Tänk dig att ha ett verktyg som automatiskt kan upptäcka JPA och viloläge prestandaproblem. Hypersistence Optimizer är det verktyget!
introduktion
om du undrar varför och när du ska använda JPA eller Hibernate, kommer den här artikeln att ge dig ett svar på denna mycket vanliga fråga. Eftersom jag har sett den här frågan mycket ofta på / R / java Reddit-kanalen bestämde jag mig för att det är värt att skriva ett djupgående svar om styrkorna och svagheterna i JPA och Hibernate.
även om JPA har varit en standard sedan den först släpptes 2006, är det inte det enda sättet du kan implementera ett dataåtkomstlager med Java. Vi kommer att diskutera fördelar och nackdelar med att använda JPA eller andra populära alternativ.
varför och när JDBC skapades
1997, Java 1.1 introducerade JDBC (Java Database Connectivity) API, som var mycket revolutionerande för sin tid eftersom det erbjöd möjligheten att skriva dataåtkomstskiktet en gång med en uppsättning gränssnitt och köra den på någon relationsdatabas som implementerar JDBC API utan att behöva ändra din programkod.
JDBC API erbjöd ett Connection gränssnitt för att styra transaktionsgränserna och skapa enkla SQL-satser via Statement API eller förberedda satser som låter dig binda parametervärden via PreparedStatement API.
så, förutsatt att vi har en post databastabell och vi vill infoga 100 rader, så här kan vi uppnå detta mål med JDBC:
int postCount = 100;int batchSize = 50;try (PreparedStatement postStatement = connection.prepareStatement(""" INSERT INTO post ( id, title ) VALUES ( ?, ? ) """)) { for (int i = 1; i <= postCount; i++) { if (i % batchSize == 0) { postStatement.executeBatch(); } int index = 0; postStatement.setLong( ++index, i ); postStatement.setString( ++index, String.format( "High-Performance Java Persistence, review no. %1$d", i ) ); postStatement.addBatch(); } postStatement.executeBatch();} catch (SQLException e) { fail(e.getMessage());}
medan vi utnyttjade flerradiga textblock och försök med resursblock för att eliminera samtalet PreparedStatement close, är implementeringen fortfarande mycket detaljerad. Observera att bindningsparametrarna börjar från 1, inte 0 som du kan vara van vid från andra välkända API: er.
för att hämta de första 10 raderna kan vi behöva köra en SQL-fråga via PreparedStatement, vilket kommer att returnera en ResultSet som representerar det tabellbaserade frågeresultatet. Eftersom applikationer använder hierarkiska strukturer, som JSON eller dto: er för att representera föräldra-barnföreningar, behövde de flesta applikationer omvandla JDBC ResultSet till ett annat format i dataåtkomstskiktet, vilket illustreras av följande exempel:
int maxResults = 10;List<Post> posts = new ArrayList<>();try (PreparedStatement preparedStatement = connection.prepareStatement(""" SELECT p.id AS id, p.title AS title FROM post p ORDER BY p.id LIMIT ? """)) { preparedStatement.setInt(1, maxResults); try (ResultSet resultSet = preparedStatement.executeQuery()) { while (resultSet.next()) { int index = 0; posts.add( new Post() .setId(resultSet.getLong(++index)) .setTitle(resultSet.getString(++index)) ); } }} catch (SQLException e) { fail(e.getMessage());}
återigen är det här det trevligaste sättet vi kan skriva detta med JDBC eftersom vi använder textblock, försök med resurser och ett flytande API för att bygga Post-objekten.
ändå är JDBC API fortfarande mycket verbose och, ännu viktigare, saknar många funktioner som krävs vid implementering av ett modernt dataåtkomstlager, som:
- ett sätt att hämta objekt direkt från frågeresultatuppsättningen. Som vi har sett i exemplet ovan måste vi iterera
ReusltSetoch extrahera kolumnvärdena för att ställa in objektegenskapernaPost. - ett transparent sätt att batch uttalanden utan att behöva skriva om dataåtkomstkoden när du byter från standard icke-batching läge att använda batching.
- stöd för optimistisk låsning
- ett PAGINERINGS-API som döljer den underliggande databasspecifika Top-n-och Next-n-frågesyntaxen
varför och när Hibernate skapades
1999 släppte Sun J2EE (Java Enterprise Edition), som erbjöd ett alternativ till JDBC, kallad Entity Beans.
men eftersom Entity Beans var notoriskt långsamma, överkomplicerade och besvärliga att använda, beslutade Gavin King 2001 att skapa ett ORM-ramverk som kunde kartlägga databastabeller till POJOs (vanliga gamla Java-objekt), och det var så Hibernate föddes.
att vara lättare än Entity Beans och mindre verbose än JDBC blev Hibernate mer och mer populärt, och det blev snart det mest populära Java persistence framework och vann över JDO, iBatis, Oracle Toplinkoch Apache Cayenne.
varför och när skapades JPA?
Java EE-plattformen lärde sig från Hibernate-projektets framgång och bestämde sig för att standardisera hur Hibernate och Oracle TopLink, och det var så JPA (Java Persistence API) föddes.
JPA är bara en specifikation och kan inte användas på egen hand, och tillhandahåller endast en uppsättning gränssnitt som definierar standard persistence API, som implementeras av en JPA-leverantör, som Hibernate, EclipseLink eller OpenJPA.
när du använder JPA måste du definiera mappningen mellan en databastabell och dess associerade Java-entitetsobjekt:
@Entity@Table(name = "post")public class Post { @Id private Long id; private String title; public Long getId() { return id; } public Post setId(Long id) { this.id = id; return this; } public String getTitle() { return title; } public Post setTitle(String title) { this.title = title; return this; }}
efteråt kan vi skriva om det föregående exemplet som sparade 100 post poster ser ut så här:
for (long i = 1; i <= postCount; i++) { entityManager.persist( new Post() .setId(i) .setTitle( String.format( "High-Performance Java Persistence, review no. %1$d", i ) ) );}
för att aktivera JDBC-satsinsatser måste vi bara tillhandahålla en enda konfigurationsegenskap:
<property name="hibernate.jdbc.batch_size" value="50"/>
när den här egenskapen tillhandahålls kan Hibernate automatiskt växla från icke-dosering till dosering utan att behöva ändra dataåtkomstkod.
och för att hämta de första 10 post raderna kan vi utföra följande JPQL-fråga:
int maxResults = 10;List<Post> posts = entityManager.createQuery(""" select p from post p order by p.id """, Post.class).setMaxResults(maxResults).getResultList();
om du jämför detta med JDBC-versionen ser du att JPA är mycket lättare att använda.
fördelarna och nackdelarna med att använda JPA och Hibernate
JPA, i allmänhet, och Hibernate, i synnerhet, erbjuder många fördelar.
- du kan hämta enheter eller skrivfel. Du kan även hämta hierarkisk förälder-barn dto projektion.
- du kan aktivera JDBC-dosering utan att ändra dataåtkomstkoden.
- du har stöd för optimistisk låsning.
- du har en pessimistisk låsabstraktion som är oberoende av den underliggande databasspecifika syntaxen så att du kan skaffa ett Läs-och SKRIVLÅS eller till och med ett HOPPLÅS.
- du har ett databasoberoende paginerings-API.
- du kan ange en
Listav värden till en in query-klausul, som förklaras i den här artikeln. - du kan använda en starkt konsekvent cachningslösning som låter dig ladda den primära noden, som för rea-write-transaktioner endast kan kallas vertikalt.
- du har inbyggt stöd för granskningsloggning via Hibernate Envers.
- du har inbyggt stöd för multitenancy.
- du kan skapa ett initialt schemaskript från entity mappings med Hibernate hbm2ddl-verktyget, som du kan leverera till ett automatiskt schemamigreringsverktyg, som Flyway.
- inte bara att du har friheten att utföra någon inbyggd SQL-fråga, men du kan använda SqlResultSetMapping för att omvandla JDBC
ResultSettill JPA-enheter eller dto: er.
nackdelarna med att använda JPA och viloläge är följande:
- samtidigt komma igång med JPA är mycket lätt, bli en expert kräver en betydande tid investering eftersom, förutom att läsa sin manual, du fortfarande måste lära sig hur databassystem fungerar, SQL-standarden samt den specifika SQL smak som används av ditt projekt relation databas.
- det finns några mindre intuitiva beteenden som kan överraska nybörjare, som spolningsoperationsordningen.
- kriterierna API är ganska verbose, så du måste använda ett verktyg som Codota för att skriva dynamiska frågor lättare.
den övergripande gemenskapen och populära integrationer
JPA och Hibernate är extremt populära. Enligt 2018 Java ecosystem report av Snyk används Hibernate av 54% av alla Java-utvecklare som interagerar med en relationsdatabas.
detta resultat kan backas upp av Google Trends. Om vi till exempel jämför Google Trends of JPA jämfört med dess huvudkonkurrenter (t.ex. MyBatis, QueryDSL och jOOQ), kan vi se att JPA är många gånger mer populärt och inte visar några tecken på att förlora sin dominerande marknadsandel.

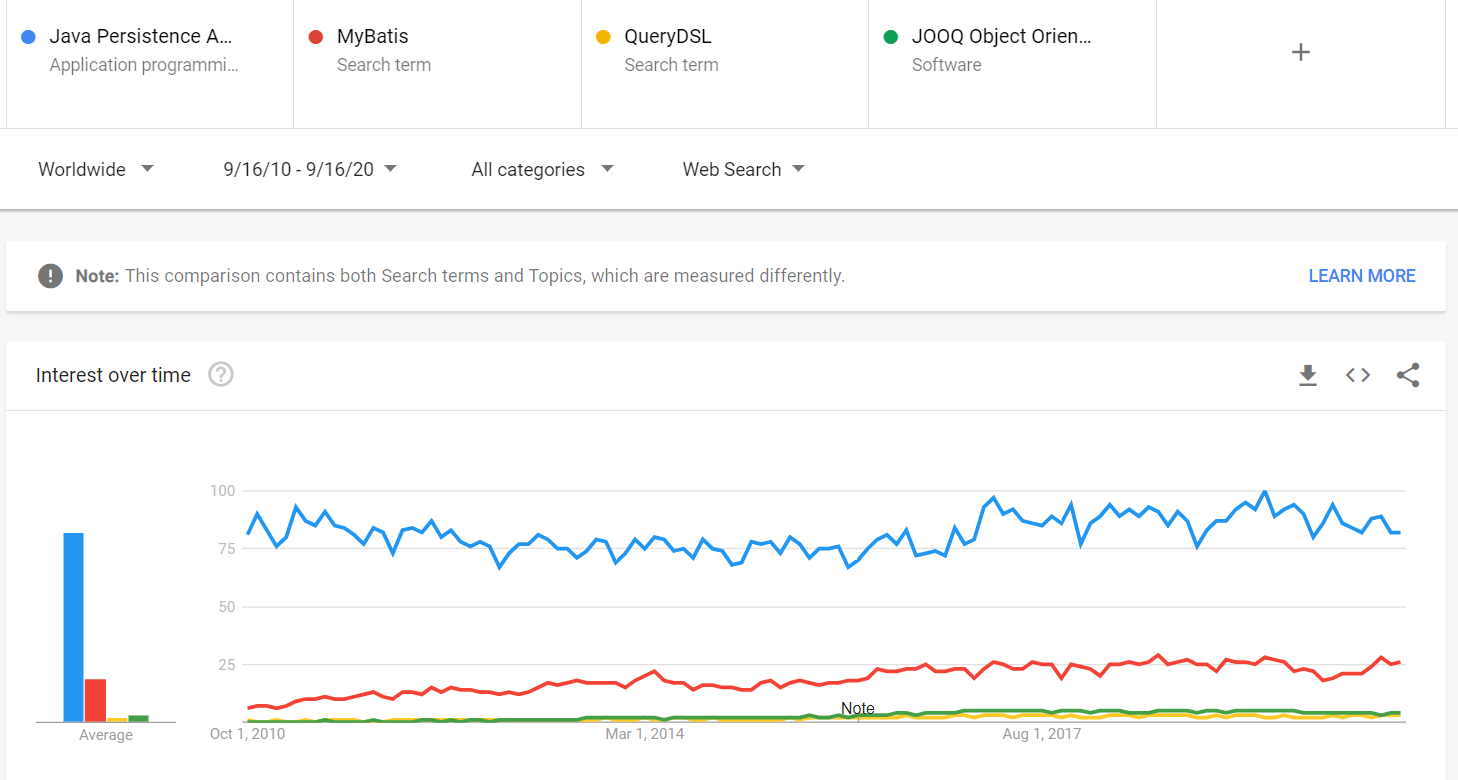
att vara så populär ger många fördelar, som:
- Spring Data JPA integration fungerar som en charm. Faktum är att en av de största anledningarna till att JPA och Hibernate är så populära är att Spring Boot använder Spring Data JPA, som i sin tur använder Hibernate bakom kulisserna.
- om du har några problem finns det en god chans att dessa 30k Hibernate-relaterade StackOverflow-svar och 16k JPA-relaterade StackOverflow-svar ger dig en lösning.
- det finns 73K viloläge tutorials tillgängliga. Only my site alone erbjuder över 250 JPA och Hibernate tutorials som lär dig hur du får ut det mesta av JPA och Hibernate.
- det finns många videokurser du kan använda också, som min högpresterande Java Persistence-videokurs.
- det finns över 300 böcker om Hibernate på Amazon, varav en är min högpresterande Java Persistence book också.
JPA-alternativ
en av de största sakerna med Java-ekosystemet är överflödet av högkvalitativa ramar. Om JPA och Hibernate inte passar bra för ditt användningsfall kan du använda något av följande ramverk:
- MyBatis, som är en mycket lätt SQL query mapper framework.
- QueryDSL, som låter dig bygga SQL -, JPA -, Lucene-och MongoDB-frågor dynamiskt.
- jOOQ, som tillhandahåller en Java metamodel för de underliggande tabellerna, lagrade procedurer och funktioner och låter dig bygga en SQL-fråga dynamiskt med en mycket intuitiv DSL och på ett typsäkert sätt.
så använd det som fungerar bäst för dig.
online Workshops
om du gillade den här artikeln, Jag slår vad om att du kommer att älska min kommande 4-dagars x 4 timmar högpresterande Java Persistens Online Workshop

slutsats
i den här artikeln såg vi varför JPA skapades och när du ska använda den. Medan JPA ger många fördelar, har du många andra högkvalitativa alternativ att använda om JPA och Hibernate inte fungerar bäst för dina nuvarande applikationskrav.
och ibland, som jag förklarade i detta gratisprov av min högpresterande Java-Persistensbok, behöver du inte ens välja mellan JPA eller andra ramar. Du kan enkelt kombinera JPA med ett ramverk som jOOQ för att få det bästa av två världar.



