afișare rezumat date (implicit) și afișare distanțe de la fiecare centru de cluster (implicit), apoi faceți clic pe Finalizare.
K-înseamnă Clustering metoda începe cu K clustere inițiale așa cum este specificat. La fiecare iterație, înregistrările sunt atribuite clusterului cu cel mai apropiat centroid sau centru. După fiecare iterație, se calculează distanța de la fiecare înregistrare la Centrul clusterului. Acești doi pași se repetă (atribuirea înregistrării și calculul distanței) până când redistribuirea unei înregistrări are ca rezultat o valoare crescută a distanței.
când este specificat un start aleatoriu, algoritmul generează centrele clusterului k aleatoriu și se potrivește punctelor de date din acele clustere. Acest proces se repetă pentru toate pornirile aleatorii specificate. Rezultatul se bazează pe clusterele care prezintă cea mai bună potrivire.
foaia de lucru KM_Output1 este inserată imediat în dreapta foii de lucru Date. În secțiunea de sus a foii de lucru de ieșire, sunt listate opțiunile selectate.
în secțiunea de mijloc a foii de lucru de ieșire, XLMiner a calculat suma distanțelor pătrate și a determinat începutul cu cea mai mică sumă a distanței pătrate ca cel mai bun început (#5). După ce se determină cel mai bun început, XLMiner generează ieșirea rămasă folosind cel mai bun început ca punct de plecare.
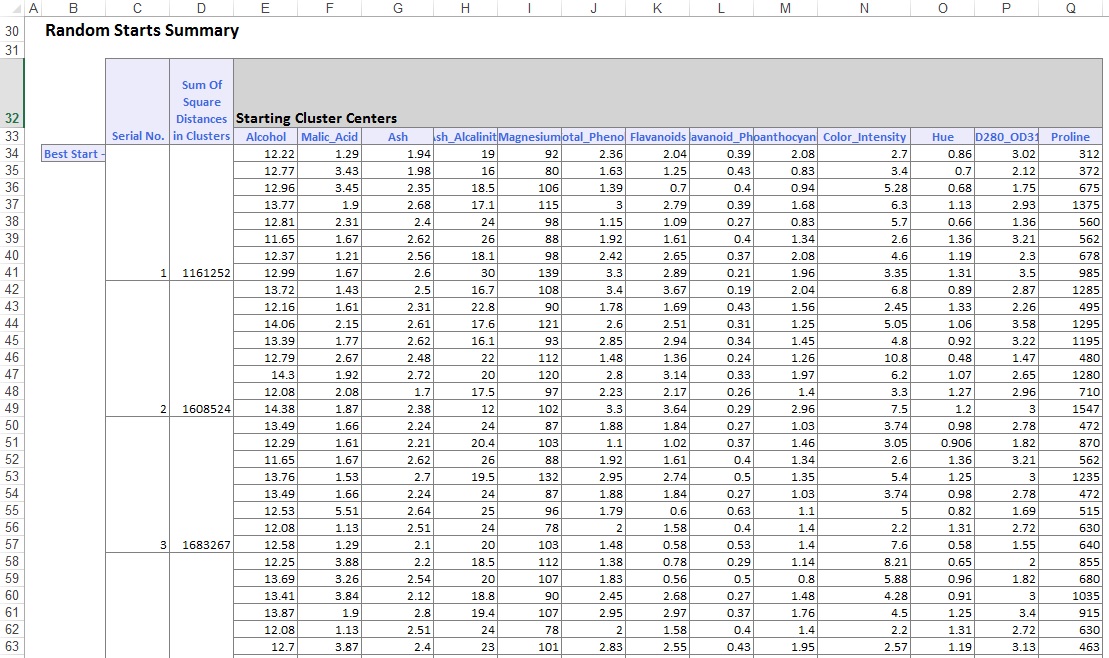
în partea de jos a foii de lucru de ieșire, XLMiner a enumerat centrele de Cluster (prezentate mai jos). Caseta superioară arată valorile variabile la centrele clusterului. Clusterul 8 are cel mai mare conținut mediu de alcool, Total_fenoli, flavanoizi, Proantocianine, Color_Intensity, nuanță și prolină. Comparați acest cluster cu Cluster 2, care are cea mai mare medie Ash_Alcalinity și Nonflavanoid_Phenols.
caseta inferioară arată distanța dintre centrele clusterului. Din valorile din acest tabel, se determină că clusterul 3 este foarte diferit de Clusterul 8 datorită valorii distanței mari de 1.176, 59, iar Clusterul 7 este aproape de Clusterul 3 cu o valoare a distanței mici de 89,73.
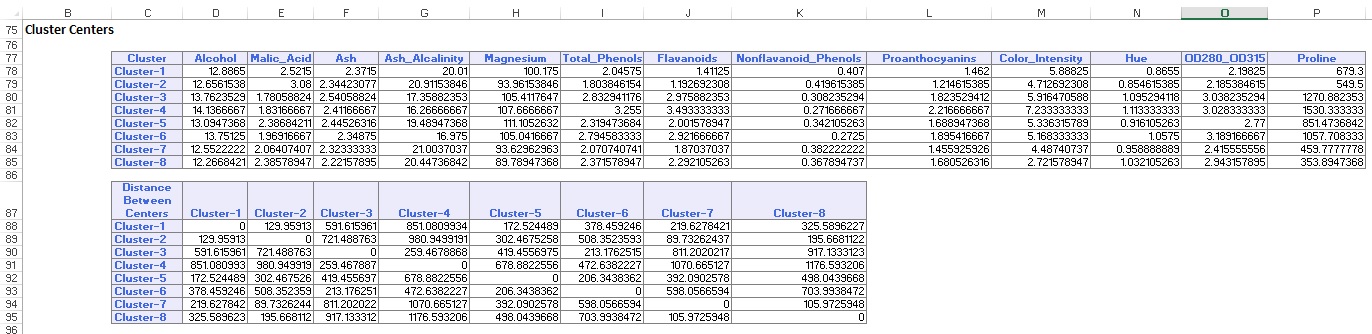
Rezumatul datelor (de mai jos) afișează numărul de înregistrări (observații) incluse în fiecare cluster și distanța medie de la membrii clusterului la centrul fiecărui cluster. Clusterul 6 are cea mai mare distanță medie de 42,79 și include 24 de înregistrări. Comparați acest cluster cu Cluster 2, care are cea mai mică distanță medie de 29,66 și include 26 de membri.
Faceți clic pe foaia de lucru KM_Clusters1. Această foaie de lucru afișează clusterul căruia i se atribuie fiecare înregistrare și distanța față de fiecare dintre clustere. Pentru prima înregistrare, Distanța până la clusterul 6 este distanța minimă de 23.205, deci această primă înregistrare este atribuită clusterului 6.