ten post naprawdę czerpie z naszej serii na temat kafka architecture , która obejmuje tematy Kafka architecture , Kafka producer architecture , kafka consumer architecture i kafka ecosystem architecture .
ten artykuł jest mocno inspirowany sekcją Kafki na temat projektowania wokół zagęszczania drewna. można o tym myśleć jako o notatkach klifowych o projektowaniu Kafki wokół zagęszczania Bali.
kafka może usuwać starsze rekordy na podstawie czasu lub rozmiaru dziennika. kafka obsługuje również zagęszczanie dziennika dla zagęszczania klucza rekordu. zagęszczanie dziennika oznacza, że kafka zachowa najnowszą wersję rekordu i usunie starsze wersje podczas zagęszczania dziennika.
jean-paul azar pracuje w Cloud . cloudurable zapewnia kafka training, kafka consulting, kafka support i pomaga w tworzeniu klastrów kafka w aws .
- Kafka log compaction
- struktura zagęszczania kłody Kafki
- struktura zagęszczania dziennika Kafki
- podstawy zagęszczania dziennika Kafki
- kafka log proces zagęszczania
- Kafka log czyszczenie zagęszczania
- Kafka log cleaner
- konfiguracja tematu dla zagęszczania dziennika
- przegląd zagęszczania dziennika
- jakie są trzy sposoby usuwania rekordów?
- do czego służy zagęszczanie drewna?
- jaka jest struktura sprasowanego dziennika? opisz strukturę.
- co to jest segment partycji?
Kafka log compaction
log compaction zachowuje przynajmniej ostatnią znaną wartość dla każdego klucza rekordu dla pojedynczej partycji tematu. zwarte dzienniki są przydatne do przywracania stanu po awarii lub awarii systemu.
są one przydatne do usług w pamięci, trwałych magazynów danych, przeładowywania pamięci podręcznej itp. ważnym przypadkiem użycia strumieni danych jest rejestrowanie zmian w kluczowanych, mutowalnych zmianach danych w tabeli bazy danych lub zmian w obiekcie w mikrousługach w pamięci.
zagęszczanie dziennika jest mechanizmem przechowywania ziarnistego, który zachowuje ostatnią aktualizację dla każdego klucza. dziennik skompresowany temat zawiera pełną migawkę końcowych wartości rekordów dla każdego klucza rekordu, a nie tylko ostatnio zmienionych kluczy.
Kafka log compaction pozwala dalszym odbiorcom na przywrócenie ich stanu z tematu zagęszczonego logiem.
struktura zagęszczania kłody Kafki
z ubitym kłodą kłoda ma głowę i ogon. Głowica ubitego kłoda jest identyczna z tradycyjnym kłodą Kafki. nowe rekordy są dołączane do końca głowy.
wszystkie prace zagęszczania kłody na ogonie kłody. tylko ogon się zagęszcza. rekordy w ogonie dziennika zachowują swoje oryginalne przesunięcie po zapisaniu po przepisaniu za pomocą funkcji compaction cleanup .
struktura zagęszczania dziennika Kafki

podstawy zagęszczania dziennika Kafki
wszystkie przesunięcia dziennika pozostają ważne, nawet jeśli rekord o przesunięciu został zagęszczony, ponieważ konsument otrzyma następne najwyższe przesunięcie.
zagęszczanie dziennika Kafki pozwala również na usuwanie. wiadomość z kluczem i null działa jak nagrobek, znacznik delete dla tego klucza. nagrobki są usuwane po pewnym czasie. zagęszczanie dziennika okresowo odbywa się w tle przez ponowne kopiowanie segmentów dziennika. zagęszczanie nie blokuje odczytów i można je Dławić, aby uniknąć wpływu na wejścia / wyjścia producentów i konsumentów.
kafka log proces zagęszczania
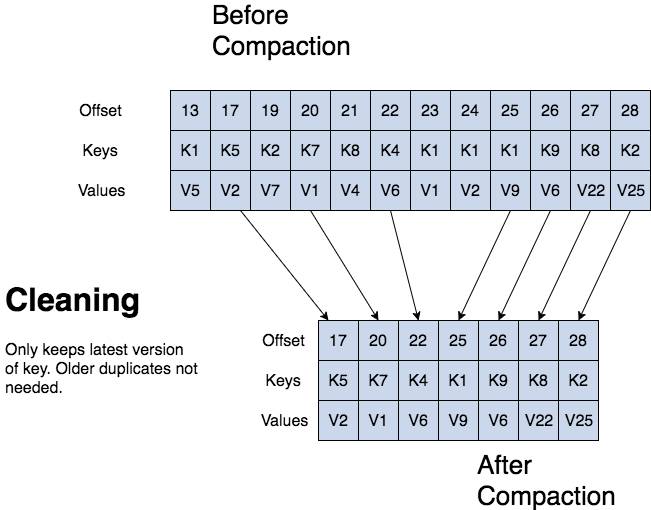
Kafka log czyszczenie zagęszczania
jeśli użytkownik Kafki zostanie złapany na czele dziennika, zobaczy każdy zapisany rekord.
topic config min.compaction.lag.ms jest używany, aby zagwarantować minimalny okres, który musi upłynąć, zanim wiadomość zostanie skompresowana. konsument widzi wszystkie nagrobki, o ile konsument dotrze do głowy dziennika w okresie krótszym niż konfiguracja tematu delete.retention.ms (domyślnie jest to 24 godziny). zagęszczanie dziennika nigdy nie będzie ponownie zamawiać wiadomości, po prostu usuń niektóre. przesunięcie partycji dla wiadomości nigdy się nie zmienia.
każdy konsument czytający od początku dziennika widzi co najmniej ostateczny stan wszystkich rekordów w kolejności, w jakiej zostały napisane.
Kafka log cleaner
przypomnij sobie, że temat Kafki ma log. dziennik jest podzielony na partycje, a partycje są podzielone na segmenty, które zawierają rekordy z kluczami i wartościami.
czyścik do logów kafka wykonuje zagęszczanie logów. środek do czyszczenia kłód ma pulę wątków zagęszczania tła. te wątki ponownie kopiują pliki segmentów dziennika, usuwając starsze rekordy, których klucz pojawia się ostatnio w dzienniku. każdy wątek zagęszczania wybiera dziennik tematyczny, który ma najwyższy stosunek głowicy dziennika do ogona dziennika. następnie wątek zagęszczania powtarza dziennik od początku do końca usuwając rekordy, których klucze występują później w dzienniku.
gdy narzędzie log cleaner czyści segmenty partycji dziennika, segmenty są zamieniane na partycję dziennika natychmiast zastępując starsze segmenty. w ten sposób zagęszczanie nie wymaga podwojenia przestrzeni całej partycji, ponieważ dodatkowe miejsce na dysku to tylko jeden dodatkowy segment partycji log-divide and conquer.
konfiguracja tematu dla zagęszczania dziennika
aby włączyć zagęszczanie tematu, Użyj konfiguracji tematu log.cleanup.policy=compact .
aby ustawić opóźnienie rozpoczęcia zagęszczania rekordów po ich zapisaniu, użyj topic config log.cleaner.min.compaction.lag.ms . zapisy nie zostaną skompresowane aż do tego okresu. ustawienie daje konsumentom czas na uzyskanie każdego rekordu.
przegląd zagęszczania dziennika
jakie są trzy sposoby usuwania rekordów?
kafka może usuwać starsze rekordy na podstawie czasu lub rozmiaru dziennika. kafka obsługuje również zagęszczanie dziennika dla zagęszczania klucza rekordu.
do czego służy zagęszczanie drewna?
ponieważ kompresja dziennika zachowuje ostatnią znaną wartość, jest to pełna migawka najnowszych rekordów, przydatna do przywracania stanu po awarii lub awarii systemu dla usługi w pamięci, trwałego magazynu danych lub ponownego ładowania pamięci podręcznej. pozwala to konsumentom na przywrócenie ich stanu.
jaka jest struktura sprasowanego dziennika? opisz strukturę.
z ubitym kłodą, kłoda ma głowę i ogon. Głowica ubitego kłoda jest identyczna z tradycyjnym kłodą Kafki. nowe rekordy są dołączane do końca głowy. wszystkie prace zagęszczania kłody znajdują się na ogonie ubitej kłody.
czy po zagęszczeniu zmieniają się przesunięcia rekordów dziennika? nie.
co to jest segment partycji?
przypomnij sobie, że temat ma log. dziennik tematu jest podzielony na partycje, a partycje są podzielone na pliki segmentów, które zawierają rekordy z kluczami i wartościami. pliki segmentów pozwalają na dzielenie i dzielenie, jeśli chodzi o zagęszczanie logów. plik segmentu jest częścią partycji. gdy narzędzie log cleaner czyści segmenty partycji dziennika, segmenty zostają zamienione na partycję dziennika natychmiast zastępując starsze pliki segmentów. w ten sposób zagęszczanie nie wymaga podwojenia przestrzeni całej partycji, ponieważ wymagane jest dodatkowe miejsce na dysku to tylko jeden dodatkowy segment partycji dziennika.
jean-paul azar pracuje w Cloud . cloudurable zapewnia kafka training, kafka consulting, kafka support i pomaga w tworzeniu klastrów kafka w aws .