vi begynner med å se på dual-form lineær / ridge regresjon, før du viser hvordan du kernelize det. I å forklare sistnevnte, vil vi se hva kjerner er, og hva ‘kernel trick’ er.
Dual-Form Ridge Regresjon
Lineær regresjon er vanligvis gitt i den primære form som en lineær kombinasjon av kolonner (funksjoner). Imidlertid eksisterer det en annen, dobbel form hvor den er en lineær kombinasjon av det indre produktet av et nytt datum (som vi utfører inferens på) med hver av treningsdataene.
vi vurderer tilfelle av ridge regresjon (L2 regularisert lineær regresjon), husk at grunnleggende lineær regresjon tilsvarer tilfellet der \(\lambda = 0\). Da er formlene for ridge regresjon, hvor \(X\) og\ (Y\) refererer til\ (n \ ganger m\) treningsdata og \(x^\prime,y^\prime\) et nytt tilfelle som skal estimeres, er:
\ \ \ \
Hvor \ (\langle X_i, x^ \ prime \ rangle\) er det indre / punktproduktet, så \ (\langle X_i,x^\prime\rangle = X^T_i x^\prime = \sum_j^m X_{i,j} x^\prime_j\).
den doble formen viser at lineær / ridge regresjon også kan forstås som å gi et estimat av en vektet sum av det indre produktet av en ny sak med hver av treningssakene.
det betyr at vi kan gjøre lineær regresjon selv når det er flere kolonner enn rader, selv om betydningen av dette kan overvurderes siden (i) vi kan gjøre dette uansett ved bruk Av l2 regularisering siden dette alltid gjør \(X ^ TX\) matrisen inverterbar; og (ii) \(XX^T\) matrisen kan ofte kreve l2 regularisering uansett for å sikre numerisk stabilitet for inversjonen. Det tillater oss også å se lineær regresjon som mye mer av en sekvensiell læringsprosess, hvor hvert ekstra datum i treningsdataene bringer noe nytt.
Viktigst for vårt formål, men den doble formen har den interessante egenskapen: funksjonsvektorer forekommer i ligningene bare i indre produkter. Dette gjelder selv i definisjonen av \(\alpha\), da \(XX^T\) produserer matrisen som svarer til de indre produktene til hvert par funksjonsvektorer i treningsdataene. Vi vil se betydningen av dette når vi fortsetter.
Til Side: Interesserte studenter kan se hvordan dual form ble avledet i Avledning Av Dual Form dokument tilgjengelig i nedlastingsseksjonen på slutten av denne artikkelen.
Ikke-Lineær Dual Ridge Regresjon
Vi kan slå vår dual form ridge regresjon til en ikke-lineær modell ved standardmetoden for å bruke en ikke-lineær funksjonstransformasjoner \(\phi\):
\ \
Kjernefunksjoner
en kjernefunksjon, \(k: \ mathcal x \ times \ mathcal x \ to \ mathbb{R}\), er en funksjon som er symmetrisk – \(K (x_1, x_2)=K (x_2,x_1)\) – og positiv bestemt (se til side for en formell definisjon). Positiv-definiteness brukes i matematikken som rettferdiggjør bruken av kjerner. Men uten betydelig matematisk kunnskap er definisjonen ikke intuitivt lysende. Så i stedet for å forsøke å forstå kjerner fra definisjonen av positiv-definiteness, vil vi introdusere dem med en rekke eksempler.
før vi gjør dette, bemerker vi at selv om kjerner er to-argumentfunksjoner, er det vanlig å tenke på dem som lokalisert ved deres første argument, og å være en funksjon av deres andre. I følge denne tolkningen vil du se notasjon som \(K_x (y)\), som tilsvarer \(K (x,y)\) . Spesielt vil vi ofte tenke på kjerner som enkeltargumentfunksjoner ‘plassert’ på datapunkter (funksjonsvektorer) i treningsdataene våre. Noen ganger vil du lese av oss ‘slippe’ kjerner på datapunkter. Så hvis vi har en funksjonsvektor \(x_i\), vil vi slippe en kjerne på den, som fører til funksjonen \(K_{x_i} (x)\) plassert på \(x_i\) og tilsvarende \(K (x_i, x)\).
vi merker også at kjerner ofte er spesifisert som medlemmer av parametriske familier. Eksempler på slike kjernefamilier inkluderer:
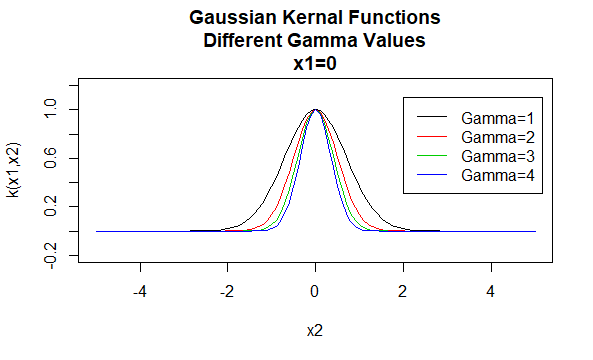
Gaussiske Kjerner
Gaussiske kjerner er et eksempel på radial basisfunksjonskjerner og kalles noen ganger radial basiskjerner. Verdien av en radial basisfunksjonskjerne avhenger bare av avstanden mellom argumentvektorene, i stedet for deres plassering. Slike kjerner kalles også stasjonære.
Parametere: \(\gamma\)
Ligningsform: \(K (X_1, X_2)=e^{- \gamma \ / X_1-X_2 \|^2}\)
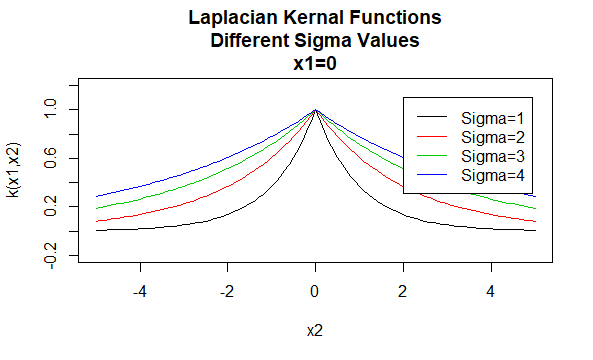
Laplacian Kjerner
Laplacian kjerner er også radial basis funksjoner.
Parametere: \(\sigma\)
Ligningsform: \(K(X_1,X_2)=e^{-\frac{\| X_1 – X_2 \|}{\sigma}}\)
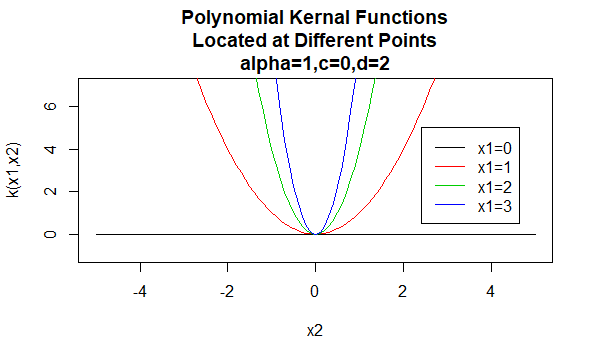
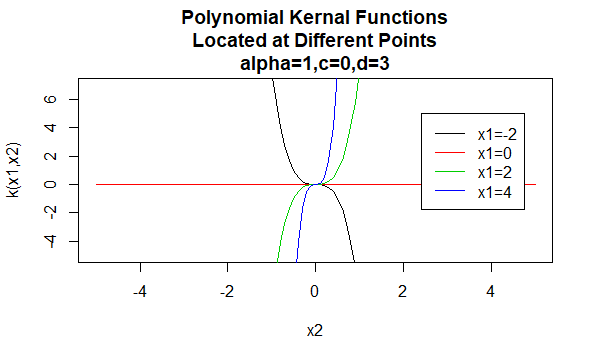
Polynomkjerner
Polynomkjerner er et eksempel på ikke-stasjonære kjerner. Så disse kjernene vil tildele forskjellige verdier til par punkter som deler samme avstand, basert på deres verdier. Parameterverdier må være ikke-negative for å sikre at disse kjernene er positive bestemte.
Parametere: \(\alpha, c, d\)
Ligningsform: \(K (X_1, X_2)=(\alpha X_1^TX_2 +c)^d\)
Angi bestemte verdier for parametrene til en kjernefamilie resulterer i en kjernefunksjon. Nedenfor er eksempler på kjernefunksjoner fra de ovennevnte familiene med bestemte parameterverdier plassert på forskjellige punkter (dvs.den plottet grafen er en funksjon av det andre argumentet, med det første argumentet satt til en bestemt verdi).
Til Side: Interesserte studenter kan se definisjonen av positiv definitet for kjerner i Kjernene og Positiv Definitetsdokumentet som er tilgjengelig i nedlastingsdelen på slutten av denne artikkelen.
Kernel Trick
betydningen av kjernefunksjoner kommer fra en veldig spesiell egenskap: Hver positiv bestemt kjerne, \(K\) er relatert til et matematisk rom, \(\mathcal{H}_K\), (kjent som den reproduserende kjernen Hilbert space (rkhs) av kjernen) slik at bruk av \(K\) til to funksjonsvektorer, \(X_1,X_2\) tilsvarer å projisere disse funksjonsvektorene inn i \(\mathcal{H}_K\) ved en projeksjonsfunksjon, \(\phi\) og ta deres indre produkt der:
\
RKHSs forbundet med kjerner er vanligvis høy-dimensjonale. For noen kjerner, Som Gaussiske familiekjerner, er de uendelige dimensjonale.
ovenstående er grunnlaget for det berømte ‘kernel-trikset’: hvis inngangsfunksjonene bare er involvert i ligningen til en statistisk modell i form av indre produkter, kan vi erstatte de indre produktene i ligningen med kall til kjernefunksjonen, og resultatet er som om vi hadde projisert inngangsfunksjonene til et høyere dimensjonalt rom (dvs.utført en funksjonstransformasjon som fører til et stort antall latente variable funksjoner) og tatt deres indre produkt der. Men vi trenger aldri å utføre selve projeksjonen.
I maskinlæringsterminologi er RKHS knyttet til kjernen kjent som funksjonsområdet, i motsetning til inngangsområdet. Via kernel trick projiserer vi implisitt inngangsfunksjonene i denne funksjonen og tar sitt indre produkt der.
Kernel Regresjon
dette fører til teknikken kjent som kernel regresjon. Det er rett og slett en anvendelse av kjernen trikset til dual form av ridge regresjon. For å lette introduserer vi ideen Om Kjernen, Eller Gram, matrise, \(K\), slik at \(K_{i, j}=k (X_i,X_j)\). Da kan vi skrive ligningene for kjerneregresjon som:
\ \
hvor \(k\) er noen positiv-bestemt kjernefunksjon.
Representerteoremet
Vurder optimaliseringsproblemet vi søker å løse når Vi utfører l2 regularisering for en modell av en eller annen form, \(f\):
\
når du utfører kjerneregresjon med kernel \(k\), er det et viktig resultat av regulariseringsteori at minimisatoren av ligningen ovenfor vil være av formen:
\
med \(\alpha\) beregnet som beskrevet ovenfor.
Dette er rettferdig lionized Repressenter Theorem. I ord står det at minimeringen av optimaliseringsproblemet for lineær regresjon i det implisitte funksjonsområdet oppnådd av en bestemt kjerne (og dermed minimeringen av det ikke-lineære kjerneregresjonsproblemet) vil bli gitt av en vektet sum av kjerner ‘plassert’ ved hver funksjonsvektor.
Det er mye mer å si om dette emnet. Vi kan til og med finne Ut Hvilken Grønn funksjon (hvorav kjerner er en delmengde) vil minimere bestemte regulariseringsspesifikasjoner, for Eksempel L2 regularisering, men også noen straff basert på en lineær differensialoperatør. Dette forholdet mellom kjerner og optimale løsninger På tikhonov regulariseringsproblemer er en prinsipiell årsak til betydningen av kjernemetoder i maskinlæring. Men matematikken her er utenfor dette kurset, og interesserte avanserte studenter refereres til kapittel syv Av Haykins Nevrale Nettverk og Læringsmaskiner.
dette gir oss en matematisk begrunnelse for å bruke kjerneregresjon i tilfeller der det er mulig å gjøre det. Det er vanligvis ikke mulig å utarbeide den optimale kjernen som skal brukes – det krever å vite den optimale lineære differensialoperatøren som skal brukes til regulariseringsstraffen. Funksjonene vi bør projisere på for å optimalisere bestemte regulariseringsstraffer er beregnet, og vi vet for eksempel at thin plate spline kernel er optimal For l2 regularisering. På nedsiden, siden vi må beregne Grammatrisen, skalerer kjerneregresjon ikke bra – for store datasett som vender seg til nevrale nettverk er en bedre ide.