zaczynamy od spojrzenia na dwuformatową regresję liniową / grzbietową, zanim pokażemy, jak ją „kernelizować”. Wyjaśniając to drugie, zobaczymy, czym są jądra i czym jest „sztuczka jądra”.
Dwuformatowa regresja grzbietu
regresja liniowa jest zwykle podawana w postaci podstawowej jako liniowa kombinacja kolumn (funkcji). Istnieje jednak druga, Podwójna forma, w której jest to liniowa kombinacja wewnętrznego produktu nowego punktu odniesienia (na którym wnioskujemy) z każdym z danych treningowych.
rozważamy przypadek regresji grzbietowej (regresja liniowa L2), pamiętając, że podstawowa regresja liniowa odpowiada przypadkowi, w którym \(\lambda = 0\). Następnie wzory regresji grzbietu, gdzie \(X\) i \(Y\) odnoszą się do danych treningowych \(N \razy m\) i \(X^\prime,y^\prime\) nowy przypadek, który należy oszacować, to:
\ \ \ \
gdzie \(\langle X_i, x^\prime \ rangle\) jest iloczynem wewnętrznym / kropkowym, więc \(\langle X_i, x^ \ prime \rangle = X^T_i x^ \ prime = \ sum_j^m x_{I, j} x^ \ prime_j\).
Podwójna forma pokazuje, że regresja liniowa / grzbietowa może być również rozumiana jako zapewnienie oszacowania ważonej sumy wewnętrznego produktu nowego przypadku z każdym z przypadków szkoleniowych.
oznacza to, że możemy wykonać regresję liniową nawet wtedy, gdy jest więcej kolumn niż wierszy, chociaż znaczenie tego może być zawyżone, ponieważ (i) możemy to zrobić i tak za pomocą regularyzacji L2, ponieważ to zawsze sprawia, że macierz \(x^TX\) jest odwracalna; i (ii) macierz \(XX^t\) często i tak wymaga regularyzacji L2, aby zapewnić stabilność numeryczną dla inwersji. Pozwala nam również postrzegać regresję liniową jako bardziej sekwencyjny proces uczenia się, w którym każda dodatkowa informacja w danych treningowych przynosi coś nowego.
co jednak najważniejsze dla naszych celów, forma Podwójna ma ciekawą cechę: wektory funkcji występują w równaniach tylko wewnątrz produktów wewnętrznych. Jest to prawdą nawet w definicji \(\alpha\), ponieważ \(XX^t\) wytwarza macierz odpowiadającą wewnętrznym iloczynom każdej pary wektorów cech w danych treningowych. Zobaczymy, jak ważne jest to w miarę postępów.
pomijając: zainteresowani uczniowie mogą zobaczyć, jak powstała Podwójna forma w dokumencie wyprowadzenie podwójnej formy dostępnym w sekcji Pliki do pobrania na końcu tego artykułu.
nieliniowa regresja podwójnego grzbietu
możemy przekształcić naszą regresję podwójnego grzbietu w model nieliniowy za pomocą standardowej metody użycia nieliniowych przekształceń funkcji \(\phi\):
\ \
funkcje jądra
funkcja jądra, \(k: \mathcal X \times \mathcal X \to \mathbb{R}\), jest funkcją symetryczną – \(k(x_1,x_2)=k(x_2, x_1)\) – i dodatnią określoną (zobacz na bok formalną definicję). Dodatnia-definitywność stosowana jest w matematyce, która uzasadnia użycie jąder. Ale bez znaczącej wiedzy matematycznej definicja nie jest intuicyjnie oświecająca. Zamiast więc próbować zrozumieć jądra z definicji dodatnio-definitywności, przedstawimy je z wieloma przykładami.
zanim to zrobimy, zauważamy, że chociaż jądra są funkcjami dwuargumentowymi, często uważa się je za znajdujące się przy pierwszym argumencie i będące funkcją drugiego. Zgodnie z tą interpretacją zobaczysz notację taką jak \(K_x (y)\), która jest równoważna \(K (x, y)\). W szczególności, często będziemy myśleć o jądrach jako funkcjach pojedynczego argumentu „zlokalizowanych” w punktach danych (wektorach funkcji) w naszych danych treningowych. Czasami przeczytasz, że „upuszczamy” jądra na punkty danych. Jeśli więc mamy wektor funkcji \(x_i\), to upuścilibyśmy na niego jądro, prowadzące do funkcji \(k_{x_i} (x)\) znajdującej się w \(x_i\) i odpowiadającej \(K (x_i,x)\) .
zauważamy również, że jądra są często określane jako członkowie rodzin parametrycznych. Przykładami takich rodzin jąder są:
Jądra Gaussa
jądra Gaussa są przykładem jąder funkcji radialnej i są czasami nazywane promieniowymi jądrami bazowymi. Wartość jądra radialnej funkcji bazowej zależy tylko od odległości między wektorami argumentów, a nie od ich położenia. Takie jądra są również określane jako stacjonarne.
parametry: \(\gamma\)
postać równania: \(K (X_1,X_2)=e^{- \gamma \ / X_1-X_2 \|^2}\)
Jądra Laplacjańskie
jądra Laplacjańskie są również promieniowymi funkcjami bazowymi.
parametry: \(\sigma\)
: \(K (X_1,X_2)=e^{- \frac {\|x_1 – X_2\|} {\sigma}}\)
Jądra wielomianowe
jądra wielomianowe są przykładem niestacjonarnych jąder. Więc te jądra przyporządkują różne wartości do par punktów, które dzielą tę samą odległość, na podstawie ich wartości. Wartości parametrów muszą być nieujemne, aby zapewnić, że te jądra są dodatnie określone.
parametry: \(\alpha, c, d\)
postać równania: \(K(X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
podanie konkretnych wartości dla parametrów rodziny jądra powoduje powstanie funkcji jądra. Poniżej znajdują się przykłady funkcji jądra z powyższych rodzin o określonych wartościach parametrów znajdujących się w różnych punktach (tzn. wykreślony wykres jest funkcją drugiego argumentu, z pierwszym argumentem ustawionym na określoną wartość).
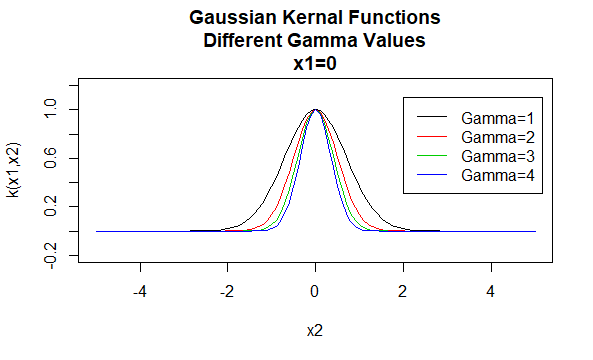
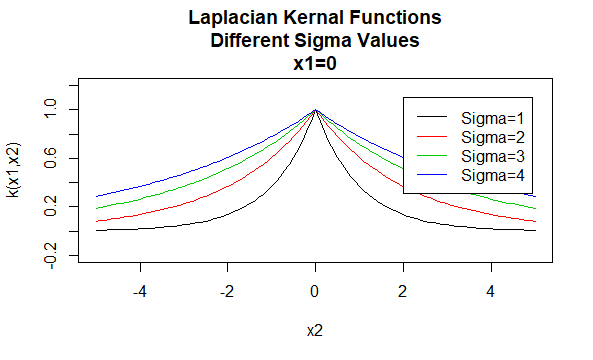
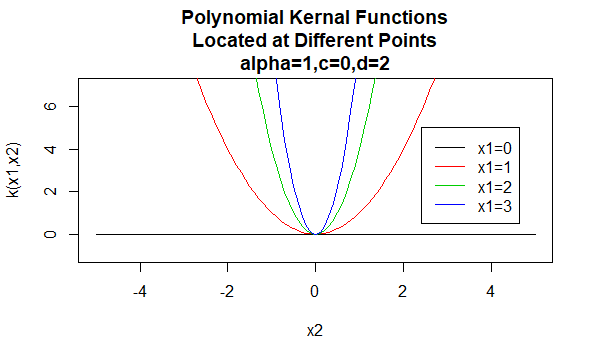
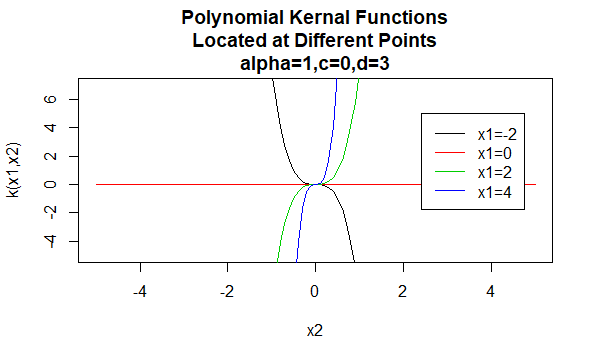
Na Bok: Zainteresowani uczniowie mogą zapoznać się z definicją dodatniej definitywności dla jąder w dokumencie jądra i dodatniej Definitywności dostępnym w sekcji Pliki do pobrania na końcu tego artykułu.
sztuczka Jądra
znaczenie funkcji jądra wynika z bardzo szczególnej właściwości: Każde dodatnio określone jądro, \(K\) jest związane z przestrzenią matematyczną, \(\mathcal{H}_K\), (znaną jako odtwarzająca jądro przestrzeń Hilberta (RKHS) jądra), tak że zastosowanie \(K\) do dwóch wektorów funkcji, \(x_1,X_2\) jest równoważne rzutowaniu tych wektorów funkcji do \(\mathcal{H}_K\) przez jakąś funkcję projekcyjną, \(\phi\) i pobranie ich wewnętrznego iloczynu:
\
rkhss związane z jądrami są zazwyczaj wysokowymiarowe. Dla niektórych jąder, takich jak jądra rodziny Gaussa, są one nieskończenie wymiarowe.
powyższe jest podstawą słynnej „sztuczki jądra”: jeśli funkcje wejściowe są zaangażowane w równanie modelu statystycznego tylko w postaci produktów wewnętrznych, to możemy zastąpić produkty wewnętrzne w równaniu wywołaniami funkcji jądra, a wynik jest taki, jakbyśmy rzutowali funkcje wejściowe na przestrzeń o wyższym wymiarze (tzn. przeprowadziliśmy transformację funkcji prowadzącą do dużej liczby ukrytych cech zmiennych) i pobrali tam ich wewnętrzny produkt. Ale nigdy nie musimy wykonywać rzeczywistej projekcji.
w terminologii uczenia maszynowego, rkhs związane z jądrem jest znane jako przestrzeń funkcji, w przeciwieństwie do przestrzeni wejściowej. Poprzez sztuczkę jądra domyślnie rzutujemy funkcje wejściowe do tej przestrzeni funkcji i pobieramy tam ich wewnętrzny produkt.
regresja Jądra
prowadzi to do techniki znanej jako regresja jądra. Jest to po prostu zastosowanie triku jądra do podwójnej formy regresji grzbietu. Dla ułatwienia Wprowadzamy pojęcie jądra, czyli grama, macierzy, \(K\), takie, że \(k_{i, j}=k (X_i,X_j)\). Wtedy możemy zapisać równania regresji jądra jako:
\ \
gdzie \(k\) jest jakąś dodatnio określoną funkcją jądra.
twierdzenie represyjne
rozważmy problem optymalizacji, który staramy się rozwiązać podczas wykonywania L2 regularyzacji dla modelu jakiejś formy, \(f\):
\
podczas wykonywania regresji jądra za pomocą jądra \(k\) ważnym wynikiem teorii regularyzacji jest to, że minimalizator powyższego równania będzie miał postać:
\
z \(\alpha\) obliczone jak opisano powyżej.
to jest słuszne twierdzenie represyjne. W słowach, mówi, że minimalizator problemu optymalizacji regresji liniowej w ukrytej przestrzeni funkcji uzyskanej przez dane jądro (a zatem minimalizator problemu regresji nieliniowej jądra) będzie dany przez ważoną sumę jąder „zlokalizowanych” w każdym wektorze funkcji.
jest o wiele więcej do powiedzenia na ten temat. Możemy nawet obliczyć, jaka funkcja Greena (której jądra są podzbiorem) zminimalizuje określone specyfikacje regularyzacji, takie jak regularyzacja L2, ale także wszelkie kary oparte na liniowym operatorze różniczkowym. Ten związek pomiędzy jądrami a optymalnymi rozwiązaniami problemów regularyzacji Tichonowa jest głównym powodem znaczenia metod jądra w uczeniu maszynowym. Ale matematyka tutaj wykracza poza ten kurs, A zainteresowani zaawansowani studenci są odsyłani do rozdziału siódmego sieci neuronowych i maszyn uczenia się Haykina.
to daje nam matematyczne uzasadnienie stosowania regresji jądra w przypadkach, gdy jest to możliwe. W rzeczywistości wypracowanie optymalnego jądra do użycia zazwyczaj nie jest możliwe-wymaga znajomości optymalnego liniowego operatora różniczkowego do użycia dla kary regularyzacji. Funkcje, które powinniśmy projektować, aby zoptymalizować poszczególne kary regularyzacji, zostały obliczone i wiemy, na przykład, że jądro z cienką płytką jest optymalne dla regularyzacji L2. Z drugiej strony, ponieważ musimy obliczyć macierz grama, regresja jądra nie skaluje się dobrze – dla dużych zbiorów danych lepszym pomysłem jest przejście do sieci neuronowych.