wyobraź sobie narzędzie, które może automatycznie wykrywać JPA i hibernować problemy z wydajnością. Hypersistence Optimizer to właśnie to narzędzie!
wprowadzenie
Jeśli zastanawiasz się, dlaczego i kiedy powinieneś używać JPA lub Hibernate, ten artykuł dostarczy Ci odpowiedzi na to bardzo powszechne pytanie. Ponieważ widziałem to pytanie zadawane bardzo często na kanale / r / java Reddit, uznałem, że warto napisać dogłębną odpowiedź na temat mocnych i słabych stron JPA i Hibernate.
chociaż JPA jest standardem od czasu jego pierwszego wydania w 2006 roku, nie jest to jedyny sposób na zaimplementowanie warstwy dostępu do danych przy użyciu Javy. Omówimy zalety i wady korzystania z JPA lub innych popularnych alternatyw.
dlaczego i kiedy powstał JDBC
w 1997 roku, Java 1.1 wprowadzono API JDBC (Java Database Connectivity), które było bardzo rewolucyjne jak na swoje czasy, ponieważ oferowało możliwość zapisu warstwy dostępu do danych raz za pomocą zestawu interfejsów i uruchamiało ją na dowolnej relacyjnej bazie danych, która implementuje API JDBC bez konieczności zmiany kodu aplikacji.
interfejs API JDBC oferował interfejs Connection do kontrolowania granic transakcji i tworzenia prostych instrukcji SQL za pośrednictwem interfejsu API Statement lub gotowych instrukcji, które umożliwiają Wiązanie wartości parametrów za pośrednictwem interfejsu API PreparedStatement.
zakładając, że mamy post tabelę bazy danych i chcemy wstawić 100 wierszy, oto jak możemy osiągnąć ten cel za pomocą JDBC:
int postCount = 100;int batchSize = 50;try (PreparedStatement postStatement = connection.prepareStatement(""" INSERT INTO post ( id, title ) VALUES ( ?, ? ) """)) { for (int i = 1; i <= postCount; i++) { if (i % batchSize == 0) { postStatement.executeBatch(); } int index = 0; postStatement.setLong( ++index, i ); postStatement.setString( ++index, String.format( "High-Performance Java Persistence, review no. %1$d", i ) ); postStatement.addBatch(); } postStatement.executeBatch();} catch (SQLException e) { fail(e.getMessage());}
podczas gdy wykorzystaliśmy Wielowierszowe bloki tekstowe i próbowaliśmy użyć bloków z zasobami, aby wyeliminować wywołanie PreparedStatement close, implementacja nadal jest bardzo gadatliwa. Zauważ, że parametry bind zaczynają się od wartości 1, a nie od wartości 0, do czego można się przyzwyczaić w innych dobrze znanych interfejsach API.
aby pobrać pierwsze 10 wierszy, możemy potrzebować uruchomić zapytanie SQL za pomocą PreparedStatement, które zwróci ResultSet reprezentujący wynik zapytania oparty na tabeli. Ponieważ jednak aplikacje używają struktur hierarchicznych, takich jak JSON lub DTOs do reprezentowania skojarzeń rodzic-dziecko, większość aplikacji musiała przekształcić JDBC ResultSet do innego formatu w warstwie dostępu do danych, jak pokazano w poniższym przykładzie:
int maxResults = 10;List<Post> posts = new ArrayList<>();try (PreparedStatement preparedStatement = connection.prepareStatement(""" SELECT p.id AS id, p.title AS title FROM post p ORDER BY p.id LIMIT ? """)) { preparedStatement.setInt(1, maxResults); try (ResultSet resultSet = preparedStatement.executeQuery()) { while (resultSet.next()) { int index = 0; posts.add( new Post() .setId(resultSet.getLong(++index)) .setTitle(resultSet.getString(++index)) ); } }} catch (SQLException e) { fail(e.getMessage());}
ponownie, jest to najmilszy sposób, w jaki możemy to napisać za pomocą JDBC, ponieważ używamy bloków tekstowych, próbujemy z zasobami i płynnie stylowego interfejsu API do budowania obiektów Post.
niemniej jednak, JDBC API jest nadal bardzo gadatliwe i, co ważniejsze, brakuje wielu funkcji, które są wymagane przy wdrażaniu nowoczesnej warstwy dostępu do danych, takich jak:
- sposób pobierania obiektów bezpośrednio z zestawu wyników zapytania. Jak widzieliśmy w powyższym przykładzie, musimy iterować
ReusltSeti wyodrębnić wartości kolumn, aby ustawić właściwości obiektuPost. - przejrzysty sposób na wsadowe instrukcje bez konieczności przepisywania kodu dostępu do danych podczas przełączania z domyślnego trybu bez dozowania na użycie dozowania.
- wsparcie dla optymistycznego blokowania
- interfejs API do stronicowania, który ukrywa składnię zapytań Top-N I Next-N
dlaczego i kiedy utworzono Hibernate
w 1999 roku Sun wydał J2EE (Java Enterprise Edition), który oferował alternatywę dla JDBC, zwaną Entity Beans.
jednak, ponieważ Entity Beans były notorycznie powolne, zbyt skomplikowane i kłopotliwe w użyciu, w 2001 roku Gavin King postanowił stworzyć framework ORM, który mógłby mapować tabele baz danych na POJOs (zwykłe stare obiekty Java) i tak narodził się Hibernate.
będąc bardziej lekkim niż Entity Beans i mniej gadatliwym niż JDBC, Hibernate stawał się coraz bardziej popularny, a wkrótce stał się najpopularniejszym frameworkiem Java persistence, wygrywając z JDO, iBatis, Oracle TopLink i Apache Cayenne.
dlaczego i kiedy powstało JPA?
ucząc się od sukcesu projektu Hibernate, Platforma Java EE postanowiła ujednolicić sposób Hibernate i Oracle TopLink, i tak narodził się JPA (Java Persistence API).
JPA jest tylko specyfikacją i nie może być używana samodzielnie, dostarczając tylko zestaw interfejsów, które definiują standardowe API persistence, które jest implementowane przez dostawcę JPA, takiego jak Hibernate, EclipseLink lub OpenJPA.
podczas korzystania z JPA należy zdefiniować mapowanie między tabelą bazy danych a powiązanym z nią obiektem encji Java:
@Entity@Table(name = "post")public class Post { @Id private Long id; private String title; public Long getId() { return id; } public Post setId(Long id) { this.id = id; return this; } public String getTitle() { return title; } public Post setTitle(String title) { this.title = title; return this; }}
następnie możemy przepisać poprzedni przykład, który zapisał 100 post rekordów wygląda tak:
for (long i = 1; i <= postCount; i++) { entityManager.persist( new Post() .setId(i) .setTitle( String.format( "High-Performance Java Persistence, review no. %1$d", i ) ) );}
aby włączyć wstawianie wsadowe JDBC, musimy tylko dostarczyć jedną właściwość konfiguracji:
<property name="hibernate.jdbc.batch_size" value="50"/>
po udostępnieniu tej właściwości Hibernate może automatycznie przełączyć się z nieporuszania na porcjowanie bez potrzeby zmiany kodu dostępu do danych.
i, aby pobrać pierwsze 10 post wierszy, możemy wykonać następujące zapytanie JPQL:
int maxResults = 10;List<Post> posts = entityManager.createQuery(""" select p from post p order by p.id """, Post.class).setMaxResults(maxResults).getResultList();
jeśli porównasz to z wersją JDBC, zobaczysz, że JPA jest znacznie łatwiejszy w użyciu.
zalety i wady korzystania z JPA i Hibernate
JPA, w ogóle, a Hibernate, w szczególności, oferują wiele zalet.
- możesz pobrać encje lub Dto. Można nawet pobrać hierarchiczną projekcję Dto rodzic-dziecko.
- możesz włączyć dozowanie JDBC bez zmiany kodu dostępu do danych.
- masz wsparcie dla optymistycznego blokowania.
- masz pesymistyczną abstrakcję blokowania, która jest niezależna od podstawowej składni specyficznej dla bazy danych, dzięki czemu możesz uzyskać blokadę odczytu i zapisu, a nawet blokadę pominięcia.
- masz API paginacji niezależne od bazy danych.
- możesz podać
Listwartości do klauzuli IN query, jak wyjaśniono w tym artykule. - możesz użyć silnie spójnego rozwiązania buforującego, które pozwala odciążyć węzeł główny, który dla transakcji Rea-write może być wywoływany tylko pionowo.
- masz wbudowaną obsługę rejestrowania audytów za pośrednictwem Hibernate Envers.
- masz wbudowaną obsługę multitenancy.
- możesz wygenerować początkowy skrypt schematu z mapowania encji za pomocą narzędzia Hibernate hbm2ddl, które możesz dostarczyć do automatycznego narzędzia do migracji schematu, takiego jak Flyway.
- nie tylko masz swobodę wykonywania dowolnego natywnego zapytania SQL, ale możesz użyć SqlResultSetMapping do przekształcenia JDBC
ResultSetw encje JPA lub Dto.
wady korzystania z JPA i Hibernate są następujące:
- chociaż rozpoczęcie pracy z JPA jest bardzo łatwe, stań się ekspertem wymaga znacznych nakładów czasu, ponieważ oprócz przeczytania jego podręcznika, nadal musisz nauczyć się, jak działają systemy baz danych, standard SQL, a także specyficzny smak SQL używany przez bazę danych relacji projektu.
- istnieje kilka mniej intuicyjnych zachowań, które mogą zaskoczyć początkujących, takich jak kolejność operacji spłukiwania.
- interfejs API kryteriów jest dość obszerny, więc musisz użyć narzędzia takiego jak Codota, aby łatwiej pisać dynamiczne zapytania.
ogólna społeczność i popularne integracje
JPA i Hibernate są niezwykle popularne. Według raportu Java ecosystem report Snyk z 2018 roku, Hibernate jest używane przez 54% każdego programisty Java, który wchodzi w interakcję z relacyjną bazą danych.
ten wynik może być wspierany przez Google Trends. Na przykład, jeśli porównamy Google Trends JPA z jego głównymi konkurentami (np. MyBatis, QueryDSL i jOOQ), zobaczymy, że JPA jest wielokrotnie bardziej popularna i nie wykazuje oznak utraty dominującej pozycji w rynku.

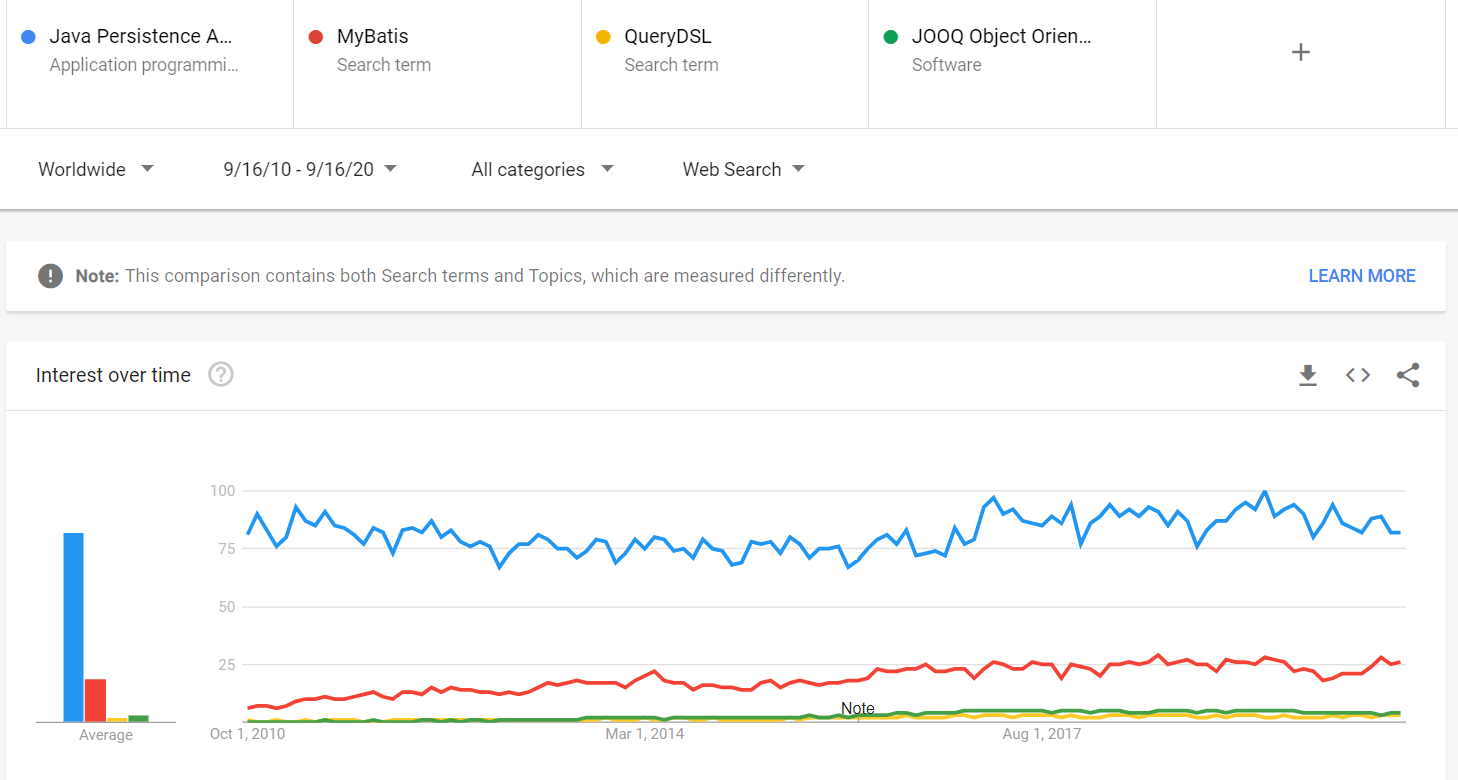
bycie tak popularnym przynosi wiele korzyści, takich jak:
- Integracja Spring Data JPA działa jak urok. W rzeczywistości jednym z największych powodów, dla których JPA i Hibernate są tak popularne, jest to, że Spring Boot używa Spring Data JPA, który z kolei używa Hibernate za kulisami.
- jeśli masz jakiś problem, istnieje duża szansa, że te odpowiedzi na StackOverflow związane z hibernacją 30K i odpowiedzi na StackOverflow związane z JPA 16K, zapewnią ci rozwiązanie.
- dostępnych jest 73K samouczków Hibernate. Tylko moja strona oferuje ponad 250 samouczków JPA i Hibernate, które uczą cię, jak w pełni wykorzystać JPA i Hibernate.
- istnieje wiele kursów wideo, których możesz również użyć, takich jak mój wysokowydajny Kurs wideo Java Persistence.
- na Amazon jest ponad 300 książek na temat Hibernate, z których jedna to również moja wydajna Książka Java Persistence.
alternatywy JPA
jedną z największych zalet ekosystemu Java jest obfitość wysokiej jakości frameworków. Jeśli JPA i Hibernate nie pasują do twojego przypadku użycia, możesz użyć dowolnej z następujących frameworków:
- MyBatis, który jest bardzo lekkim frameworkiem do mapowania zapytań SQL.
- QueryDSL, który pozwala na dynamiczne tworzenie zapytań SQL, JPA, Lucene i MongoDB.
- jOOQ, który zapewnia Java metamodel dla bazowych tabel, procedur składowanych i funkcji i pozwala na dynamiczne budowanie zapytania SQL przy użyciu bardzo intuicyjnego DSL i w sposób bezpieczny dla typu.
więc używaj tego, co działa najlepiej dla ciebie.
warsztaty online
jeśli podobał Ci się ten artykuł, założę się, że spodoba ci się mój nadchodzący 4-dniowy x 4-godzinny wysokowydajny Warsztat Online Java Persistence

wniosek
w tym artykule widzieliśmy, dlaczego JPA został stworzony i kiedy należy go używać. Chociaż JPA przynosi wiele korzyści, masz wiele innych wysokiej jakości alternatyw do użycia, jeśli JPA i Hibernate nie działają najlepiej dla aktualnych wymagań aplikacji.
i czasami, jak wyjaśniłem w tej darmowej próbce mojej wysokowydajnej książki o trwałości Javy, nie musisz nawet wybierać między JPA lub innymi frameworkami. Możesz łatwo połączyć JPA z frameworkiem takim jak jOOQ, aby uzyskać to, co najlepsze z obu światów.



