Imaginați-vă că aveți un instrument care poate detecta automat JPA și hibernează problemele de performanță. Hypersistance Optimizer este acel instrument!
Introducere
dacă vă întrebați De ce și când ar trebui să utilizați JPA sau Hibernate, atunci acest articol vă va oferi un răspuns la această întrebare foarte frecventă. Pentru că am văzut această întrebare adresată foarte des pe canalul /r/java Reddit, am decis că merită să scriu un răspuns aprofundat despre punctele forte și punctele slabe ale JPA și Hibernate.
deși JPA a fost un standard de când a fost lansat pentru prima dată în 2006, nu este singurul mod în care puteți implementa un strat de acces la date folosind Java. Vom discuta despre avantajele și dezavantajele utilizării JPA sau a oricăror alte alternative populare.
de ce și când a fost creat JDBC
în 1997, Java 1.1 a introdus API-ul JDBC (Java Database Connectivity), care a fost foarte revoluționar pentru timpul său, deoarece oferea posibilitatea de a scrie stratul de acces la date Odată folosind un set de interfețe și de a-l rula pe orice bază de date relațională care implementează API-ul JDBC fără a fi nevoie să schimbați codul aplicației.
API-ul JDBC a oferit o interfață Connection pentru a controla limitele tranzacției și pentru a crea instrucțiuni SQL simple prin API-ul Statement sau declarații pregătite care vă permit să legați valorile parametrilor prin API-ul PreparedStatement.
deci, presupunând că avem un tabel de baze de date post și dorim să inserăm 100 de rânduri, iată cum am putea atinge acest obiectiv cu JDBC:
int postCount = 100;int batchSize = 50;try (PreparedStatement postStatement = connection.prepareStatement(""" INSERT INTO post ( id, title ) VALUES ( ?, ? ) """)) { for (int i = 1; i <= postCount; i++) { if (i % batchSize == 0) { postStatement.executeBatch(); } int index = 0; postStatement.setLong( ++index, i ); postStatement.setString( ++index, String.format( "High-Performance Java Persistence, review no. %1$d", i ) ); postStatement.addBatch(); } postStatement.executeBatch();} catch (SQLException e) { fail(e.getMessage());}
în timp ce am profitat de blocuri de Text cu mai multe linii și blocuri de încercare cu resurse pentru a elimina apelul PreparedStatement close, implementarea este încă foarte detaliată. Rețineți că parametrii de legare încep de la 1, nu 0 așa cum ați putea fi obișnuiți cu alte API-uri cunoscute.
pentru a prelua primele 10 rânduri, am putea avea nevoie pentru a rula o interogare SQL prin PreparedStatement, care va returna un ResultSet reprezentând rezultatul interogării pe bază de tabel. Cu toate acestea, deoarece aplicațiile utilizează structuri ierarhice, cum ar fi JSON sau DTOs pentru a reprezenta asociațiile părinte-copil, majoritatea aplicațiilor necesare pentru a transforma JDBC ResultSet într-un format diferit în stratul de acces la date, așa cum este ilustrat de următorul exemplu:
int maxResults = 10;List<Post> posts = new ArrayList<>();try (PreparedStatement preparedStatement = connection.prepareStatement(""" SELECT p.id AS id, p.title AS title FROM post p ORDER BY p.id LIMIT ? """)) { preparedStatement.setInt(1, maxResults); try (ResultSet resultSet = preparedStatement.executeQuery()) { while (resultSet.next()) { int index = 0; posts.add( new Post() .setId(resultSet.getLong(++index)) .setTitle(resultSet.getString(++index)) ); } }} catch (SQLException e) { fail(e.getMessage());}
din nou, acesta este cel mai frumos mod în care am putea scrie acest lucru cu JDBC, deoarece folosim blocuri de Text, încercați cu resurse și un API în stil Fluent pentru a construi obiectele Post.
cu toate acestea, API-ul JDBC este încă foarte detaliat și, mai important, nu are multe caracteristici care sunt necesare atunci când se implementează un strat modern de acces la date, cum ar fi:
- o modalitate de a prelua obiecte direct din setul de rezultate de interogare. După cum am văzut în exemplul de mai sus, trebuie să iterăm
ReusltSetși să extragem valorile coloanei pentru a seta proprietățile obiectuluiPost. - un mod transparent pentru declarațiile de lot fără a fi nevoie să rescrieți codul de acces la date atunci când treceți de la modul implicit fără dozare la utilizarea dozării.
- suport pentru blocarea optimistă
- un API de paginare care ascunde sintaxa de interogare Top-N și Next-n specifică bazei de date
de ce și când Hibernate a fost creat
în 1999, Sun a lansat J2EE (Java Enterprise Edition), care a oferit o alternativă la JDBC, numită fasole entitate.
cu toate acestea, din moment ce fasolea entității era notoriu lentă, prea complicată și greoaie de utilizat, în 2001, Gavin King a decis să creeze un cadru ORM care să poată mapa tabelele bazei de date la POJOs (obiecte Java vechi simple) și așa s-a născut Hibernate.
fiind mai ușor decât fasolea entității și mai puțin verbose decât JDBC, Hibernate a devenit din ce în ce mai popular și a devenit în curând cel mai popular cadru de persistență Java, câștigând JDO, iBatis, Oracle TopLink și Apache Cayenne.
de ce și când a fost creat app?
învățând din succesul proiectului Hibernate, platforma Java EE a decis să standardizeze modul Hibernate și Oracle TopLink și așa s-a născut JPA (Java Persistence API).
JPA este doar o specificație și nu poate fi utilizată singură, oferind doar un set de interfețe care definesc API-ul standard de persistență, care este implementat de un furnizor JPA, cum ar fi Hibernate, EclipseLink sau OpenJPA.
când utilizați JPA, trebuie să definiți maparea între un tabel de baze de date și obiectul asociat entității Java:
@Entity@Table(name = "post")public class Post { @Id private Long id; private String title; public Long getId() { return id; } public Post setId(Long id) { this.id = id; return this; } public String getTitle() { return title; } public Post setTitle(String title) { this.title = title; return this; }}
după aceea, putem rescrie exemplul anterior care a salvat 100 post înregistrări arată astfel:
for (long i = 1; i <= postCount; i++) { entityManager.persist( new Post() .setId(i) .setTitle( String.format( "High-Performance Java Persistence, review no. %1$d", i ) ) );}
pentru a activa inserțiile de lot JDBC, trebuie doar să oferim o singură proprietate de configurare:
<property name="hibernate.jdbc.batch_size" value="50"/>
odată ce această proprietate este furnizată, Hibernate poate trece automat de la non-dozare la dozare fără a fi nevoie de nicio modificare a codului de acces la date.
și, pentru a prelua primele 10 post rânduri, putem executa următoarea interogare JPQL:
int maxResults = 10;List<Post> posts = entityManager.createQuery(""" select p from post p order by p.id """, Post.class).setMaxResults(maxResults).getResultList();
dacă comparați acest lucru cu versiunea JDBC, veți vedea că JPA este mult mai ușor de utilizat.
avantajele și dezavantajele utilizării JPA și Hibernate
JPA, în general, și Hibernate, în special, oferă multe avantaje.
- puteți prelua entități sau DTOs. Puteți chiar să preluați proiecția ierarhică părinte-copil DTO.
- puteți activa dozarea JDBC fără a modifica codul de acces la date.
- aveți suport pentru blocarea optimistă.
- aveți o abstracție de blocare pesimistă care este independentă de sintaxa specifică bazei de date, astfel încât să puteți achiziționa o blocare de citire și scriere sau chiar o blocare de omitere.
- aveți un API de paginare independent de baza de date.
- puteți furniza o
Listde valori la o clauză de interogare în, așa cum este explicat în acest articol. - puteți utiliza o soluție de cache puternic consistentă care vă permite să descărcați nodul primar, care, pentru tranzacțiile rea-write, poate fi apelat doar pe verticală.
- aveți suport încorporat pentru înregistrarea în jurnal a auditului prin Hibernate Envers.
- aveți suport încorporat pentru multitenancy.
- puteți genera un script schemă inițială din mapările entității utilizând instrumentul Hibernate hbm2ddl, pe care îl puteți furniza unui instrument de migrare automată a schemei, cum ar fi Flyway.
- nu numai că aveți libertatea de a executa orice interogare SQL nativ, dar puteți utiliza SqlResultSetMapping pentru a transforma JDBC
ResultSetla entități JPA sau DTOs.
dezavantajele utilizării JPA și Hibernate sunt următoarele:
- în timp ce începeți cu JPA este foarte ușor, deveniți un expert necesită o investiție semnificativă de timp, deoarece, pe lângă citirea manualului său, mai trebuie să învățați cum funcționează sistemele de baze de date, standardul SQL, precum și aroma specifică SQL utilizată de baza de date de relații de proiect.
- există unele comportamente mai puțin intuitive care ar putea surprinde începătorii, cum ar fi ordinea de funcționare a spălării.
- API-ul criteriilor este destul de detaliat, deci trebuie să utilizați un instrument precum Codota pentru a scrie mai ușor interogări dinamice.
comunitatea generală și integrările populare
JPA și Hibernate sunt extrem de populare. Conform raportului ecosistemului Java din 2018 realizat de Snyk, Hibernate este utilizat de 54% din fiecare dezvoltator Java care interacționează cu o bază de date relațională.
acest rezultat poate fi susținut de Google Trends. De exemplu, dacă comparăm tendințele Google ale JPA cu principalii săi concurenți (de exemplu, MyBatis, QueryDSL și jOOQ), putem vedea că JPA este de multe ori mai popular și nu prezintă semne de pierdere a poziției sale dominante pe cota de piață.

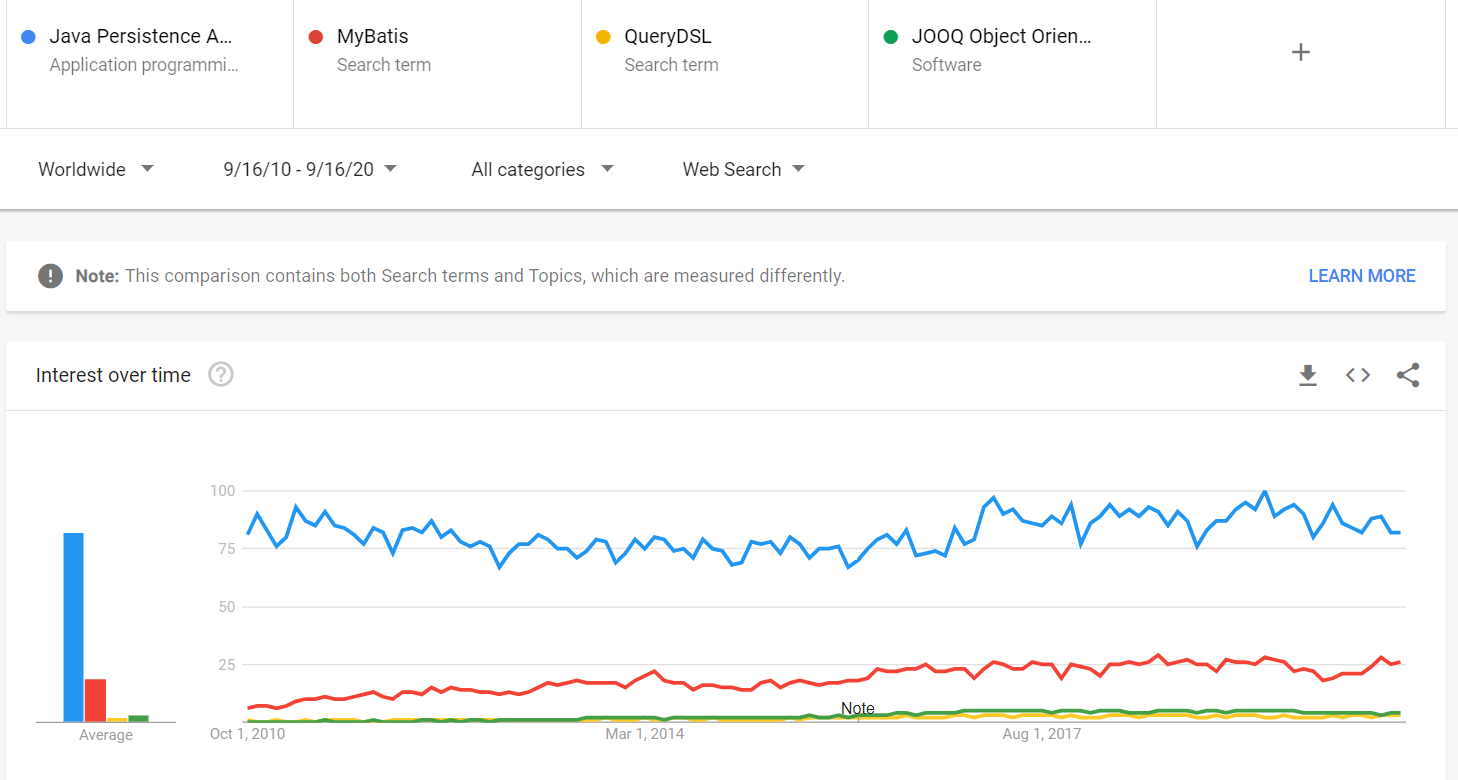
fiind atât de popular aduce multe beneficii, cum ar fi:
- integrarea Spring Data JPA funcționează ca un farmec. De fapt, unul dintre cele mai mari motive pentru care JPA și Hibernate sunt atât de populare este că Spring Boot folosește Spring Data JPA, care, la rândul său, folosește Hibernate în culise.
- dacă aveți vreo problemă, există șanse mari ca aceste răspunsuri StackOverflow legate de hibernare 30K și răspunsurile StackOverflow legate de JPA 16k să vă ofere o soluție.
- există tutoriale 73K Hibernate disponibile. Doar site-ul meu oferă peste 250 de tutoriale JPA și Hibernate care vă învață cum să profitați la maximum de JPA și Hibernate.
- există multe cursuri video pe care le puteți utiliza, de asemenea, cum ar fi cursul meu Video de persistență Java de înaltă performanță.
- există peste 300 de cărți despre Hibernate pe Amazon, dintre care una este și cartea mea de persistență Java de înaltă performanță.
alternative JPA
unul dintre cele mai mari lucruri despre ecosistemul Java este abundența cadrelor de înaltă calitate. Dacă JPA și Hibernate nu sunt potrivite pentru cazul dvs. de utilizare, puteți utiliza oricare dintre următoarele cadre:
- MyBatis, care este un cadru foarte ușor de interogare SQL mapper.
- QueryDSL, care vă permite să construiți dinamic interogări SQL, JPA, Lucene și MongoDB.
- jOOQ, care oferă un metamodel Java pentru tabelele de bază, procedurile stocate și funcțiile și vă permite să construiți o interogare SQL dinamic folosind un DSL foarte intuitiv și într-un mod sigur de tip.
deci, folosiți orice funcționează cel mai bine pentru dvs.
ateliere Online
dacă ți-a plăcut acest articol, pun pariu că îți va plăcea viitorul meu atelier online de persistență Java de 4 zile x 4 ore de înaltă performanță

concluzie
în acest articol, am văzut de ce a fost creat JPA și când ar trebui să îl utilizați. În timp ce JPA aduce multe avantaje, aveți multe alte alternative de înaltă calitate de utilizat dacă JPA și Hibernate nu funcționează cel mai bine pentru cerințele actuale ale aplicației.
și, uneori, așa cum am explicat în acest eșantion gratuit al cărții mele de persistență Java de înaltă performanță, nici măcar nu trebuie să alegeți între JPA sau alte cadre. Puteți combina cu ușurință JPA cu un cadru precum jOOQ pentru a obține cele mai bune din ambele lumi.



