Apache Spark to narzędzie do analizy danych, które może być używane do przetwarzania danych z HDFS, S3 lub innych źródeł danych w pamięci. W tym poście zainstalujemy Apache Spark na maszynie Ubuntu 17.10.
wersja Ubuntu
w tym przewodniku użyjemy wersji Ubuntu 17.10 (GNU/Linux 4.13.0-38-generic x86_64).
Apache Spark jest częścią ekosystemu Hadoop dla Big Data. Spróbuj zainstalować Apache Hadoop i stwórz z nim przykładową aplikację.
aktualizacja istniejących pakietów
aby rozpocząć instalację Dla Spark, konieczne jest zaktualizowanie naszej maszyny o najnowsze dostępne pakiety oprogramowania. Możemy to zrobić z:
ponieważ Spark jest oparty na Javie, musimy go zainstalować na naszym komputerze. Możemy użyć dowolnej wersji Javy powyżej Javy 6. Tutaj będziemy używać Javy 8:
pobieranie plików Spark
wszystkie niezbędne pakiety istnieją teraz na naszej maszynie. Jesteśmy gotowi pobrać wymagane pliki Spark TAR, abyśmy mogli zacząć je konfigurować i uruchomić przykładowy program z Spark.
w tym przewodniku zainstalujemy Spark v2. 3. 0 dostępny tutaj:

Strona pobierania Spark
Pobierz odpowiednie pliki za pomocą tego polecenia:
w zależności od szybkości sieci może to potrwać do kilku minut, ponieważ plik jest duży:
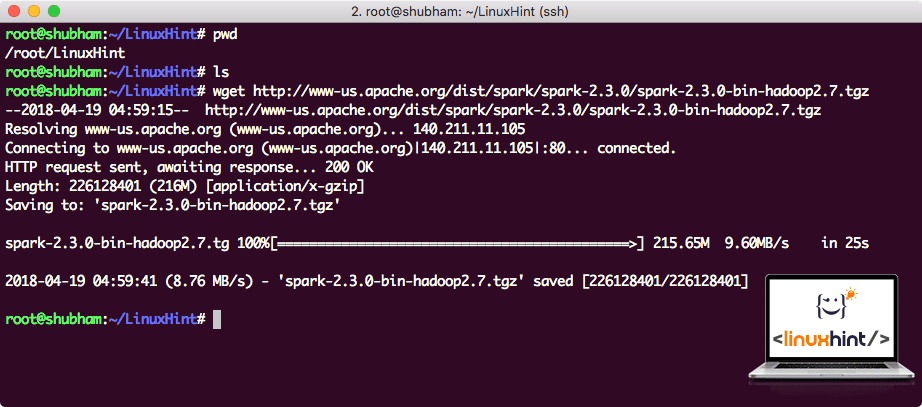
pobieranie Apache Spark
teraz, gdy mamy pobrany plik TAR, możemy wyodrębnić w bieżącym katalogu:
to zajmie kilka sekund, aby zakończyć ze względu na Duży Rozmiar pliku archiwum:

Niezarchiwane pliki w Spark
jeśli chodzi o aktualizowanie Apache Spark w przyszłości, może to powodować problemy z powodu aktualizacji ścieżek. Problemów tych można uniknąć, tworząc łącze miękkie do Spark. Uruchom to polecenie, aby utworzyć łącze miękkie:
dodawanie Spark do ścieżki
aby wykonać Skrypty Spark, dodamy go teraz do ścieżki. Aby to zrobić, otwórz plik bashrc:
dodaj te linie do końca .plik bashrc tak, że ścieżka może zawierać ścieżkę pliku wykonywalnego Spark:
export PATH = $SPARK_HOME / bin:$PATH
teraz plik wygląda następująco:

dodawanie Spark do ścieżki
aby aktywować te zmiany, uruchom następujące polecenie dla pliku bashrc:
uruchamianie powłoki Spark
teraz, gdy znajdujemy się tuż poza katalogiem spark, uruchom następujące polecenie, aby otworzyć powłokę apark:
zobaczymy, że Spark shell jest teraz openend:

uruchamianie Spark shell
w konsoli widać, że Spark również otworzył konsolę internetową na porcie 404. Odwiedźmy go.:

Apache Spark Web Console
chociaż będziemy działać na samej konsoli, środowisko internetowe jest ważnym miejscem, na które warto zwrócić uwagę podczas wykonywania ciężkich zadań Spark, aby wiedzieć, co dzieje się w każdym wykonywanym zadaniu Spark.
Sprawdź wersję powłoki Spark za pomocą prostego polecenia:
odzyskamy coś w stylu:
Tworzenie przykładowej aplikacji Spark za pomocą Scala
teraz zrobimy przykładową aplikację licznika słów za pomocą Apache Spark. Aby to zrobić, najpierw Załaduj plik tekstowy do kontekstu Spark na Spark shell:
Data: org.Apacz.spark.rdd.RDD = /root/LinuxHint/spark / README.MD MapPartitionsRDD at textFile at :24
scala>
teraz tekst znajdujący się w pliku musi zostać podzielony na tokeny, którymi Spark może zarządzać:
tokeny: org.Apacz.spark.rdd.RDD = MapPartitionsRDD at flatMap at: 25
scala>
teraz zainicjalizuj licznik dla każdego słowa na 1:
tokens_1: org.Apacz.spark.rdd.RDD = MapPartitionsRDD at map at: 25
scala>
na koniec Oblicz częstotliwość każdego słowa pliku:
czas spojrzeć na dane wyjściowe programu. Zbieraj żetony i ich liczbę:
res1: Array = Array ((Pakiet,1), (dla,3), (Programy,1), (przetwarzanie.,1), (Because,1), (The, 1), (page] (http://spark.apache.org/documentation.html)., 1), (klaster.,1), (its,1), ([run,1), (than,1), (API,1), (have,1), (Try,1), (computation,1), (through,1), (several,1), (This,2), (graph,1), (Hive,2), (storage,1), ([„Specificing,1), (To,2), („yarn”,1), (Once,1), ([„Useful,1), (prefer,1), (sparkpi,2), (engine,1), (version,1), (file,1), (documentation,,1), (processing,,1), (the,24), (are,1), (systems.,1), (params,1), (not,1), (different,1), (refer,2), (Interactive, 2), (R,, 1), (given.,1), (if,4), (build,4), (when,1), (be,2), (Tests,1), (Apache,1), (thread, 1), (programs,, 1), (including, 4), (./ bin / run-example, 2), (Spark., 1), (pakiet.,1), (1000).count (), 1), (Versions, 1), (HDFS, 1), (D…
scala>
doskonale! Udało nam się uruchomić prosty przykład licznika słów przy użyciu języka programowania Scala z plikiem tekstowym już obecnym w systemie.
podsumowanie
w tej lekcji przyjrzeliśmy się, jak możemy zainstalować i zacząć używać Apache Spark na komputerze Ubuntu 17.10 i uruchomić na nim przykładową aplikację.
Czytaj więcej postów opartych na Ubuntu tutaj.