vi börjar med att titta på dual-form linjär/ridge regression, innan visar hur man ’kernelize’ det. När vi förklarar det senare kommer vi att se vilka kärnor som är och vad ’kärntricket’ är.
dubbelformad Ryggregression
linjär regression ges vanligtvis i den primära formen som en linjär kombination av kolumner (funktioner). Det finns emellertid en andra, dubbel form där det är en linjär kombination av den inre produkten av ett nytt datum (som vi utför inferens på) med var och en av träningsdata.
vi betraktar fallet med åsregression (L2 regulariserad linjär regression), kom ihåg att grundläggande linjär regression motsvarar fallet där \(\lambda = 0\). Sedan formlerna för ridge regression, där \(X\) och \(Y\) hänvisar till \(n\ times m\) träningsdata och \(x^\prime,y^\prime\) ett nytt fall som ska uppskattas, är:
\ \ \ \
där \(\langle X_i, x^ \ prime \ rangle\) är den inre/punktprodukten, så \(\langle X_i,x^\prime \rangle = X^T_i x^\prime = \sum_j^m x_{I,j} x^\prime_j\).
den dubbla formen visar att linjär / åsregression också kan förstås som att ge en uppskattning av en viktad summa av den inre produkten av ett nytt fall med vart och ett av träningsfallen.
det betyder att vi kan göra linjär regression även när det finns fler kolumner än rader, men vikten av detta kan överdrivas eftersom (i) vi kan göra det ändå via användningen av L2-regularisering eftersom detta alltid gör \(X^TX\) matrisen inverterbar; och (ii) \(XX^T\) matrisen kan ofta kräva L2-regularisering ändå för att säkerställa numerisk stabilitet för inversionen. Det gör det också möjligt för oss att se linjär regression som mycket mer av en sekventiell inlärningsprocess, där varje ytterligare datum i träningsdata ger något nytt.
viktigast för våra ändamål har dock den dubbla formen den intressanta egenskapen: funktions vektorer förekommer i ekvationerna endast inom inre produkter. Detta gäller även i definitionen av \(\alpha\), eftersom\ (XX^T\) producerar matrisen som motsvarar de inre produkterna i varje par av funktionsvektorer i träningsdata. Vi kommer att se vikten av detta när vi fortsätter.
åt sidan: intresserade studenter kan se hur den dubbla formen härleddes i härledningen av dubbla Formdokument som finns i avsnittet Nedladdningar i slutet av denna artikel.
icke-linjär Dubbelryggregression
vi kan förvandla vår dubbla formryggregression till en icke-linjär modell med standardmetoden att använda en icke-linjär funktionstransformationer \(\phi\):
\ \
kärnfunktioner
en kärnfunktion, \(K: \mathcal X \times \mathcal X \to\ mathbb{R}\), är en funktion som är symmetrisk – \ (K(x_1,x_2)=K(x_2,x_1)\) – och positiv bestämd (se sidan för en formell definition). Positiv bestämdhet används i matematiken som motiverar användningen av kärnor. Men utan betydande matematisk kunskap är definitionen inte intuitivt upplysande. Så snarare än att försöka förstå kärnor från definitionen av positiv bestämdhet, kommer vi att presentera dem med ett antal exempel.
innan vi gör detta noterar vi att även om kärnor är tvåargumentfunktioner, är det vanligt att tänka på dem som lokaliserade vid deras första argument och vara en funktion av deras andra. Enligt denna tolkning kommer du att se notation som \(K_x(y)\), vilket motsvarar \(K (x,y)\) . I synnerhet kommer vi ofta att tänka på att kärnor är enstaka argumentfunktioner ’placerade’ vid datapunkter (funktionsvektorer) i våra träningsdata. Ibland kommer du att läsa av oss ’släppa’ kärnor på datapunkter. Så om vi har en funktionsvektor \(x_i\) , skulle vi släppa en kärna på den, vilket leder till funktionen \(K_{x_i} (x)\) som ligger vid \(x_i\) och motsvarar \(K (X_i,x)\) .
vi noterar också att kärnor ofta anges som medlemmar i parametriska familjer. Exempel på sådana kärnfamiljer inkluderar:
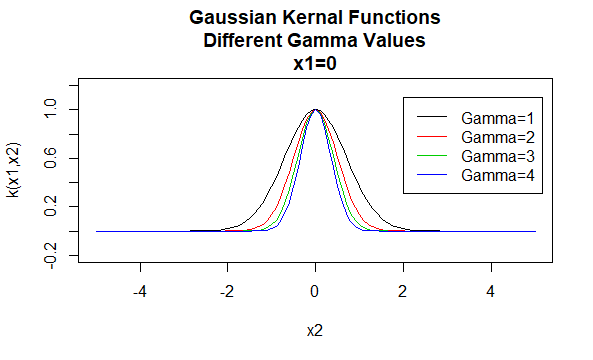
gaussiska kärnor
gaussiska kärnor är ett exempel på radiella grundfunktionskärnor och kallas ibland radiella grundkärnor. Värdet på en radiell basfunktionskärna beror bara på avståndet mellan argumentvektorerna, snarare än deras plats. Sådana kärnor kallas också stationära.
parametrar: \(\gamma\)
ekvationsform: \(K (X_1, X_2)=E^{- \gamma \ / X_1-X_2 \|^2}\)
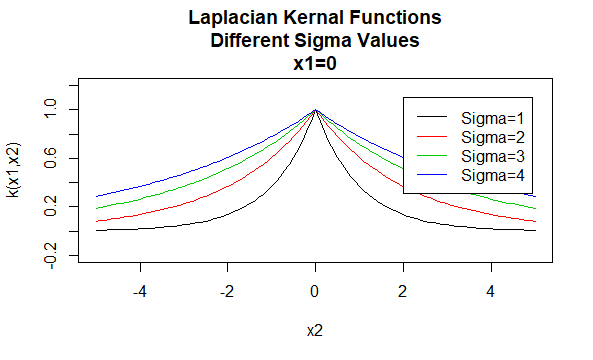
Laplacian kärnor
Laplacian kärnor är också radiella basfunktioner.
parametrar: \(\sigma\)
ekvationsform: \(K (X_1, X_2)=e^{-\frac{\| X_1 – X_2 \|}{\Sigma}}\)
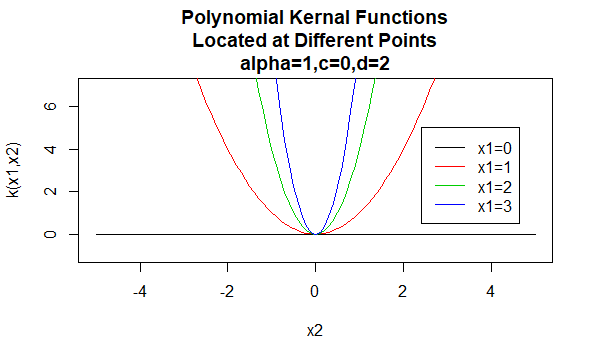
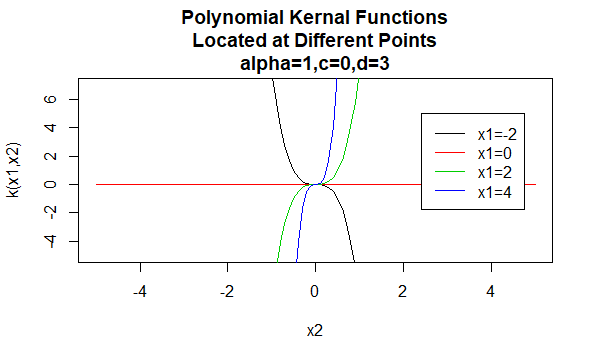
Polynomkärnor
Polynomkärnor är ett exempel på icke-stationära kärnor. Så dessa kärnor tilldelar olika värden till par punkter som delar samma avstånd, baserat på deras värden. Parametervärdena måste vara icke-negativa för att säkerställa att dessa kärnor är positiva bestämda.
parametrar: \(\alpha , c , d\)
ekvationsform: \(K(X_1,X_2)=(\alpha X_1^TX_2 +c)^d\)
specificera särskilda värden för parametrarna för en kärnfamilj resulterar i en kärnfunktion. Nedan följer exempel på kärnfunktioner från ovanstående familjer med särskilda parametervärden belägna vid olika punkter (dvs. den plottade grafen är en funktion av det andra argumentet, med det första argumentet inställt på ett specifikt värde).
Åt Sidan: Intresserade studenter kan se definitionen av positiv bestämdhet för kärnor i dokumentet kärnor och positiv bestämdhet som finns i avsnittet Nedladdningar i slutet av den här artikeln.
Kärntricket
betydelsen av kärnfunktioner kommer från en mycket speciell egenskap: Varje positiv bestämd kärna, \(K\) är relaterad till ett matematiskt utrymme, \(\mathcal{H}_K\), (känd som den reproducerande kärnan Hilbert space (RKHS) i kärnan) så att applicering av \(K\) till två funktionsvektorer,\ (X_1, X_2\) motsvarar att projicera dessa funktionsvektorer i \(\mathcal{H}_K\) av någon projektionsfunktion, \(\phi\) och tar sin inre produkt där:
\
RKHSs associerade med kärnor är vanligtvis högdimensionella. För vissa kärnor, som gaussiska familjekärnor, är de oändliga dimensionella.
ovanstående är grunden för det berömda ’kärntricket’: om inmatningsfunktionerna är involverade i ekvationen för en statistisk modell endast i form av inre produkter kan vi ersätta de inre produkterna i ekvationen med samtal till kärnfunktionen och resultatet är som om vi hade projicerat inmatningsfunktionerna i ett högre dimensionellt utrymme (dvs. utfört en funktionstransformation som leder till ett stort antal latenta variabla funktioner) och tagit sin inre produkt där. Men vi behöver aldrig utföra själva projektionen.
i maskininlärningsterminologi är RKHS associerade med kärnan känd som funktionsutrymmet, i motsats till inmatningsutrymmet. Via kärntricket projicerar vi implicit inmatningsfunktionerna i detta funktionsutrymme och tar sin inre produkt där.
Kernel Regression
detta leder till den teknik som kallas kernel regression. Det är helt enkelt en tillämpning av kärnan trick till den dubbla formen av åsen regression. För att underlätta introducerar vi tanken på kärnan, eller Gram, matris, \(K\), så att \(K_{i,j}=k(X_i,X_j)\). Då kan vi skriva ekvationerna för kärnregression som:
\ \
där \(k\) är någon positiv bestämd kärnfunktion.
Representerarsatsen
Tänk på optimeringsproblemet vi försöker lösa när vi utför L2-regularisering för en modell av någon form, \(f\):
\
när man utför kärnregression med kernel \(k\) är det ett viktigt resultat av regulariseringsteori att minimeraren av ovanstående ekvation kommer att vara av formen:
\
med\ (\alpha\) beräknat som beskrivet ovan.
Detta är den rättvist lioniserade Representerarsatsen. I ord står det att minimeraren av optimeringsproblemet för linjär regression i det implicita funktionsutrymmet som erhållits av en viss kärna (och därmed minimeraren av det icke-linjära kärnregressionsproblemet) kommer att ges av en viktad summa av kärnor ’placerade’ vid varje funktionsvektor.
det finns mycket mer att säga om detta ämne. Vi kan till och med ta reda på vilken grön funktion (av vilka kärnor som är en delmängd) kommer att minimera särskilda regulariseringsspecifikationer, såsom L2-regularisering men också alla straff baserade på en linjär differentialoperatör. Detta förhållande mellan kärnor och optimala lösningar på Tikhonov-regulariseringsproblem är en princip för kärnmetodernas betydelse i maskininlärning. Men matematiken här är bortom denna kurs, och intresserade avancerade studenter hänvisas till kapitel sju i Haykins neurala nätverk och Inlärningsmaskiner.
detta ger oss en matematisk motivering för att använda kärnregression i fall där det är möjligt att göra det. Att faktiskt utarbeta den optimala kärnan att använda är vanligtvis inte möjlig – det kräver att man känner till den optimala linjära differentialoperatören som ska användas för regulariseringsstraffet. De funktioner vi bör projicera på för att optimera särskilda regularisering påföljder har beräknats, och vi vet, till exempel, att tunn platta spline kärna är optimal för L2 regularisering. På nedsidan, eftersom vi behöver beräkna Grammatrisen, skalar kärnregressionen inte bra – för stora dataset som vänder sig till neurala nätverk är en bättre ide.