i det här snabba inlägget kommer vi att se hur vi kan installera en av de mest populära distribuerade databaserna, Apache Cassandra på Ubuntu och börja använda den också. Vi kommer igång nu.
Läs inlägg om Neo4J, Elasticsearch och MongoDB också.
Apache Cassandra
Cassandra är en av de mest populära distribuerade NoSQL-databaserna från Apache som är känd för sin skalbarhet, prestanda och hög tillgänglighet utan någon enda felpunkt.
några punkter som gör att Apache Cassandra står högt är:
- konsekvent och mycket feltolerant.
- mycket nära i arkitekturen till Amazons Dynamo DB och datamodellen ligger nära Googles Bigtable.
- Skapad på facebook
- det är en kolumnorienterad databas
- används hos några mycket stora företag som Cisco, Rackspace, Netflix och många fler
installera Java
för att installera Cassandra på Ubuntu måste vi installera Java först. Java kanske inte installeras som standard. Vi kan verifiera det med hjälp av det här kommandot:
när vi kör det här kommandot får vi följande utdata:
vi kommer nu att installera Java på vårt system. Använd det här kommandot för att göra det:
sudo apt-get update
sudo apt-get install oracle-java8-installer
när dessa kommandon är färdiga kan vi igen verifiera att Java nu är installerat med samma kommando.
installera Cassandra
installera Cassandra på Ubuntu är en mycket lätt uppgift och handlar bara om få kommandon. Vi börjar med att lägga till Cassandra repository i Ubuntu – källlistan:
| sudo tee-a /etc/apt/källor.förteckning.d / cassandra.källa.lista
när vi kör det här programmet får vi följande utdata: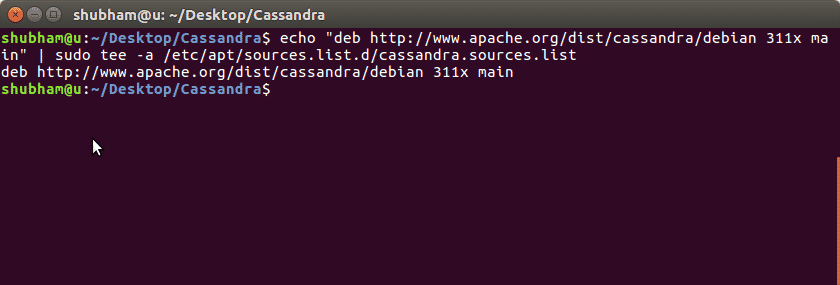
nu lägger vi till Apache Cassandra repository keys:
när vi kör det här programmet får vi följande utdata: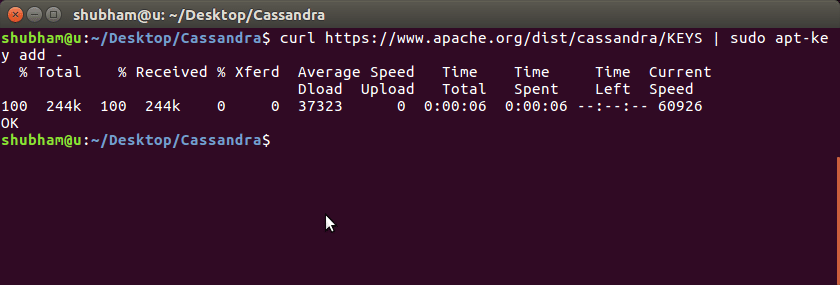
nu kan vi uppdatera apt-get-listan för Ubuntu med det här kommandot:
slutligen är vi redo att installera Cassandra på Ubuntu-maskinen:
sista kommandot kan ta några minuter baserat på Internethastigheten. Vi kan nu kontrollera om Cassandra är igång på vår maskin:
vi kommer att se att tjänsten är aktiv: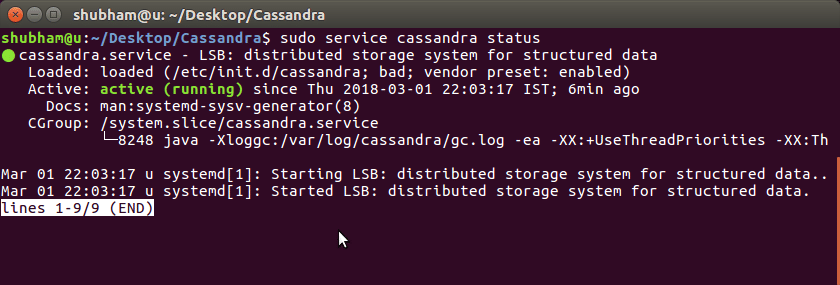
anslutning till Cassandra cluster
Cassandra startas automatiskt när installationen är klar. Cassandra är en distribuerad databas och så fungerar det inte som ett enda system utan istället fungerar det i ett kluster som kan bestå av praktiskt taget valfritt antal noder.
när Cassandra startar på vår maskin ställer den in ett kluster automatiskt med en enda nod som en del av den. Vi kan kontrollera om klustret är uppe med det här kommandot:
om vi ser UN i vår produktion betyder det att Cluster är igång: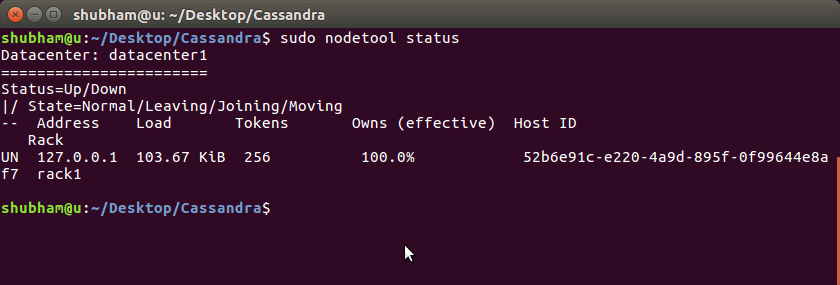
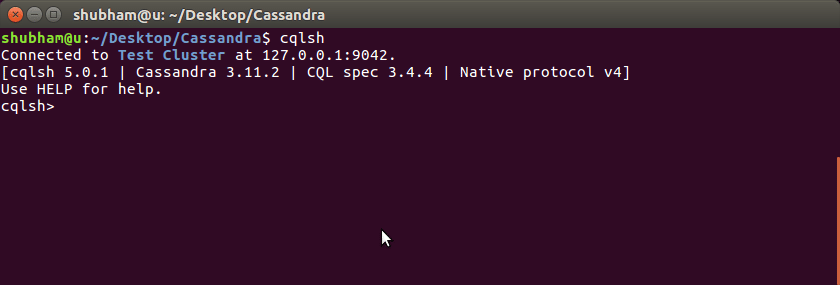
anslutning till Cassandra Database
i ett sista steg visar vi hur vi kan komma in i Cassandra-terminalen. Använd ett enkelt kommando för att börja använda Cassandra:
när du kör det här ser vi att vi nu kan köra Cassandra-kommandon på vår maskin och skapa relaterade data: