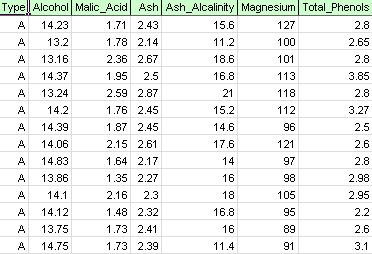
na wstążce xlminer, na karcie Zastosowanie modelu wybierz Help-Examples, a następnie Forecasting/Data Mining Examples i otwórz przykładowy plik Wine.xlsx. Jak pokazano na poniższym rysunku, każdy wiersz w tym przykładowym zestawie danych reprezentuje próbkę wina pobraną z jednej z trzech winnic (A, B lub C). W tym przykładzie zmienna typu reprezentująca winnicę jest ignorowana, a grupowanie odbywa się po prostu na podstawie właściwości próbek wina (pozostałych zmiennych).
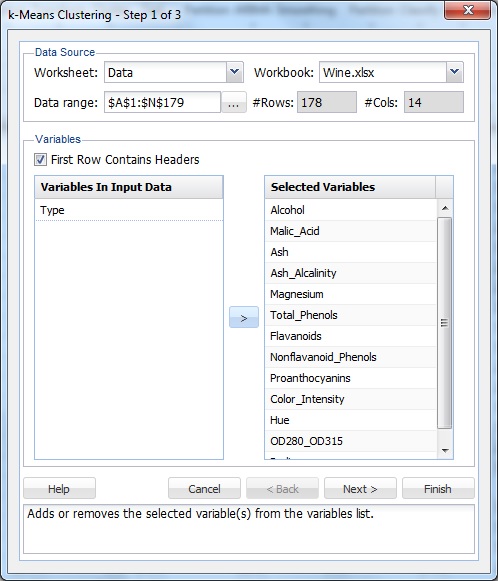
wybierz komórkę w zbiorze danych, a następnie na wstążce XLMiner na karcie Analiza Danych Wybierz XLMiner – Cluster – K-Means Clustering aby otworzyć okno dialogowe K-Means Clustering Krok 1 z 3.
z listy zmienne wybierz wszystkie zmienne oprócz typu, a następnie kliknij przycisk >, aby przenieść wybrane zmienne do listy Wybrane zmienne.
kliknij Dalej, aby przejść do kroku 2 z 3 dialogów.
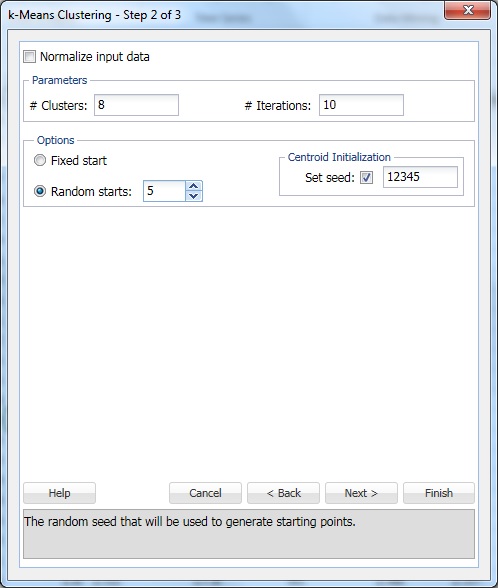
w # Clusters wpisz 8. Jest to parametr k w algorytmie grupowania k-means. Liczba klastrów powinna wynosić co najmniej 1, a co najwyżej -1 w zakresie danych. Ustaw k na kilka różnych wartości i Oblicz wynik z każdej z nich.
pozostaw iteracje #przy domyślnym ustawieniu 10. Wartość tej opcji określa, ile razy program uruchomi się z początkową partycją i ukończy algorytm klastrowania. Konfiguracja klastrów (i separacja danych) może się różnić w zależności od partycji startowej. Program przejdzie przez określoną liczbę iteracji i wybierze konfigurację klastra, która minimalizuje pomiar odległości.
Ustaw losowy początek na 5. Po wybraniu tej opcji algorytm rozpoczyna budowę modelu z dowolnego punktu losowego. XLMiner generuje pięć zestawów klastrów i generuje dane wyjściowe w oparciu o najlepszy klaster.
Ustaw seed jest domyślnie zaznaczony. Ta opcja inicjalizuje generator liczb losowych, który jest używany do obliczania początkowych centroidów klastra. Ustawienie liczby losowej na niezerową wartość (domyślnie 12345) zapewnia, że ta sama sekwencja liczb losowych jest używana za każdym razem, gdy obliczane są początkowe centroidy klastra. Gdy ziarno jest zerowe, generator liczb losowych jest inicjowany z zegara systemowego, więc sekwencja liczb losowych jest inna za każdym razem, gdy centroidy są inicjowane. Ustaw seed tak, aby kolejne uruchomienia metody klastrowania były porównywalne.
wybierz opcję znormalizuj dane wejściowe, aby znormalizować dane. W tym przykładzie dane nie zostaną znormalizowane. Wybierz Dalej, aby otworzyć okno dialogowe Krok 3 z 3.
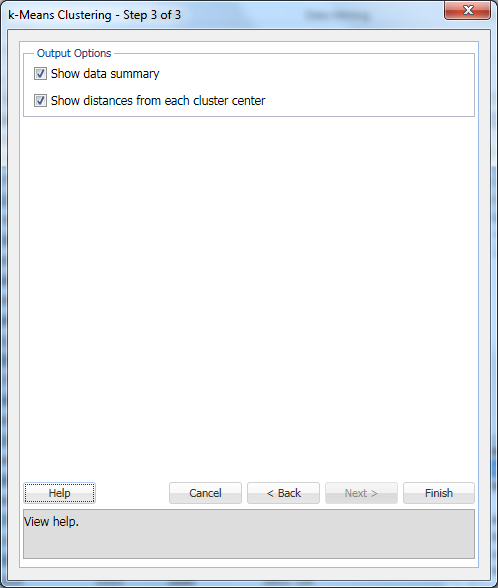
wybierz Pokaż podsumowanie danych (domyślnie) I Pokaż odległości od każdego centrum klastra (domyślnie), a następnie kliknij Zakończ.
K-Means Clustering method starts with K initial clusters as specified. Przy każdej iteracji rekordy są przypisywane do klastra z najbliższym centroidem lub centrum. Po każdej iteracji obliczana jest odległość każdego rekordu od środka klastra. Te dwa kroki są powtarzane (przypisanie rekordu i Obliczanie odległości), dopóki redystrybucja rekordu nie spowoduje zwiększenia wartości odległości.
gdy podany jest losowy start, algorytm generuje losowo centra klastra k i dopasowuje punkty danych w tych klastrach. Proces ten jest powtarzany dla wszystkich określonych losowych uruchomień. Wyjście opiera się na klastrach, które wykazują najlepsze dopasowanie.
arkusz KM_Output1 jest wstawiany natychmiast po prawej stronie arkusza danych. W górnej części wyjściowego arkusza roboczego wybrane opcje są wymienione.
w środkowej części arkusza wyjściowego XLMiner obliczył sumę kwadratowych odległości i ustalił początek z najniższą sumą kwadratowej odległości jako najlepszy początek (#5). Po określeniu najlepszego startu, xlminer generuje Pozostałe wyjście używając najlepszego startu jako punktu startowego.
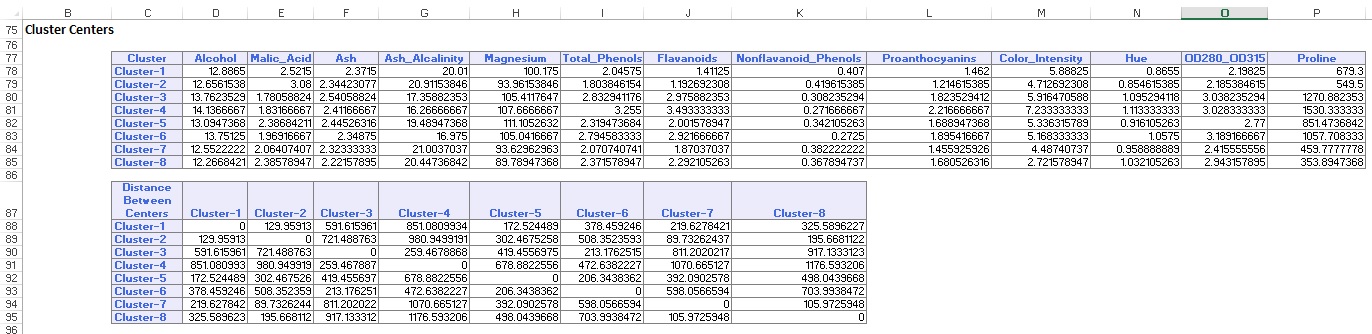
w dolnej części wyjściowego arkusza roboczego XLMiner wymienia Centra klastrów (pokazane poniżej). Górne pole pokazuje wartości zmiennych w centrach klastra. Klaster 8 ma najwyższą średnią zawartość alkoholu, Total_Phenols,Flawanoids, Proanthocyanins, Color_Intensity, Hue i Proline. Porównaj ten klaster z klastrem 2, który ma najwyższą średnią Ash_Alcalinity i Nonflavanoid_Phenols.
dolne pole pokazuje odległość między centrami klastra. Na podstawie wartości w tej tabeli ustalono, że klaster 3 bardzo różni się od klastra 8 ze względu na wysoką wartość odległości 1,176.59, A Klaster 7 jest blisko klastra 3 z niską wartością odległości 89.73.
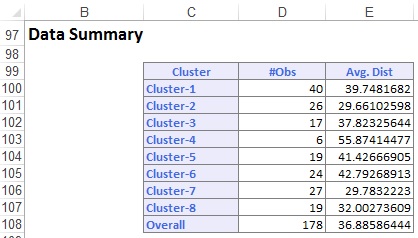
podsumowanie danych (poniżej) wyświetla liczbę rekordów (obserwacji) zawartych w każdym klastrze i średnią odległość od członków klastra do środka każdego klastra. Cluster 6 ma najwyższą średnią odległość 42,79 i zawiera 24 rekordy. Porównaj tę gromadę z gromadą 2, która ma najmniejszą średnią odległość 29,66 i obejmuje 26 członków.
kliknij arkusz km_clusters1. Ten arkusz roboczy wyświetla klaster, do którego przypisany jest każdy rekord oraz odległość do każdego z klastrów. Dla pierwszego rekordu odległość do klastra 6 jest minimalną odległością 23,205, więc ten pierwszy rekord jest przypisany do klastra 6.