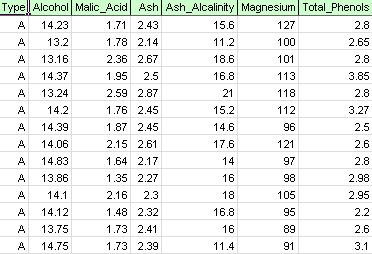
på xlminer – bandet, på fliken tillämpa din modell, Välj Hjälp-exempel, sedan prognoser/Data Mining exempel och öppna exempelfilen Wine.xlsx. Som visas i figuren nedan representerar varje rad i denna exempeldatauppsättning ett vinprov som tagits från en av tre vingårdar (A, B eller C). I det här exemplet ignoreras typvariabeln som representerar vingården, och klustringen utförs helt enkelt på grundval av egenskaperna hos vinproverna (de återstående variablerna).
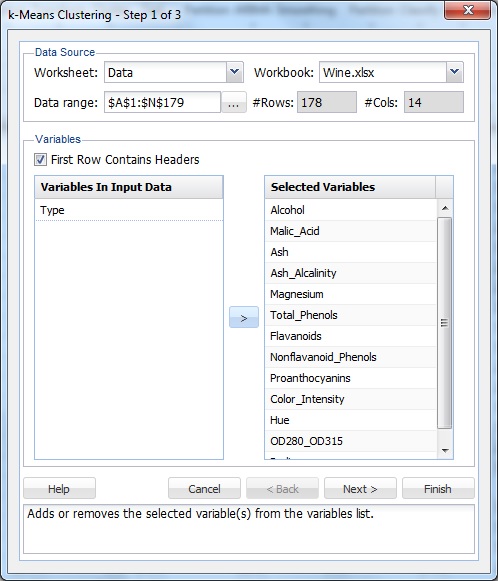
välj en cell i datamängden och sedan på xlminer – bandet, på fliken dataanalys, välj XLMiner – Cluster-k-Means Clustering för att öppna dialogrutan k-Means Clustering Steg 1 av 3.
Välj alla variabler utom typ i listan variabler och klicka sedan på knappen > för att flytta de valda variablerna till listan markerade variabler.
klicka på Nästa för att gå vidare till steg 2 av 3 dialog.
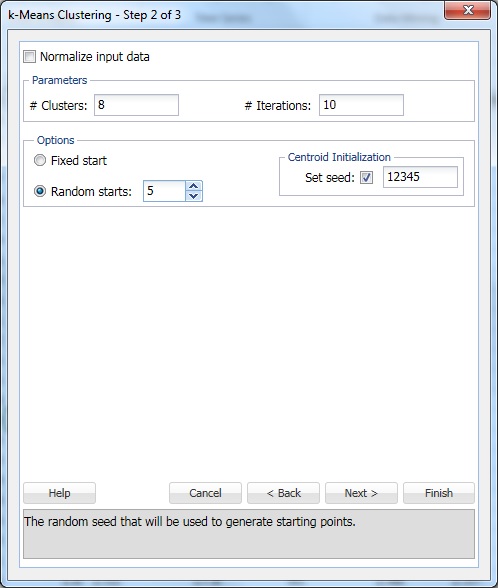
vid # kluster, ange 8. Detta är parametern k i k-means clustering-algoritmen. Antalet kluster bör vara minst 1 och högst antalet observationer -1 i dataområdet. Ställ k till flera olika värden och utvärdera utdata från varje.
lämna #iterationer vid standardinställningen 10. Värdet för det här alternativet bestämmer hur många gånger programmet startar med en initial partition och slutför klusteralgoritmen. Konfigurationen av kluster (och dataseparation) kan skilja sig från en startpartition till en annan. Programmet går igenom det angivna antalet iterationer och väljer klusterkonfigurationen som minimerar avståndsåtgärden.
Ställ in slumpmässiga startar till 5. När det här alternativet är valt börjar algoritmen bygga modellen från vilken slumpmässig punkt som helst. XLMiner genererar fem klusteruppsättningar och genererar utdata baserat på det bästa klustret.
Set seed är valt som standard. Det här alternativet initierar slumptalsgeneratorn som används för att beräkna de initiala klustercentroiderna. Att ställa in slumptalsfröet till ett icke-nollvärde (standard 12345) säkerställer att samma sekvens av slumptal används varje gång de initiala klustercentroiderna beräknas. När fröet är noll initieras slumptalsgeneratorn från systemklockan, så sekvensen av slumptal är olika varje gång centroiderna initieras. Ställ in fröet för att se successiva körningar av klustermetoden som jämförbara.
Välj alternativet normalisera indata för att normalisera data. I det här exemplet kommer data inte att normaliseras. Välj Nästa för att öppna dialogrutan steg 3 av 3.
välj Visa dataöversikt (standard) och visa avstånd från varje klustercenter( standard) och klicka sedan på Slutför.
k-betyder klustring metoden börjar med K initiala kluster som anges. Vid varje iteration tilldelas posterna till klustret med närmaste centroid eller centrum. Efter varje iteration beräknas avståndet från varje post till mitten av klustret. Dessa två steg upprepas (posttilldelningen och avståndsberäkningen) tills omfördelningen av en post resulterar i ett ökat Avståndsvärde.
när en slumpmässig start anges genererar algoritmen k-klustercentren slumpmässigt och passar datapunkterna i dessa kluster. Denna process upprepas för alla angivna slumpmässiga startar. Utgången är baserad på de kluster som uppvisar den bästa passformen.
kalkylbladet KM_Output1 infogas omedelbart till höger om datakalkylbladet. I den övre delen av kalkylbladet visas de valda alternativen.
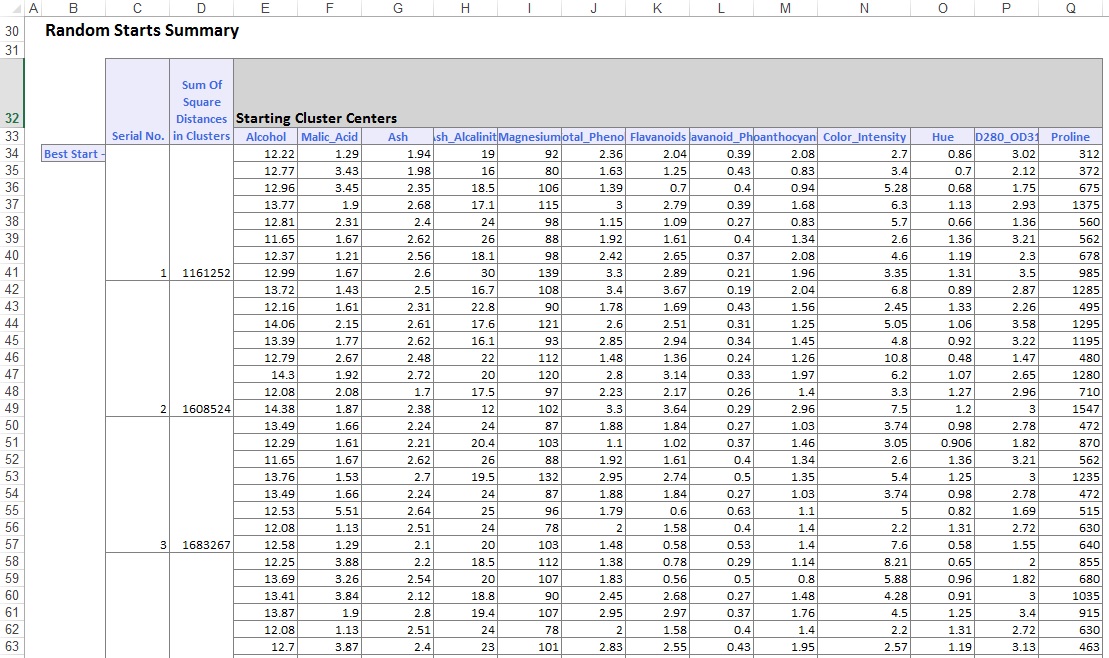
i mitten av utdatabladet har XLMiner beräknat summan av de kvadrerade avstånden och bestämt starten med den lägsta summan av Kvadratavståndet som den bästa starten (#5). När den bästa starten är bestämd genererar XLMiner den återstående utgången med den bästa starten som utgångspunkt.
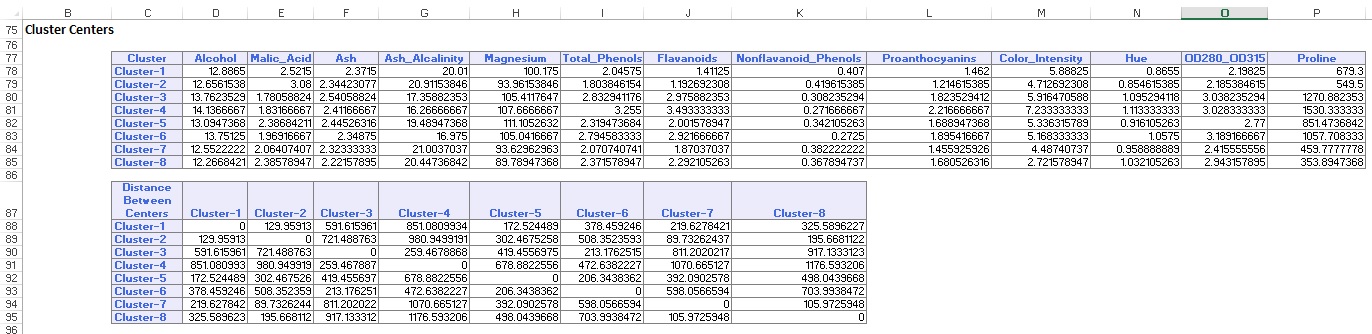
i den nedre delen av utdatabladet har XLMiner listat Klustercentren (visas nedan). Den övre rutan visar variabla värden vid Klustercentren. Kluster 8 har den högsta genomsnittliga alkohol, Total_fenoler, flavanoider, Proanthocyaniner, Color_Intensity, Hue och Proline innehåll. Jämför detta kluster med kluster 2, som har den högsta genomsnittliga Ash_Alcalinity och Nonflavanoid_Phenols.
den nedre rutan visar avståndet mellan Klustercentren. Från värdena i denna tabell bestäms att kluster 3 skiljer sig mycket från kluster 8 på grund av det höga avståndsvärdet på 1 176,59 och kluster 7 ligger nära kluster 3 med ett lågt Avståndsvärde på 89,73.
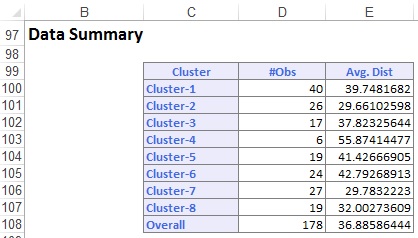
Datasammanfattningen (nedan) visar antalet poster (observationer) som ingår i varje kluster och det genomsnittliga avståndet från klustermedlemmar till mitten av varje kluster. Cluster 6 har det högsta genomsnittliga avståndet på 42,79 och innehåller 24 poster. Jämför detta kluster med kluster 2, som har det minsta genomsnittliga avståndet på 29,66 och innehåller 26 medlemmar.
klicka på kalkylbladet km_clusters1. Detta kalkylblad visar klustret som varje post tilldelas och avståndet till var och en av klustren. För den första posten är avståndet till kluster 6 det minsta avståndet på 23.205, så den första posten tilldelas kluster 6.